 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Versatile Framework for Analyzing Galaxy Image Data by Implanting Human-in-the-loop on a Large Vision Model
May 17, 2024The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
Neural Network Layer Matrix Decomposition reveals Latent Manifold Encoding and Memory Capacity
Sep 12, 2023We prove the converse of the universal approximation theorem, i.e. a neural network (NN) encoding theorem which shows that for every stably converged NN of continuous activation functions, its weight matrix actually encodes a continuous function that approximates its training dataset to within a finite margin of error over a bounded domain. We further show that using the Eckart-Young theorem for truncated singular value decomposition of the weight matrix for every NN layer, we can illuminate the nature of the latent space manifold of the training dataset encoded and represented by every NN layer, and the geometric nature of the mathematical operations performed by each NN layer. Our results have implications for understanding how NNs break the curse of dimensionality by harnessing memory capacity for expressivity, and that the two are complementary. This Layer Matrix Decomposition (LMD) further suggests a close relationship between eigen-decomposition of NN layers and the latest advances in conceptualizations of Hopfield networks and Transformer NN models.
Study of Subjective and Objective Quality Assessment of Mobile Cloud Gaming Videos
May 26, 2023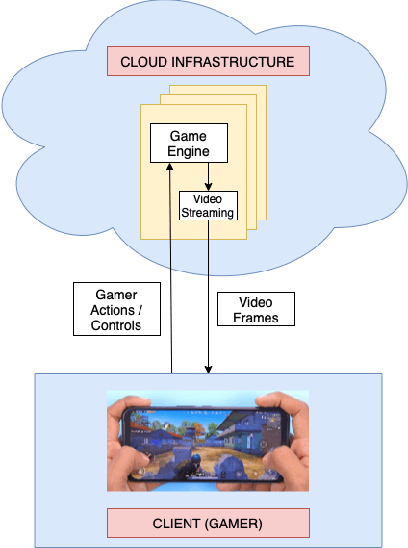
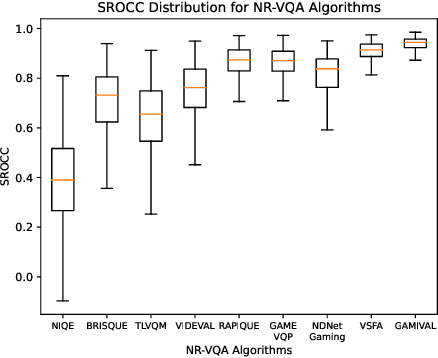
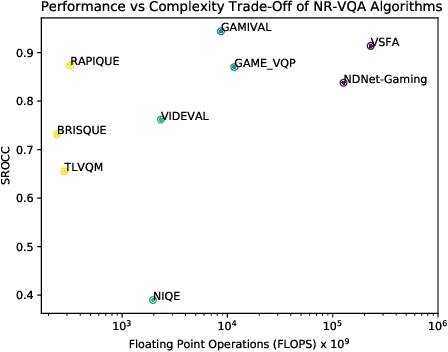
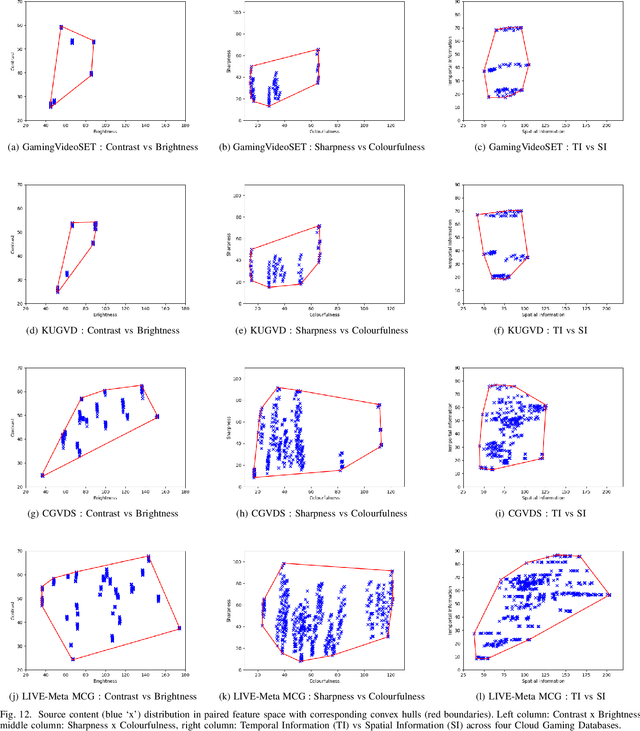
We present the outcomes of a recent large-scale subjective study of Mobile Cloud Gaming Video Quality Assessment (MCG-VQA) on a diverse set of gaming videos. Rapid advancements in cloud services, faster video encoding technologies, and increased access to high-speed, low-latency wireless internet have all contributed to the exponential growth of the Mobile Cloud Gaming industry. Consequently, the development of methods to assess the quality of real-time video feeds to end-users of cloud gaming platforms has become increasingly important. However, due to the lack of a large-scale public Mobile Cloud Gaming Video dataset containing a diverse set of distorted videos with corresponding subjective scores, there has been limited work on the development of MCG-VQA models. Towards accelerating progress towards these goals, we created a new dataset, named the LIVE-Meta Mobile Cloud Gaming (LIVE-Meta-MCG) video quality database, composed of 600 landscape and portrait gaming videos, on which we collected 14,400 subjective quality ratings from an in-lab subjective study. Additionally, to demonstrate the usefulness of the new resource, we benchmarked multiple state-of-the-art VQA algorithms on the database. The new database will be made publicly available on our website: \url{https://live.ece.utexas.edu/research/LIVE-Meta-Mobile-Cloud-Gaming/index.html}
Deep Learning Applications Based on WISE Infrared Data: Classification of Stars, Galaxies and Quasars
May 17, 2023The Wide-field Infrared Survey Explorer (WISE) has detected hundreds of millions of sources over the entire sky. However, classifying them reliably is a great challenge due to degeneracies in WISE multicolor space and low detection levels in its two longest-wavelength bandpasses. In this paper, the deep learning classification network, IICnet (Infrared Image Classification network), is designed to classify sources from WISE images to achieve a more accurate classification goal. IICnet shows good ability on the feature extraction of the WISE sources. Experiments demonstrates that the classification results of IICnet are superior to some other methods; it has obtained 96.2% accuracy for galaxies, 97.9% accuracy for quasars, and 96.4% accuracy for stars, and the Area Under Curve (AUC) of the IICnet classifier can reach more than 99%. In addition, the superiority of IICnet in processing infrared images has been demonstrated in the comparisons with VGG16, GoogleNet, ResNet34, MobileNet, EfficientNetV2, and RepVGG-fewer parameters and faster inference. The above proves that IICnet is an effective method to classify infrared sources.
GAMIVAL: Video Quality Prediction on Mobile Cloud Gaming Content
May 12, 2023The mobile cloud gaming industry has been rapidly growing over the last decade. When streaming gaming videos are transmitted to customers' client devices from cloud servers, algorithms that can monitor distorted video quality without having any reference video available are desirable tools. However, creating No-Reference Video Quality Assessment (NR VQA) models that can accurately predict the quality of streaming gaming videos rendered by computer graphics engines is a challenging problem, since gaming content generally differs statistically from naturalistic videos, often lacks detail, and contains many smooth regions. Until recently, the problem has been further complicated by the lack of adequate subjective quality databases of mobile gaming content. We have created a new gaming-specific NR VQA model called the Gaming Video Quality Evaluator (GAMIVAL), which combines and leverages the advantages of spatial and temporal gaming distorted scene statistics models, a neural noise model, and deep semantic features. Using a support vector regression (SVR) as a regressor, GAMIVAL achieves superior performance on the new LIVE-Meta Mobile Cloud Gaming (LIVE-Meta MCG) video quality database.
* Accepted to IEEE SPL 2023. The implementation of GAMIVAL has been made available online: https://github.com/lskdream/GAMIVAL