 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Perceptual Representations for Gaming NR-VQA with Multi-Task FR Signals
Feb 12, 2026No-reference video quality assessment (NR-VQA) for gaming videos is challenging due to limited human-rated datasets and unique content characteristics including fast motion, stylized graphics, and compression artifacts. We present MTL-VQA, a multi-task learning framework that uses full-reference metrics as supervisory signals to learn perceptually meaningful features without human labels for pretraining. By jointly optimizing multiple full-reference (FR) objectives with adaptive task weighting, our approach learns shared representations that transfer effectively to NR-VQA. Experiments on gaming video datasets show MTL-VQA achieves performance competitive with state-of-the-art NR-VQA methods across both MOS-supervised and label-efficient/self-supervised settings.
TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Models
Jan 30, 2026Masked Diffusion Models (MDMs) have emerged as a promising non-autoregressive paradigm for generative tasks, offering parallel decoding and bidirectional context utilization. However, current sampling methods rely on simple confidence-based heuristics that ignore the long-term impact of local decisions, leading to trajectory lock-in where early hallucinations cascade into global incoherence. While search-based methods mitigate this, they incur prohibitive computational costs ($O(K)$ forward passes per step). In this work, we propose Backward-on-Entropy (BoE) Steering, a gradient-guided inference framework that approximates infinite-horizon lookahead via a single backward pass. We formally derive the Token Influence Score (TIS) from a first-order expansion of the trajectory cost functional, proving that the gradient of future entropy with respect to input embeddings serves as an optimal control signal for minimizing uncertainty. To ensure scalability, we introduce \texttt{ActiveQueryAttention}, a sparse adjoint primitive that exploits the structure of the masking objective to reduce backward pass complexity. BoE achieves a superior Pareto frontier for inference-time scaling compared to existing unmasking methods, demonstrating that gradient-guided steering offers a mathematically principled and efficient path to robust non-autoregressive generation. We will release the code.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

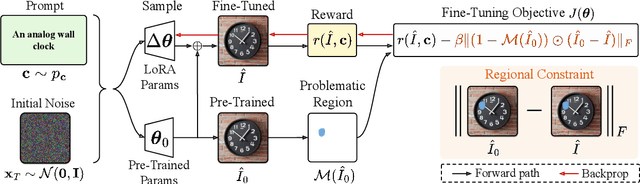
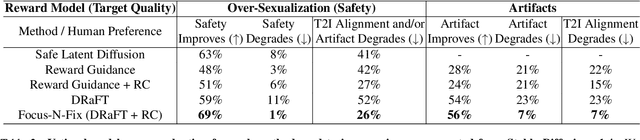
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Exploring Explainability in Video Action Recognition
Apr 13, 2024



Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
HIDRO-VQA: High Dynamic Range Oracle for Video Quality Assessment
Nov 18, 2023We introduce HIDRO-VQA, a no-reference (NR) video quality assessment model designed to provide precise quality evaluations of High Dynamic Range (HDR) videos. HDR videos exhibit a broader spectrum of luminance, detail, and color than Standard Dynamic Range (SDR) videos. As HDR content becomes increasingly popular, there is a growing demand for video quality assessment (VQA) algorithms that effectively address distortions unique to HDR content. To address this challenge, we propose a self-supervised contrastive fine-tuning approach to transfer quality-aware features from the SDR to the HDR domain, utilizing unlabeled HDR videos. Our findings demonstrate that self-supervised pre-trained neural networks on SDR content can be further fine-tuned in a self-supervised setting using limited unlabeled HDR videos to achieve state-of-the-art performance on the only publicly available VQA database for HDR content, the LIVE-HDR VQA database. Moreover, our algorithm can be extended to the Full Reference VQA setting, also achieving state-of-the-art performance. Our code is available publicly at https://github.com/avinabsaha/HIDRO-VQA.
Study of Subjective and Objective Quality Assessment of Mobile Cloud Gaming Videos
May 26, 2023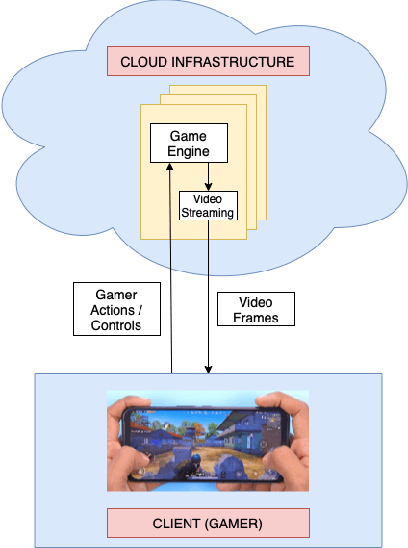
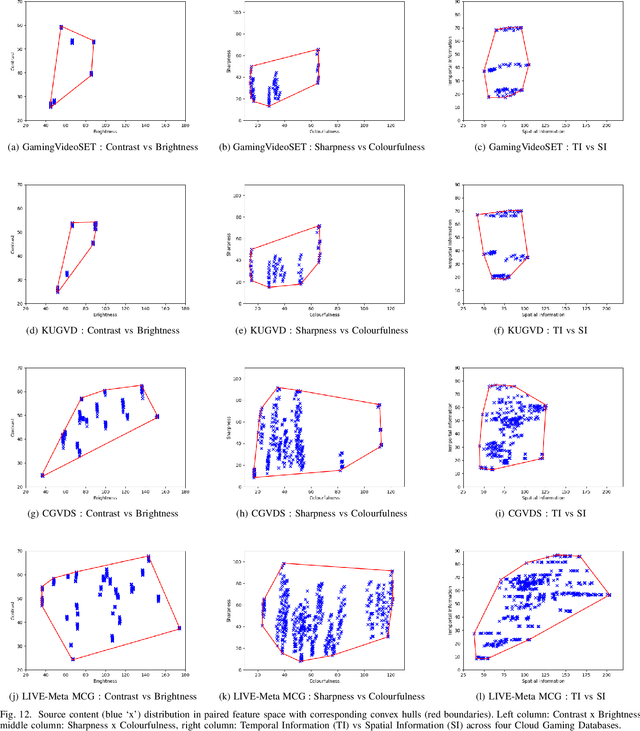
We present the outcomes of a recent large-scale subjective study of Mobile Cloud Gaming Video Quality Assessment (MCG-VQA) on a diverse set of gaming videos. Rapid advancements in cloud services, faster video encoding technologies, and increased access to high-speed, low-latency wireless internet have all contributed to the exponential growth of the Mobile Cloud Gaming industry. Consequently, the development of methods to assess the quality of real-time video feeds to end-users of cloud gaming platforms has become increasingly important. However, due to the lack of a large-scale public Mobile Cloud Gaming Video dataset containing a diverse set of distorted videos with corresponding subjective scores, there has been limited work on the development of MCG-VQA models. Towards accelerating progress towards these goals, we created a new dataset, named the LIVE-Meta Mobile Cloud Gaming (LIVE-Meta-MCG) video quality database, composed of 600 landscape and portrait gaming videos, on which we collected 14,400 subjective quality ratings from an in-lab subjective study. Additionally, to demonstrate the usefulness of the new resource, we benchmarked multiple state-of-the-art VQA algorithms on the database. The new database will be made publicly available on our website: \url{https://live.ece.utexas.edu/research/LIVE-Meta-Mobile-Cloud-Gaming/index.html}
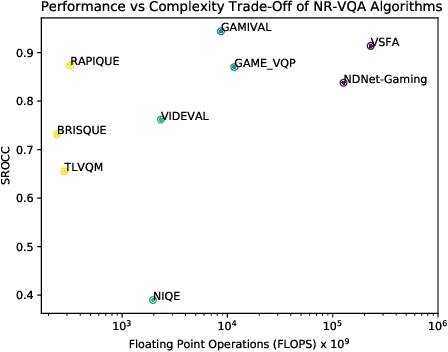
GAMIVAL: Video Quality Prediction on Mobile Cloud Gaming Content
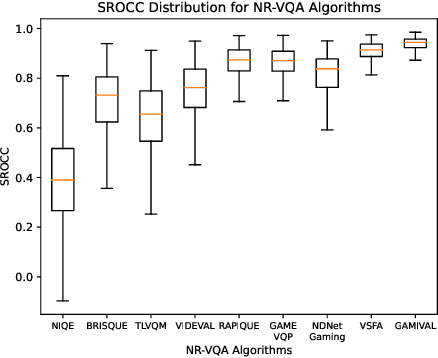
May 12, 2023The mobile cloud gaming industry has been rapidly growing over the last decade. When streaming gaming videos are transmitted to customers' client devices from cloud servers, algorithms that can monitor distorted video quality without having any reference video available are desirable tools. However, creating No-Reference Video Quality Assessment (NR VQA) models that can accurately predict the quality of streaming gaming videos rendered by computer graphics engines is a challenging problem, since gaming content generally differs statistically from naturalistic videos, often lacks detail, and contains many smooth regions. Until recently, the problem has been further complicated by the lack of adequate subjective quality databases of mobile gaming content. We have created a new gaming-specific NR VQA model called the Gaming Video Quality Evaluator (GAMIVAL), which combines and leverages the advantages of spatial and temporal gaming distorted scene statistics models, a neural noise model, and deep semantic features. Using a support vector regression (SVR) as a regressor, GAMIVAL achieves superior performance on the new LIVE-Meta Mobile Cloud Gaming (LIVE-Meta MCG) video quality database.
* Accepted to IEEE SPL 2023. The implementation of GAMIVAL has been made available online: https://github.com/lskdream/GAMIVAL
Re-IQA: Unsupervised Learning for Image Quality Assessment in the Wild
Apr 02, 2023



Automatic Perceptual Image Quality Assessment is a challenging problem that impacts billions of internet, and social media users daily. To advance research in this field, we propose a Mixture of Experts approach to train two separate encoders to learn high-level content and low-level image quality features in an unsupervised setting. The unique novelty of our approach is its ability to generate low-level representations of image quality that are complementary to high-level features representing image content. We refer to the framework used to train the two encoders as Re-IQA. For Image Quality Assessment in the Wild, we deploy the complementary low and high-level image representations obtained from the Re-IQA framework to train a linear regression model, which is used to map the image representations to the ground truth quality scores, refer Figure 1. Our method achieves state-of-the-art performance on multiple large-scale image quality assessment databases containing both real and synthetic distortions, demonstrating how deep neural networks can be trained in an unsupervised setting to produce perceptually relevant representations. We conclude from our experiments that the low and high-level features obtained are indeed complementary and positively impact the performance of the linear regressor. A public release of all the codes associated with this work will be made available on GitHub.