 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdditive Control Variates Dominate Self-Normalisation in Off-Policy Evaluation
Feb 16, 2026Off-policy evaluation (OPE) is essential for assessing ranking and recommendation systems without costly online interventions. Self-Normalised Inverse Propensity Scoring (SNIPS) is a standard tool for variance reduction in OPE, leveraging a multiplicative control variate. Recent advances in off-policy learning suggest that additive control variates (baseline corrections) may offer superior performance, yet theoretical guarantees for evaluation are lacking. This paper provides a definitive answer: we prove that $β^\star$-IPS, an estimator with an optimal additive baseline, asymptotically dominates SNIPS in Mean Squared Error. By analytically decomposing the variance gap, we show that SNIPS is asymptotically equivalent to using a specific -- but generally sub-optimal -- additive baseline. Our results theoretically justify shifting from self-normalisation to optimal baseline corrections for both ranking and recommendation.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
AskDoc -- Identifying Hidden Healthcare Disparities
Sep 11, 2025The objective of this study is to understand the online Ask the Doctor services medical advice on internet platforms via AskDoc, a Reddit community that serves as a public AtD platform and study if platforms mirror existing hurdles and partiality in healthcare across various demographic groups. We downloaded data from January 2020 to May 2022 from AskDoc -- a subreddit, and created regular expressions to identify self-reported demographics (Gender, Race, and Age) from the posts, and performed statistical analysis to understand the interaction between peers and physicians with the posters. Half of the posts did not receive comments from peers or physicians. At least 90% of the people disclose their gender and age, and 80% of the people do not disclose their race. It was observed that the subreddit is dominated by adult (age group 20-39) white males. Some disparities were observed in the engagement between the users and the posters with certain demographics. Beyond the confines of clinics and hospitals, social media could bring patients and providers closer together, however, as observed, current physicians participation is low compared to posters.
Towards Two-Stage Counterfactual Learning to Rank
Jun 25, 2025
Counterfactual learning to rank (CLTR) aims to learn a ranking policy from user interactions while correcting for the inherent biases in interaction data, such as position bias. Existing CLTR methods assume a single ranking policy that selects top-K ranking from the entire document candidate set. In real-world applications, the candidate document set is on the order of millions, making a single-stage ranking policy impractical. In order to scale to millions of documents, real-world ranking systems are designed in a two-stage fashion, with a candidate generator followed by a ranker. The existing CLTR method for a two-stage offline ranking system only considers the top-1 ranking set-up and only focuses on training the candidate generator, with the ranker fixed. A CLTR method for training both the ranker and candidate generator jointly is missing from the existing literature. In this paper, we propose a two-stage CLTR estimator that considers the interaction between the two stages and estimates the joint value of the two policies offline. In addition, we propose a novel joint optimization method to train the candidate and ranker policies, respectively. To the best of our knowledge, we are the first to propose a CLTR estimator and learning method for two-stage ranking. Experimental results on a semi-synthetic benchmark demonstrate the effectiveness of the proposed joint CLTR method over baselines.
Meta-reinforcement learning with minimum attention
May 22, 2025Minimum attention applies the least action principle in the changes of control concerning state and time, first proposed by Brockett. The involved regularization is highly relevant in emulating biological control, such as motor learning. We apply minimum attention in reinforcement learning (RL) as part of the rewards and investigate its connection to meta-learning and stabilization. Specifically, model-based meta-learning with minimum attention is explored in high-dimensional nonlinear dynamics. Ensemble-based model learning and gradient-based meta-policy learning are alternately performed. Empirically, we show that the minimum attention does show outperforming competence in comparison to the state-of-the-art algorithms in model-free and model-based RL, i.e., fast adaptation in few shots and variance reduction from the perturbations of the model and environment. Furthermore, the minimum attention demonstrates the improvement in energy efficiency.
A Benchmark for End-to-End Zero-Shot Biomedical Relation Extraction with LLMs: Experiments with OpenAI Models
Apr 05, 2025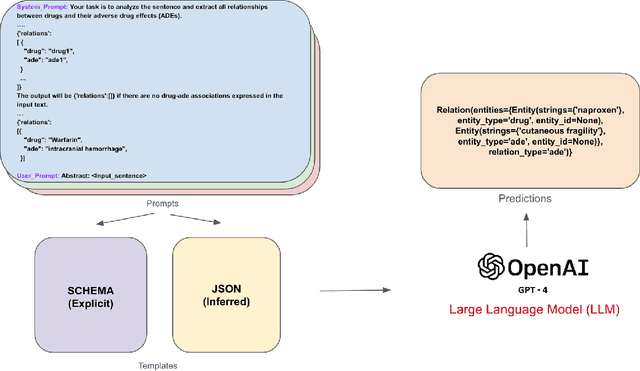
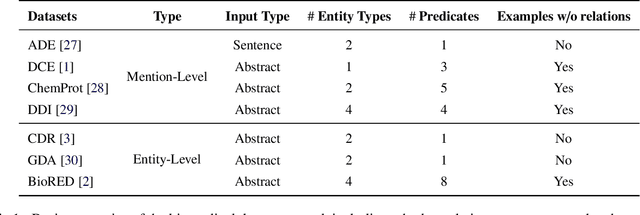
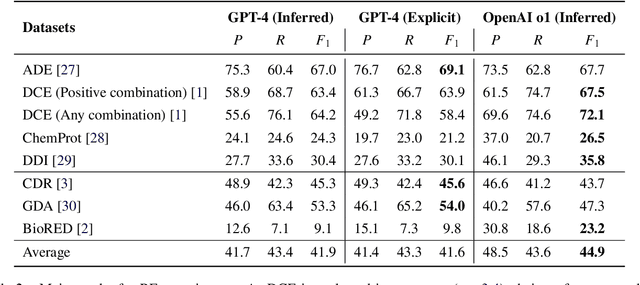
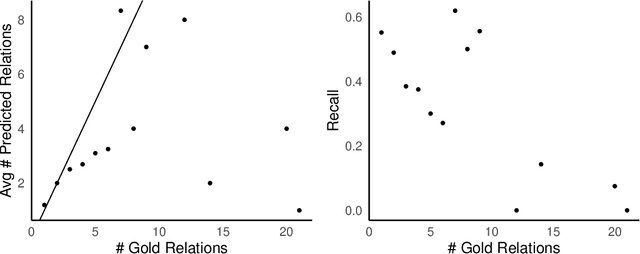
Objective: Zero-shot methodology promises to cut down on costs of dataset annotation and domain expertise needed to make use of NLP. Generative large language models trained to align with human goals have achieved high zero-shot performance across a wide variety of tasks. As of yet, it is unclear how well these models perform on biomedical relation extraction (RE). To address this knowledge gap, we explore patterns in the performance of OpenAI LLMs across a diverse sampling of RE tasks. Methods: We use OpenAI GPT-4-turbo and their reasoning model o1 to conduct end-to-end RE experiments on seven datasets. We use the JSON generation capabilities of GPT models to generate structured output in two ways: (1) by defining an explicit schema describing the structure of relations, and (2) using a setting that infers the structure from the prompt language. Results: Our work is the first to study and compare the performance of the GPT-4 and o1 for the end-to-end zero-shot biomedical RE task across a broad array of datasets. We found the zero-shot performances to be proximal to that of fine-tuned methods. The limitations of this approach are that it performs poorly on instances containing many relations and errs on the boundaries of textual mentions. Conclusion: Recent large language models exhibit promising zero-shot capabilities in complex biomedical RE tasks, offering competitive performance with reduced dataset curation and NLP modeling needs at the cost of increased computing, potentially increasing medical community accessibility. Addressing the limitations we identify could further boost reliability. The code, data, and prompts for all our experiments are publicly available: https://github.com/bionlproc/ZeroShotRE
A Simpler Alternative to Variational Regularized Counterfactual Risk Minimization
Sep 15, 2024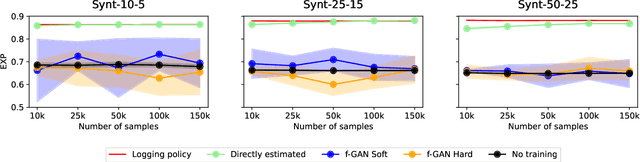

Variance regularized counterfactual risk minimization (VRCRM) has been proposed as an alternative off-policy learning (OPL) method. VRCRM method uses a lower-bound on the $f$-divergence between the logging policy and the target policy as regularization during learning and was shown to improve performance over existing OPL alternatives on multi-label classification tasks. In this work, we revisit the original experimental setting of VRCRM and propose to minimize the $f$-divergence directly, instead of optimizing for the lower bound using a $f$-GAN approach. Surprisingly, we were unable to reproduce the results reported in the original setting. In response, we propose a novel simpler alternative to f-divergence optimization by minimizing a direct approximation of f-divergence directly, instead of a $f$-GAN based lower bound. Experiments showed that minimizing the divergence using $f$-GANs did not work as expected, whereas our proposed novel simpler alternative works better empirically.
Proximal Ranking Policy Optimization for Practical Safety in Counterfactual Learning to Rank
Sep 15, 2024


Counterfactual learning to rank (CLTR) can be risky and, in various circumstances, can produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR methods, cannot handle trust bias, and relies on specific assumptions about user behavior. We propose a novel approach, proximal ranking policy optimization (PRPO), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that PRPO provides higher performance than the existing safe inverse propensity scoring approach. PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.
SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
Sep 11, 2024Given that Large Language Models (LLMs) have made significant progress in writing code, can they now be used to autonomously reproduce results from research repositories? Such a capability would be a boon to the research community, helping researchers validate, understand, and extend prior work. To advance towards this goal, we introduce SUPER, the first benchmark designed to evaluate the capability of LLMs in setting up and executing tasks from research repositories. SUPERaims to capture the realistic challenges faced by researchers working with Machine Learning (ML) and Natural Language Processing (NLP) research repositories. Our benchmark comprises three distinct problem sets: 45 end-to-end problems with annotated expert solutions, 152 sub problems derived from the expert set that focus on specific challenges (e.g., configuring a trainer), and 602 automatically generated problems for larger-scale development. We introduce various evaluation measures to assess both task success and progress, utilizing gold solutions when available or approximations otherwise. We show that state-of-the-art approaches struggle to solve these problems with the best model (GPT-4o) solving only 16.3% of the end-to-end set, and 46.1% of the scenarios. This illustrates the challenge of this task, and suggests that SUPER can serve as a valuable resource for the community to make and measure progress.
Practical and Robust Safety Guarantees for Advanced Counterfactual Learning to Rank
Jul 29, 2024



Counterfactual learning to rank (CLTR ) can be risky; various circumstances can cause it to produce sub-optimal models that hurt performance when deployed. Safe CLTR was introduced to mitigate these risks when using inverse propensity scoring to correct for position bias. However, the existing safety measure for CLTR is not applicable to state-of-the-art CLTR, it cannot handle trust bias, and its guarantees rely on specific assumptions about user behavior. Our contributions are two-fold. First, we generalize the existing safe CLTR approach to make it applicable to state-of-the-art doubly robust (DR) CLTR and trust bias. Second, we propose a novel approach, proximal ranking policy optimization (PRPO ), that provides safety in deployment without assumptions about user behavior. PRPO removes incentives for learning ranking behavior that is too dissimilar to a safe ranking model. Thereby, PRPO imposes a limit on how much learned models can degrade performance metrics, without relying on any specific user assumptions. Our experiments show that both our novel safe doubly robust method and PRPO provide higher performance than the existing safe inverse propensity scoring approach. However, when circumstances are unexpected, the safe doubly robust approach can become unsafe and bring detrimental performance. In contrast, PRPO always maintains safety, even in maximally adversarial situations. By avoiding assumptions, PRPO is the first method with unconditional safety in deployment that translates to robust safety for real-world applications.