 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Benchmarking Shows Limited Generalization Power of TCR Antigenic Epitope Prediction Models
Jun 03, 2026Accurate computational prediction of T cell receptor (TCR) antigen specificity would transform the study of T cell biology and enable scalable immune engineering, yet existing models lack sufficient sensitivity and specificity for broad applications. A major limitation is the absence of rigorously defined, unseen benchmark datasets that allow unbiased evaluation of model performance and generalizability. Here, we describe two complementary classes of datasets that meet this criterion and argue that they provide both a robust framework for model assessment and a foundation for next-generation TCR-antigen prediction algorithm development.
Med-HEAL: Analyzing and Mitigating Hallucinations in Medical LLMs with Hallucination-Aware In-Context Learning
May 31, 2026Hallucinations in medical large language models (LLMs) pose serious risks for clinical decision support, particularly when models must reason over complex electronic health records (EHRs). However, existing benchmarks often lack a realistic clinical context and provide limited insight into how hallucinations can be mitigated in practice. We introduce Med-HEAL, a framework for systematically identifying, analyzing, and mitigating hallucinations in medical LLMs using clinically grounded data. Building on the EHRNoteQA benchmark derived from MIMIC-IV discharge summaries, we construct a hallucination dataset by evaluating BioMistral-7B on open-ended clinical question answering tasks. Model outputs are labeled through a dual evaluation pipeline that combines LLM-as-a-Judge assessment (GPT-4o) with human auditing by medical student reviewers, producing correctness judgments and annotations of reasoning errors via a custom web-based evaluation system. We then leverage this dataset to investigate mitigation strategies: a self-critique pipeline, in which the test model reviews its own answers to detect potential errors and regenerates responses for flagged cases, and retrieval-augmented in-context learning (RA-ICL), which exposes the model to hallucinated and corrected examples. Experiments across five open-source LLMs-BioMistral, Llama-3.1, DeepSeek, Qwen2.5, and Qwen3, show that the self-critique strategy improves accuracy for three of five models (p < 0.05) without requiring parameter updates. Med-HEAL provides both a reusable hallucination dataset and a practical framework for studying and mitigating hallucinations in medical LLMs, supporting safer deployment of AI systems in clinical environments. Our code and data are publicly available at https://github.com/yimingliao-blad/med-heal.git.
Towards Two-Stage Counterfactual Learning to Rank
Jun 25, 2025
Counterfactual learning to rank (CLTR) aims to learn a ranking policy from user interactions while correcting for the inherent biases in interaction data, such as position bias. Existing CLTR methods assume a single ranking policy that selects top-K ranking from the entire document candidate set. In real-world applications, the candidate document set is on the order of millions, making a single-stage ranking policy impractical. In order to scale to millions of documents, real-world ranking systems are designed in a two-stage fashion, with a candidate generator followed by a ranker. The existing CLTR method for a two-stage offline ranking system only considers the top-1 ranking set-up and only focuses on training the candidate generator, with the ranker fixed. A CLTR method for training both the ranker and candidate generator jointly is missing from the existing literature. In this paper, we propose a two-stage CLTR estimator that considers the interaction between the two stages and estimates the joint value of the two policies offline. In addition, we propose a novel joint optimization method to train the candidate and ranker policies, respectively. To the best of our knowledge, we are the first to propose a CLTR estimator and learning method for two-stage ranking. Experimental results on a semi-synthetic benchmark demonstrate the effectiveness of the proposed joint CLTR method over baselines.
Unveiling User Satisfaction and Creator Productivity Trade-Offs in Recommendation Platforms
Oct 31, 2024



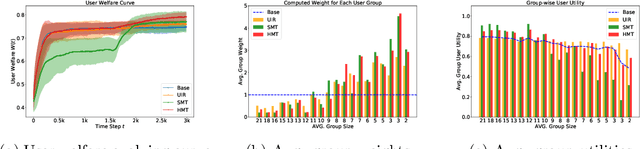
On User-Generated Content (UGC) platforms, recommendation algorithms significantly impact creators' motivation to produce content as they compete for algorithmically allocated user traffic. This phenomenon subtly shapes the volume and diversity of the content pool, which is crucial for the platform's sustainability. In this work, we demonstrate, both theoretically and empirically, that a purely relevance-driven policy with low exploration strength boosts short-term user satisfaction but undermines the long-term richness of the content pool. In contrast, a more aggressive exploration policy may slightly compromise user satisfaction but promote higher content creation volume. Our findings reveal a fundamental trade-off between immediate user satisfaction and overall content production on UGC platforms. Building on this finding, we propose an efficient optimization method to identify the optimal exploration strength, balancing user and creator engagement. Our model can serve as a pre-deployment audit tool for recommendation algorithms on UGC platforms, helping to align their immediate objectives with sustainable, long-term goals.
User Welfare Optimization in Recommender Systems with Competing Content Creators
Apr 28, 2024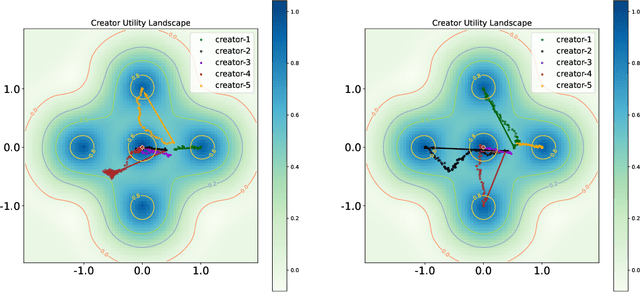


Driven by the new economic opportunities created by the creator economy, an increasing number of content creators rely on and compete for revenue generated from online content recommendation platforms. This burgeoning competition reshapes the dynamics of content distribution and profoundly impacts long-term user welfare on the platform. However, the absence of a comprehensive picture of global user preference distribution often traps the competition, especially the creators, in states that yield sub-optimal user welfare. To encourage creators to best serve a broad user population with relevant content, it becomes the platform's responsibility to leverage its information advantage regarding user preference distribution to accurately signal creators. In this study, we perform system-side user welfare optimization under a competitive game setting among content creators. We propose an algorithmic solution for the platform, which dynamically computes a sequence of weights for each user based on their satisfaction of the recommended content. These weights are then utilized to design mechanisms that adjust the recommendation policy or the post-recommendation rewards, thereby influencing creators' content production strategies. To validate the effectiveness of our proposed method, we report our findings from a series of experiments, including: 1. a proof-of-concept negative example illustrating how creators' strategies converge towards sub-optimal states without platform intervention; 2. offline experiments employing our proposed intervention mechanisms on diverse datasets; and 3. results from a three-week online experiment conducted on a leading short-video recommendation platform.
Regularizing Matrix Factorization with User and Item Embeddings for Recommendation
Aug 31, 2018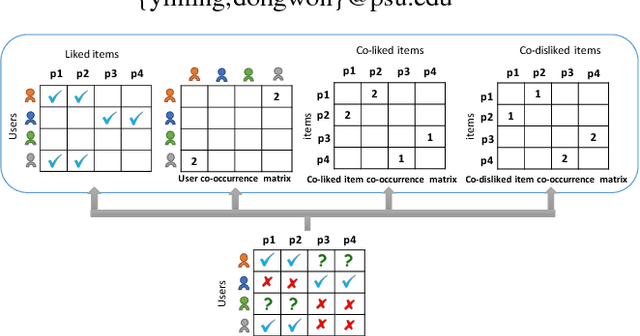
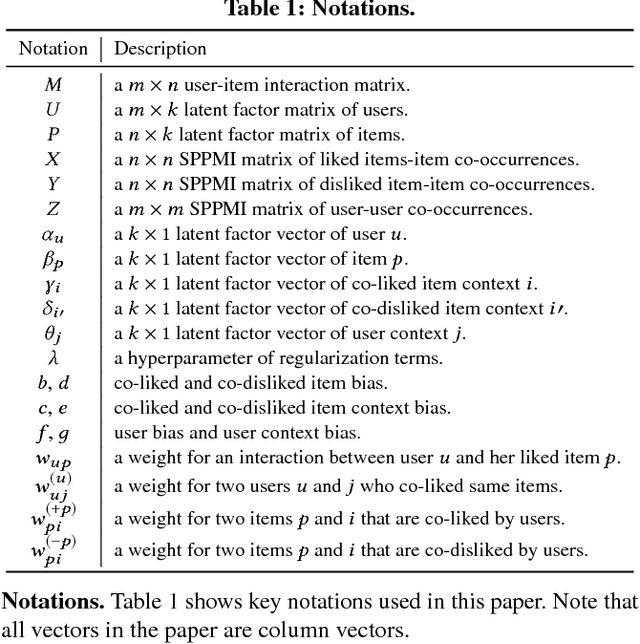
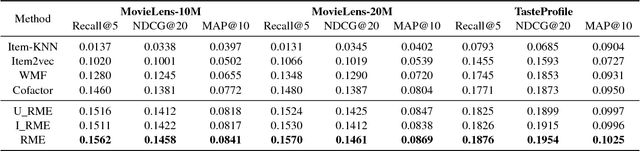
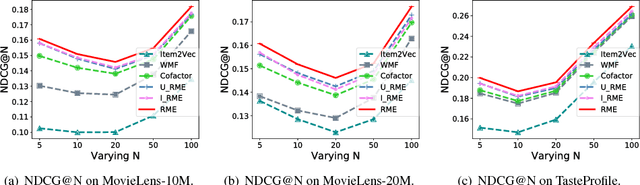
Following recent successes in exploiting both latent factor and word embedding models in recommendation, we propose a novel Regularized Multi-Embedding (RME) based recommendation model that simultaneously encapsulates the following ideas via decomposition: (1) which items a user likes, (2) which two users co-like the same items, (3) which two items users often co-liked, and (4) which two items users often co-disliked. In experimental validation, the RME outperforms competing state-of-the-art models in both explicit and implicit feedback datasets, significantly improving Recall@5 by 5.9~7.0%, NDCG@20 by 4.3~5.6%, and MAP@10 by 7.9~8.9%. In addition, under the cold-start scenario for users with the lowest number of interactions, against the competing models, the RME outperforms NDCG@5 by 20.2% and 29.4% in MovieLens-10M and MovieLens-20M datasets, respectively. Our datasets and source code are available at: https://github.com/thanhdtran/RME.git.
* CIKM 2018