 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
Mar 26, 2026Autoregressive video diffusion models have demonstrated remarkable progress, yet they remain bottlenecked by intractable linear KV-cache growth, temporal repetition, and compounding errors during long-video generation. To address these challenges, we present PackForcing, a unified framework that efficiently manages the generation history through a novel three-partition KV-cache strategy. Specifically, we categorize the historical context into three distinct types: (1) Sink tokens, which preserve early anchor frames at full resolution to maintain global semantics; (2) Mid tokens, which achieve a massive spatiotemporal compression (32x token reduction) via a dual-branch network fusing progressive 3D convolutions with low-resolution VAE re-encoding; and (3) Recent tokens, kept at full resolution to ensure local temporal coherence. To strictly bound the memory footprint without sacrificing quality, we introduce a dynamic top-$k$ context selection mechanism for the mid tokens, coupled with a continuous Temporal RoPE Adjustment that seamlessly re-aligns position gaps caused by dropped tokens with negligible overhead. Empowered by this principled hierarchical context compression, PackForcing can generate coherent 2-minute, 832x480 videos at 16 FPS on a single H200 GPU. It achieves a bounded KV cache of just 4 GB and enables a remarkable 24x temporal extrapolation (5s to 120s), operating effectively either zero-shot or trained on merely 5-second clips. Extensive results on VBench demonstrate state-of-the-art temporal consistency (26.07) and dynamic degree (56.25), proving that short-video supervision is sufficient for high-quality, long-video synthesis. https://github.com/ShandaAI/PackForcing
WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
Mar 24, 2026Dynamical systems theory and reinforcement learning view world evolution as latent-state dynamics driven by actions, with visual observations providing partial information about the state. Recent video world models attempt to learn this action-conditioned dynamics from data. However, existing datasets rarely match the requirement: they typically lack diverse and semantically meaningful action spaces, and actions are directly tied to visual observations rather than mediated by underlying states. As a result, actions are often entangled with pixel-level changes, making it difficult for models to learn structured world dynamics and maintain consistent evolution over long horizons. In this paper, we propose WildWorld, a large-scale action-conditioned world modeling dataset with explicit state annotations, automatically collected from a photorealistic AAA action role-playing game (Monster Hunter: Wilds). WildWorld contains over 108 million frames and features more than 450 actions, including movement, attacks, and skill casting, together with synchronized per-frame annotations of character skeletons, world states, camera poses, and depth maps. We further derive WildBench to evaluate models through Action Following and State Alignment. Extensive experiments reveal persistent challenges in modeling semantically rich actions and maintaining long-horizon state consistency, highlighting the need for state-aware video generation. The project page is https://shandaai.github.io/wildworld-project/.
Specification-Driven Generation and Evaluation of Discrete-Event World Models via the DEVS Formalism
Mar 04, 2026World models are essential for planning and evaluation in agentic systems, yet existing approaches lie at two extremes: hand-engineered simulators that offer consistency and reproducibility but are costly to adapt, and implicit neural models that are flexible but difficult to constrain, verify, and debug over long horizons. We seek a principled middle ground that combines the reliability of explicit simulators with the flexibility of learned models, allowing world models to be adapted during online execution. By targeting a broad class of environments whose dynamics are governed by the ordering, timing, and causality of discrete events, such as queueing and service operations, embodied task planning, and message-mediated multi-agent coordination, we advocate explicit, executable discrete-event world models synthesized directly from natural-language specifications. Our approach adopts the DEVS formalism and introduces a staged LLM-based generation pipeline that separates structural inference of component interactions from component-level event and timing logic. To evaluate generated models without a unique ground truth, simulators emit structured event traces that are validated against specification-derived temporal and semantic constraints, enabling reproducible verification and localized diagnostics. Together, these contributions produce world models that are consistent over long-horizon rollouts, verifiable from observable behavior, and efficient to synthesize on demand during online execution.
ProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
Yume-1.5: A Text-Controlled Interactive World Generation Model
Dec 26, 2025Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds. However, most of these methods face critical challenges such as excessively large parameter sizes, reliance on lengthy inference steps, and rapidly growing historical context, which severely limit real-time performance and lack text-controlled generation capabilities. To address these challenges, we propose \method, a novel framework designed to generate realistic, interactive, and continuous worlds from a single image or text prompt. \method achieves this through a carefully designed framework that supports keyboard-based exploration of the generated worlds. The framework comprises three core components: (1) a long-video generation framework integrating unified context compression with linear attention; (2) a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme; (3) a text-controlled method for generating world events. We have provided the codebase in the supplementary material.
SVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
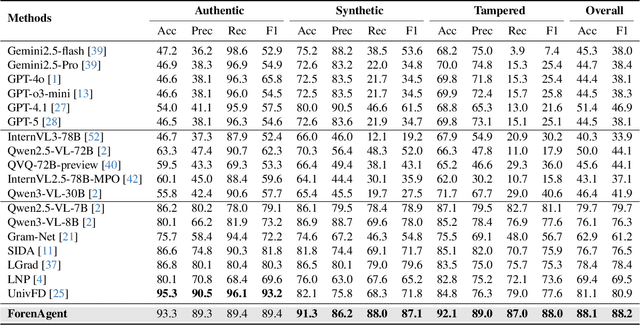
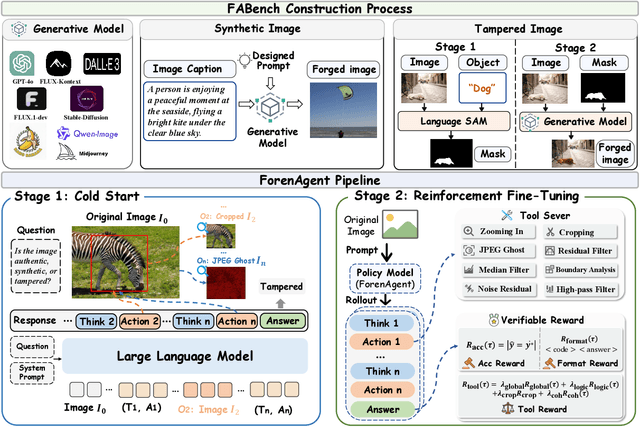
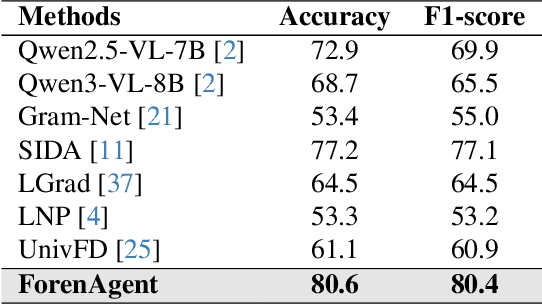
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
Composition-Incremental Learning for Compositional Generalization
Nov 12, 2025Compositional generalization has achieved substantial progress in computer vision on pre-collected training data. Nonetheless, real-world data continually emerges, with possible compositions being nearly infinite, long-tailed, and not entirely visible. Thus, an ideal model is supposed to gradually improve the capability of compositional generalization in an incremental manner. In this paper, we explore Composition-Incremental Learning for Compositional Generalization (CompIL) in the context of the compositional zero-shot learning (CZSL) task, where models need to continually learn new compositions, intending to improve their compositional generalization capability progressively. To quantitatively evaluate CompIL, we develop a benchmark construction pipeline leveraging existing datasets, yielding MIT-States-CompIL and C-GQA-CompIL. Furthermore, we propose a pseudo-replay framework utilizing a visual synthesizer to synthesize visual representations of learned compositions and a linguistic primitive distillation mechanism to maintain aligned primitive representations across the learning process. Extensive experiments demonstrate the effectiveness of the proposed framework.
From Pixels to Paths: A Multi-Agent Framework for Editable Scientific Illustration
Oct 31, 2025Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
Dialogue as Discovery: Navigating Human Intent Through Principled Inquiry
Oct 31, 2025A fundamental bottleneck in human-AI collaboration is the "intention expression gap," the difficulty for humans to effectively convey complex, high-dimensional thoughts to AI. This challenge often traps users in inefficient trial-and-error loops and is exacerbated by the diverse expertise levels of users. We reframe this problem from passive instruction following to a Socratic collaboration paradigm, proposing an agent that actively probes for information to resolve its uncertainty about user intent. we name the proposed agent Nous, trained to acquire proficiency in this inquiry policy. The core mechanism of Nous is a training framework grounded in the first principles of information theory. Within this framework, we define the information gain from dialogue as an intrinsic reward signal, which is fundamentally equivalent to the reduction of Shannon entropy over a structured task space. This reward design enables us to avoid reliance on costly human preference annotations or external reward models. To validate our framework, we develop an automated simulation pipeline to generate a large-scale, preference-based dataset for the challenging task of scientific diagram generation. Comprehensive experiments, including ablations, subjective and objective evaluations, and tests across user expertise levels, demonstrate the effectiveness of our proposed framework. Nous achieves leading efficiency and output quality, while remaining robust to varying user expertise. Moreover, its design is domain-agnostic, and we show evidence of generalization beyond diagram generation. Experimental results prove that our work offers a principled, scalable, and adaptive paradigm for resolving uncertainty about user intent in complex human-AI collaboration.