 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
IA-T2I: Internet-Augmented Text-to-Image Generation
May 21, 2025Current text-to-image (T2I) generation models achieve promising results, but they fail on the scenarios where the knowledge implied in the text prompt is uncertain. For example, a T2I model released in February would struggle to generate a suitable poster for a movie premiering in April, because the character designs and styles are uncertain to the model. To solve this problem, we propose an Internet-Augmented text-to-image generation (IA-T2I) framework to compel T2I models clear about such uncertain knowledge by providing them with reference images. Specifically, an active retrieval module is designed to determine whether a reference image is needed based on the given text prompt; a hierarchical image selection module is introduced to find the most suitable image returned by an image search engine to enhance the T2I model; a self-reflection mechanism is presented to continuously evaluate and refine the generated image to ensure faithful alignment with the text prompt. To evaluate the proposed framework's performance, we collect a dataset named Img-Ref-T2I, where text prompts include three types of uncertain knowledge: (1) known but rare. (2) unknown. (3) ambiguous. Moreover, we carefully craft a complex prompt to guide GPT-4o in making preference evaluation, which has been shown to have an evaluation accuracy similar to that of human preference evaluation. Experimental results demonstrate the effectiveness of our framework, outperforming GPT-4o by about 30% in human evaluation.
Memory-Centric Embodied Question Answer
May 20, 2025

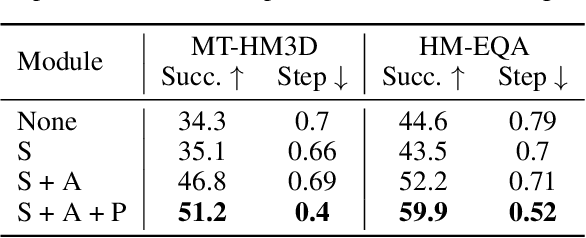
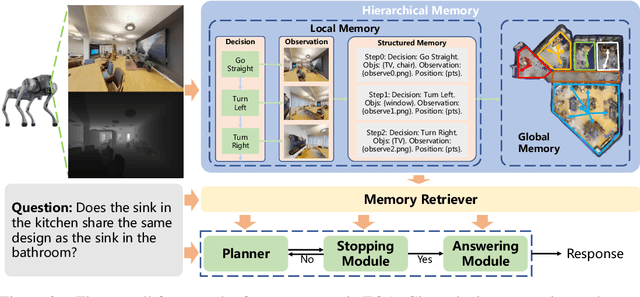
Embodied Question Answering (EQA) requires agents to autonomously explore and understand the environment to answer context-dependent questions. Existing frameworks typically center around the planner, which guides the stopping module, memory module, and answering module for reasoning. In this paper, we propose a memory-centric EQA framework named MemoryEQA. Unlike planner-centric EQA models where the memory module cannot fully interact with other modules, MemoryEQA flexible feeds memory information into all modules, thereby enhancing efficiency and accuracy in handling complex tasks, such as those involving multiple targets across different regions. Specifically, we establish a multi-modal hierarchical memory mechanism, which is divided into global memory that stores language-enhanced scene maps, and local memory that retains historical observations and state information. When performing EQA tasks, the multi-modal large language model is leveraged to convert memory information into the required input formats for injection into different modules. To evaluate EQA models' memory capabilities, we constructed the MT-HM3D dataset based on HM3D, comprising 1,587 question-answer pairs involving multiple targets across various regions, which requires agents to maintain memory of exploration-acquired target information. Experimental results on HM-EQA, MT-HM3D, and OpenEQA demonstrate the effectiveness of our framework, where a 19.8% performance gain on MT-HM3D compared to baseline model further underscores memory capability's pivotal role in resolving complex tasks.
World knowledge-enhanced Reasoning Using Instruction-guided Interactor in Autonomous Driving
Dec 09, 2024



The Multi-modal Large Language Models (MLLMs) with extensive world knowledge have revitalized autonomous driving, particularly in reasoning tasks within perceivable regions. However, when faced with perception-limited areas (dynamic or static occlusion regions), MLLMs struggle to effectively integrate perception ability with world knowledge for reasoning. These perception-limited regions can conceal crucial safety information, especially for vulnerable road users. In this paper, we propose a framework, which aims to improve autonomous driving performance under perceptionlimited conditions by enhancing the integration of perception capabilities and world knowledge. Specifically, we propose a plug-and-play instruction-guided interaction module that bridges modality gaps and significantly reduces the input sequence length, allowing it to adapt effectively to multi-view video inputs. Furthermore, to better integrate world knowledge with driving-related tasks, we have collected and refined a large-scale multi-modal dataset that includes 2 million natural language QA pairs, 1.7 million grounding task data. To evaluate the model's utilization of world knowledge, we introduce an object-level risk assessment dataset comprising 200K QA pairs, where the questions necessitate multi-step reasoning leveraging world knowledge for resolution. Extensive experiments validate the effectiveness of our proposed method.
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023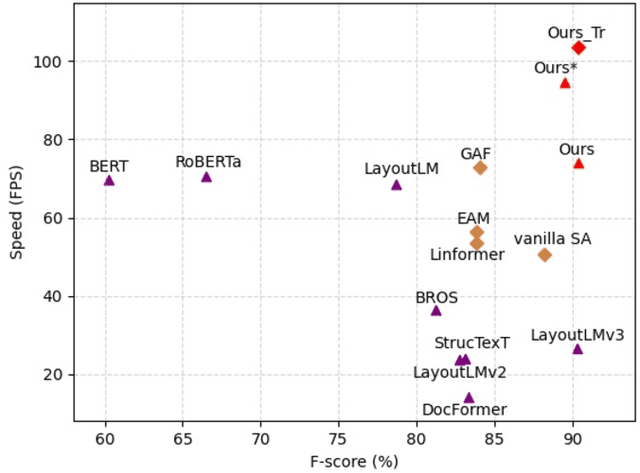



Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.