 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Global-Local Cross-Attention Network for Ultra-high Resolution Remote Sensing Image Semantic Segmentation
Jun 24, 2025With the rapid development of ultra-high resolution (UHR) remote sensing technology, the demand for accurate and efficient semantic segmentation has increased significantly. However, existing methods face challenges in computational efficiency and multi-scale feature fusion. To address these issues, we propose GLCANet (Global-Local Cross-Attention Network), a lightweight segmentation framework designed for UHR remote sensing imagery.GLCANet employs a dual-stream architecture to efficiently fuse global semantics and local details while minimizing GPU usage. A self-attention mechanism enhances long-range dependencies, refines global features, and preserves local details for better semantic consistency. A masked cross-attention mechanism also adaptively fuses global-local features, selectively enhancing fine-grained details while exploiting global context to improve segmentation accuracy. Experimental results show that GLCANet outperforms state-of-the-art methods regarding accuracy and computational efficiency. The model effectively processes large, high-resolution images with a small memory footprint, providing a promising solution for real-world remote sensing applications.
Fast-StrucTexT: An Efficient Hourglass Transformer with Modality-guided Dynamic Token Merge for Document Understanding
May 19, 2023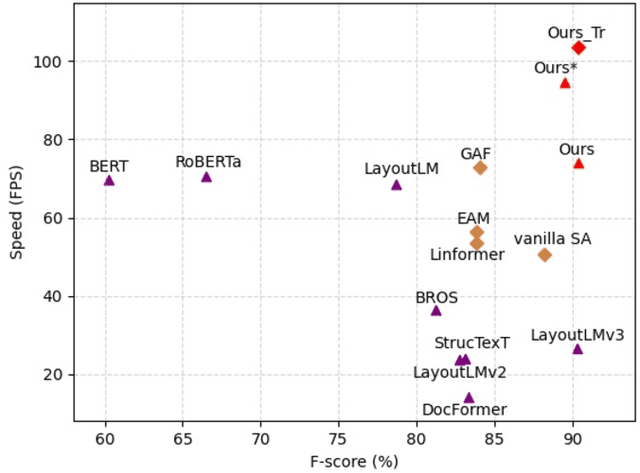



Transformers achieve promising performance in document understanding because of their high effectiveness and still suffer from quadratic computational complexity dependency on the sequence length. General efficient transformers are challenging to be directly adapted to model document. They are unable to handle the layout representation in documents, e.g. word, line and paragraph, on different granularity levels and seem hard to achieve a good trade-off between efficiency and performance. To tackle the concerns, we propose Fast-StrucTexT, an efficient multi-modal framework based on the StrucTexT algorithm with an hourglass transformer architecture, for visual document understanding. Specifically, we design a modality-guided dynamic token merging block to make the model learn multi-granularity representation and prunes redundant tokens. Additionally, we present a multi-modal interaction module called Symmetry Cross Attention (SCA) to consider multi-modal fusion and efficiently guide the token mergence. The SCA allows one modality input as query to calculate cross attention with another modality in a dual phase. Extensive experiments on FUNSD, SROIE, and CORD datasets demonstrate that our model achieves the state-of-the-art performance and almost 1.9X faster inference time than the state-of-the-art methods.
Latency Aware Semi-synchronous Client Selection and Model Aggregation for Wireless Federated Learning
Oct 19, 2022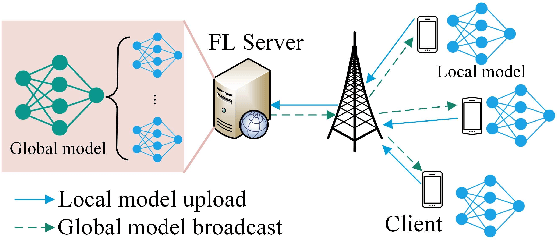

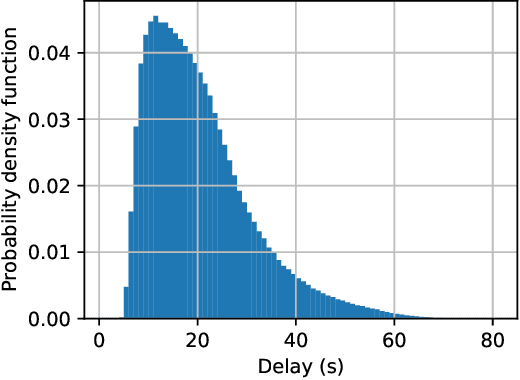
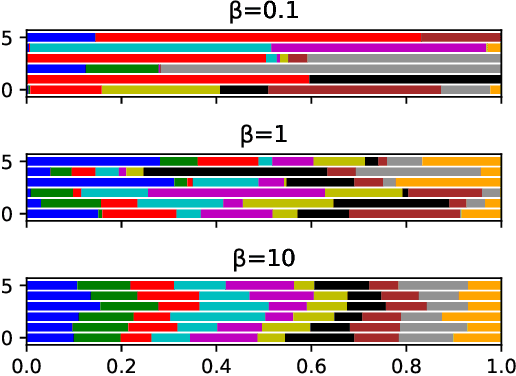
Federated learning (FL) is a collaborative machine learning framework that requires different clients (e.g., Internet of Things devices) to participate in the machine learning model training process by training and uploading their local models to an FL server in each global iteration. Upon receiving the local models from all the clients, the FL server generates a global model by aggregating the received local models. This traditional FL process may suffer from the straggler problem in heterogeneous client settings, where the FL server has to wait for slow clients to upload their local models in each global iteration, thus increasing the overall training time. One of the solutions is to set up a deadline and only the clients that can upload their local models before the deadline would be selected in the FL process. This solution may lead to a slow convergence rate and global model overfitting issues due to the limited client selection. In this paper, we propose the Latency awarE Semi-synchronous client Selection and mOdel aggregation for federated learNing (LESSON) method that allows all the clients to participate in the whole FL process but with different frequencies. That is, faster clients would be scheduled to upload their models more frequently than slow clients, thus resolving the straggler problem and accelerating the convergence speed, while avoiding model overfitting. Also, LESSON is capable of adjusting the tradeoff between the model accuracy and convergence rate by varying the deadline. Extensive simulations have been conducted to compare the performance of LESSON with the other two baseline methods, i.e., FedAvg and FedCS. The simulation results demonstrate that LESSON achieves faster convergence speed than FedAvg and FedCS, and higher model accuracy than FedCS.