 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld knowledge-enhanced Reasoning Using Instruction-guided Interactor in Autonomous Driving
Dec 09, 2024The Multi-modal Large Language Models (MLLMs) with extensive world knowledge have revitalized autonomous driving, particularly in reasoning tasks within perceivable regions. However, when faced with perception-limited areas (dynamic or static occlusion regions), MLLMs struggle to effectively integrate perception ability with world knowledge for reasoning. These perception-limited regions can conceal crucial safety information, especially for vulnerable road users. In this paper, we propose a framework, which aims to improve autonomous driving performance under perceptionlimited conditions by enhancing the integration of perception capabilities and world knowledge. Specifically, we propose a plug-and-play instruction-guided interaction module that bridges modality gaps and significantly reduces the input sequence length, allowing it to adapt effectively to multi-view video inputs. Furthermore, to better integrate world knowledge with driving-related tasks, we have collected and refined a large-scale multi-modal dataset that includes 2 million natural language QA pairs, 1.7 million grounding task data. To evaluate the model's utilization of world knowledge, we introduce an object-level risk assessment dataset comprising 200K QA pairs, where the questions necessitate multi-step reasoning leveraging world knowledge for resolution. Extensive experiments validate the effectiveness of our proposed method.
StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Mar 01, 2023
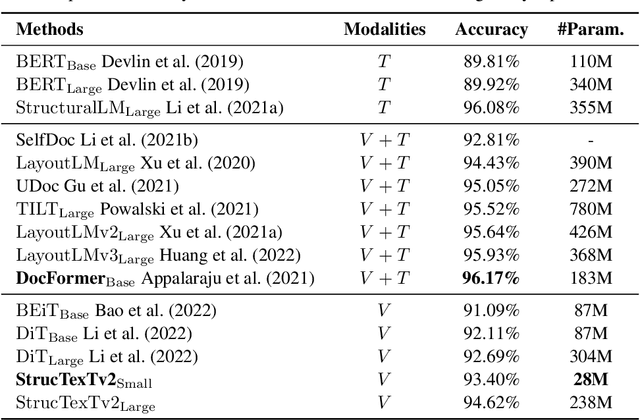
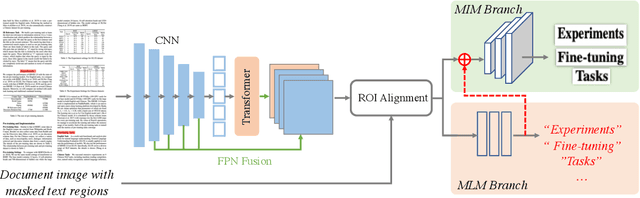

In this paper, we present StrucTexTv2, an effective document image pre-training framework, by performing masked visual-textual prediction. It consists of two self-supervised pre-training tasks: masked image modeling and masked language modeling, based on text region-level image masking. The proposed method randomly masks some image regions according to the bounding box coordinates of text words. The objectives of our pre-training tasks are reconstructing the pixels of masked image regions and the corresponding masked tokens simultaneously. Hence the pre-trained encoder can capture more textual semantics in comparison to the masked image modeling that usually predicts the masked image patches. Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing. Extensive experiments on mainstream benchmarks of document image understanding demonstrate the effectiveness of StrucTexTv2. It achieves competitive or even new state-of-the-art performance in various downstream tasks such as image classification, layout analysis, table structure recognition, document OCR, and information extraction under the end-to-end scenario.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022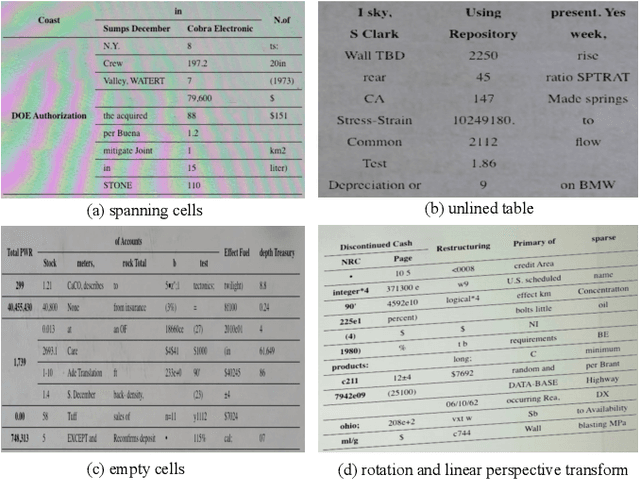
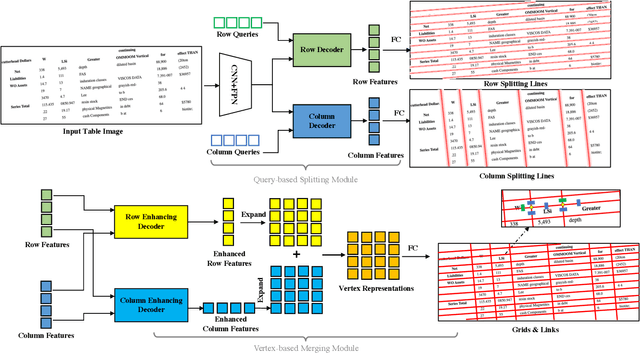
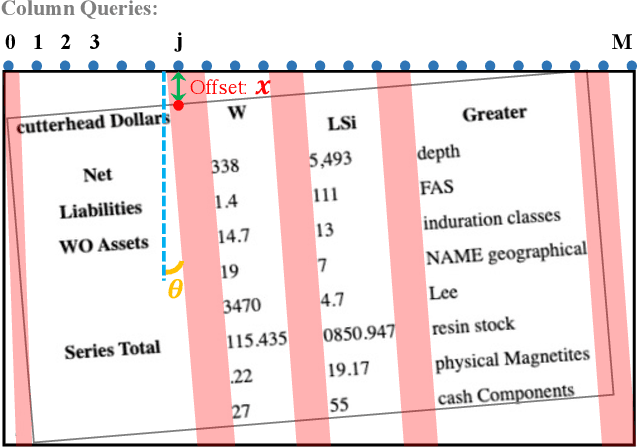
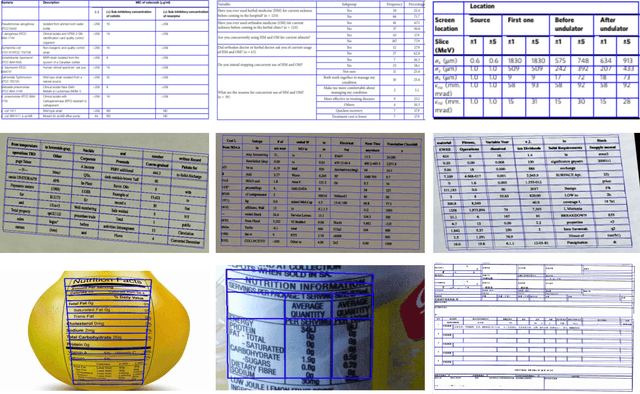
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
Location-Aware Feature Selection Text Detection Network
May 26, 2020



Regression-based text detection methods have already achieved promising performances with simple network structure and high efficiency. However, they are behind in accuracy comparing with recent segmentation-based text detectors. In this work, we discover that one important reason to this case is that regression-based methods usually utilize a fixed feature selection way, i.e. selecting features in a single location or in neighbor regions, to predict components of the bounding box, such as the distances to the boundaries or the rotation angle. The features selected through this way sometimes are not the best choices for predicting every component of a text bounding box and thus degrade the accuracy performance. To address this issue, we propose a novel Location-Aware feature Selection text detection Network (LASNet). LASNet selects suitable features from different locations to separately predict the five components of a bounding box and gets the final bounding box through the combination of these components. Specifically, instead of using the classification score map to select one feature for predicting the whole bounding box as most of the existing methods did, the proposed LASNet first learn five new confidence score maps to indicate the prediction accuracy of the bounding box components, respectively. Then, a Location-Aware Feature Selection mechanism (LAFS) is designed to weightily fuse the top-$K$ prediction results for each component according to their confidence score, and to combine the all five fused components into a final bounding box. As a result, LASNet predicts the more accurate bounding boxes by using a learnable feature selection way. The experimental results demonstrate that our LASNet achieves state-of-the-art performance with single-model and single-scale testing, outperforming all existing regression-based detectors.