 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGridFormer: Towards Accurate Table Structure Recognition via Grid Prediction
Sep 26, 2023



All tables can be represented as grids. Based on this observation, we propose GridFormer, a novel approach for interpreting unconstrained table structures by predicting the vertex and edge of a grid. First, we propose a flexible table representation in the form of an MXN grid. In this representation, the vertexes and edges of the grid store the localization and adjacency information of the table. Then, we introduce a DETR-style table structure recognizer to efficiently predict this multi-objective information of the grid in a single shot. Specifically, given a set of learned row and column queries, the recognizer directly outputs the vertexes and edges information of the corresponding rows and columns. Extensive experiments on five challenging benchmarks which include wired, wireless, multi-merge-cell, oriented, and distorted tables demonstrate the competitive performance of our model over other methods.
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training
Mar 01, 2023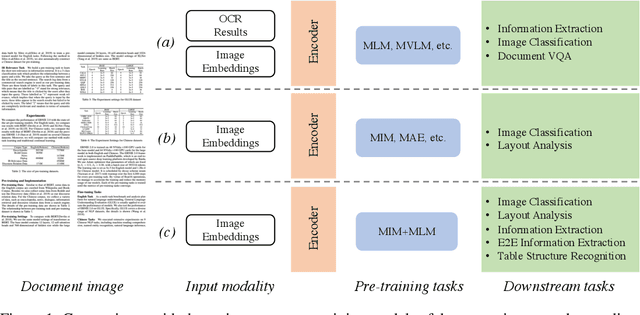
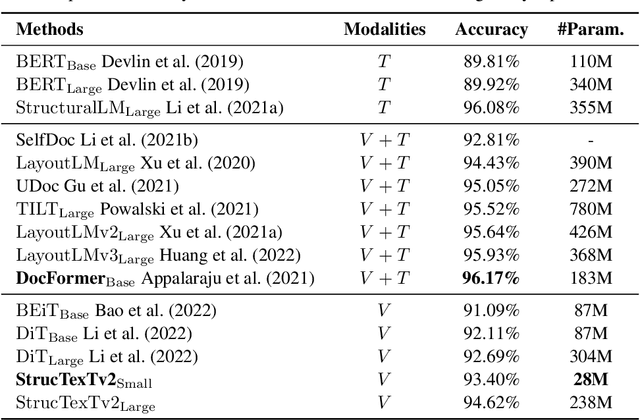
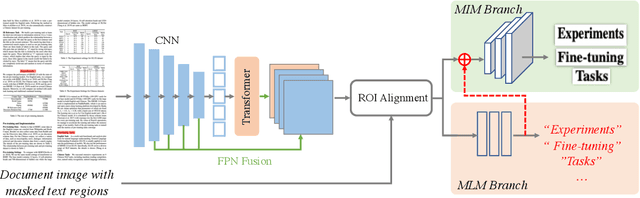

In this paper, we present StrucTexTv2, an effective document image pre-training framework, by performing masked visual-textual prediction. It consists of two self-supervised pre-training tasks: masked image modeling and masked language modeling, based on text region-level image masking. The proposed method randomly masks some image regions according to the bounding box coordinates of text words. The objectives of our pre-training tasks are reconstructing the pixels of masked image regions and the corresponding masked tokens simultaneously. Hence the pre-trained encoder can capture more textual semantics in comparison to the masked image modeling that usually predicts the masked image patches. Compared to the masked multi-modal modeling methods for document image understanding that rely on both the image and text modalities, StrucTexTv2 models image-only input and potentially deals with more application scenarios free from OCR pre-processing. Extensive experiments on mainstream benchmarks of document image understanding demonstrate the effectiveness of StrucTexTv2. It achieves competitive or even new state-of-the-art performance in various downstream tasks such as image classification, layout analysis, table structure recognition, document OCR, and information extraction under the end-to-end scenario.
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022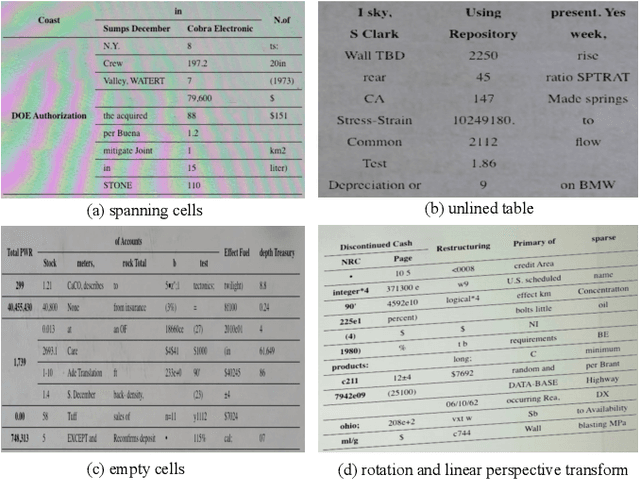
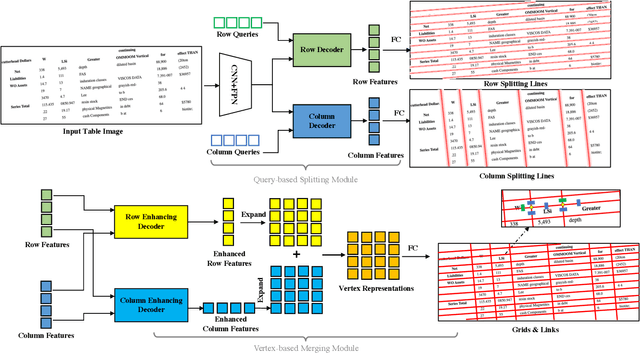
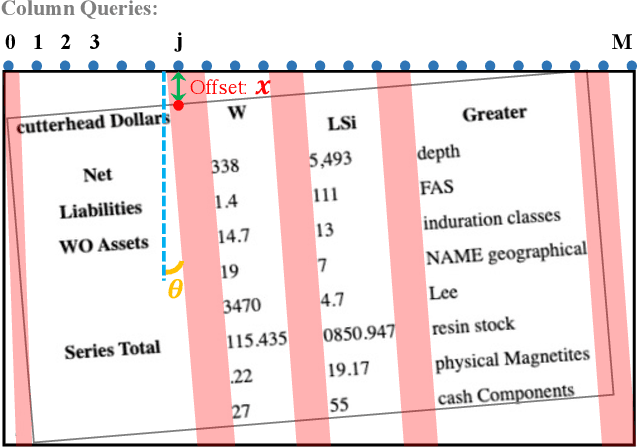
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
Deformable Siamese Attention Networks for Visual Object Tracking
Apr 14, 2020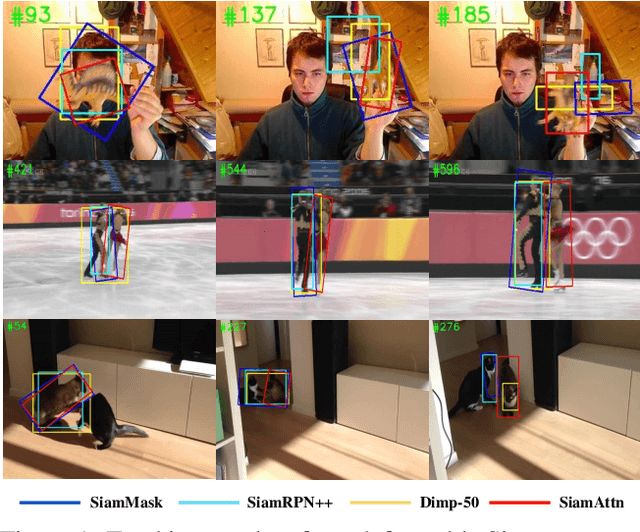
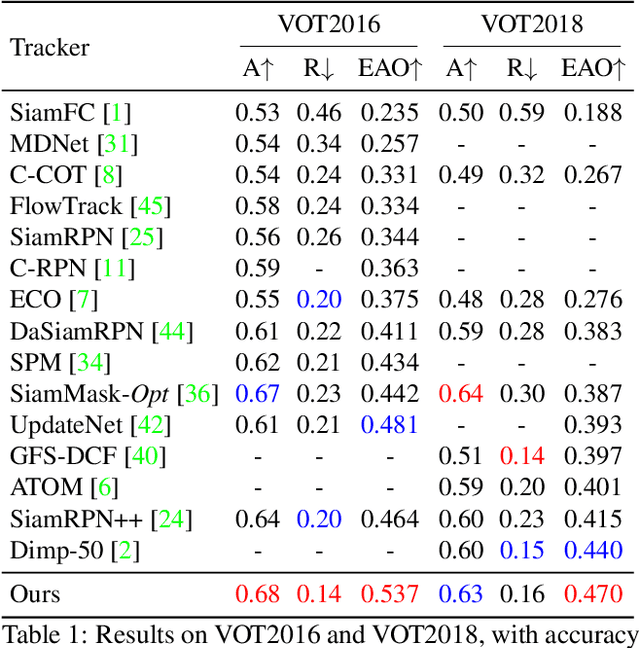
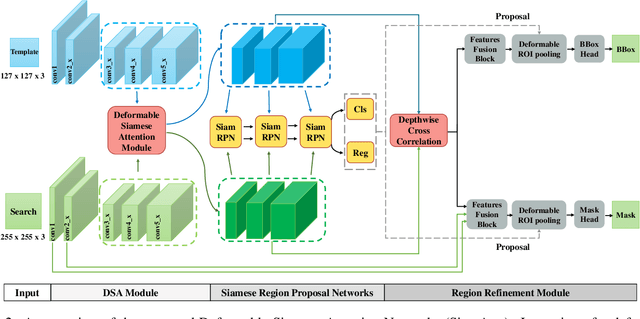
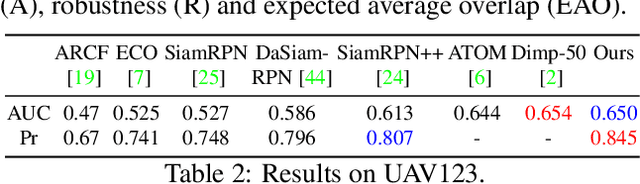
Siamese-based trackers have achieved excellent performance on visual object tracking. However, the target template is not updated online, and the features of the target template and search image are computed independently in a Siamese architecture. In this paper, we propose Deformable Siamese Attention Networks, referred to as SiamAttn, by introducing a new Siamese attention mechanism that computes deformable self-attention and cross-attention. The self attention learns strong context information via spatial attention, and selectively emphasizes interdependent channel-wise features with channel attention. The cross-attention is capable of aggregating rich contextual inter-dependencies between the target template and the search image, providing an implicit manner to adaptively update the target template. In addition, we design a region refinement module that computes depth-wise cross correlations between the attentional features for more accurate tracking. We conduct experiments on six benchmarks, where our method achieves new state of-the-art results, outperforming the strong baseline, SiamRPN++ [24], by 0.464->0.537 and 0.415->0.470 EAO on VOT 2016 and 2018.