 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOOD: Task-aligned One-stage Object Detection
Aug 28, 2021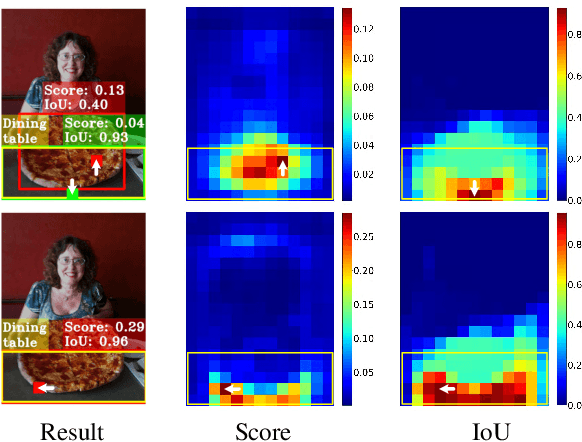
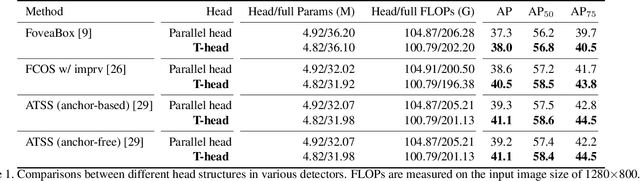
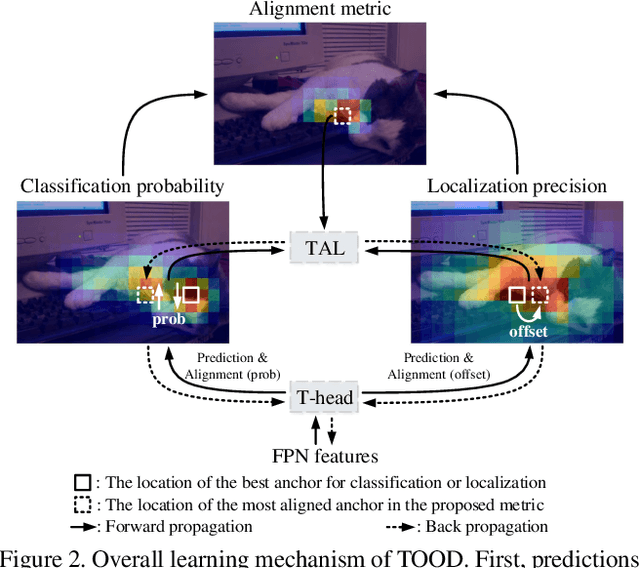
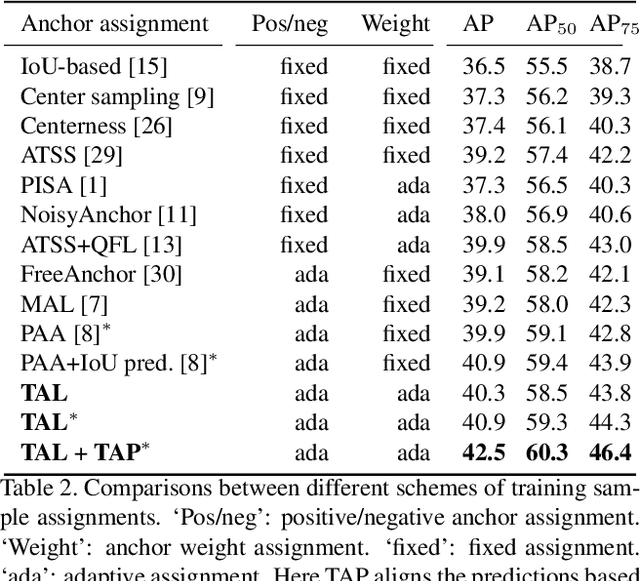
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks. In this work, we propose a Task-aligned One-stage Object Detection (TOOD) that explicitly aligns the two tasks in a learning-based manner. First, we design a novel Task-aligned Head (T-Head) which offers a better balance between learning task-interactive and task-specific features, as well as a greater flexibility to learn the alignment via a task-aligned predictor. Second, we propose Task Alignment Learning (TAL) to explicitly pull closer (or even unify) the optimal anchors for the two tasks during training via a designed sample assignment scheme and a task-aligned loss. Extensive experiments are conducted on MS-COCO, where TOOD achieves a 51.1 AP at single-model single-scale testing. This surpasses the recent one-stage detectors by a large margin, such as ATSS (47.7 AP), GFL (48.2 AP), and PAA (49.0 AP), with fewer parameters and FLOPs. Qualitative results also demonstrate the effectiveness of TOOD for better aligning the tasks of object classification and localization. Code is available at https://github.com/fcjian/TOOD.
Rethinking Deep Contrastive Learning with Embedding Memory
Mar 25, 2021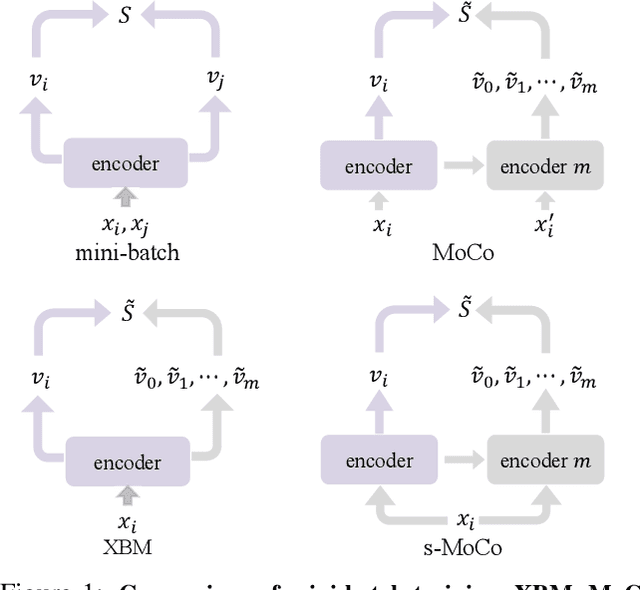

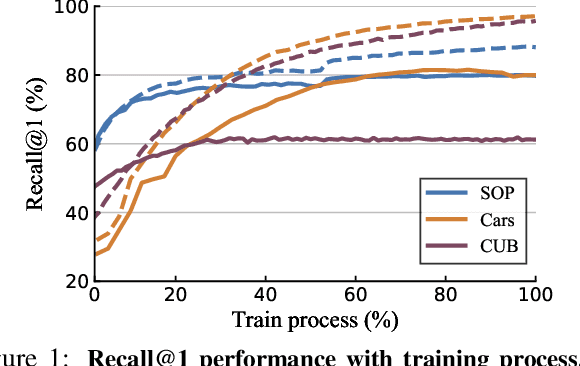
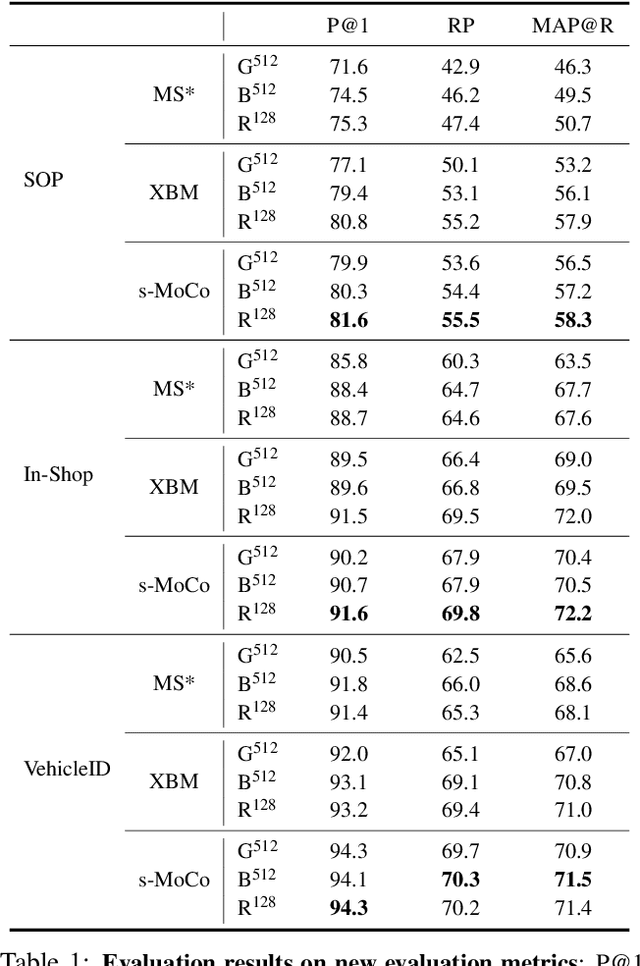
Pair-wise loss functions have been extensively studied and shown to continuously improve the performance of deep metric learning (DML). However, they are primarily designed with intuition based on simple toy examples, and experimentally identifying the truly effective design is difficult in complicated, real-world cases. In this paper, we provide a new methodology for systematically studying weighting strategies of various pair-wise loss functions, and rethink pair weighting with an embedding memory. We delve into the weighting mechanisms by decomposing the pair-wise functions, and study positive and negative weights separately using direct weight assignment. This allows us to study various weighting functions deeply and systematically via weight curves, and identify a number of meaningful, comprehensive and insightful facts, which come up with our key observation on memory-based DML: it is critical to mine hard negatives and discard easy negatives which are less informative and redundant, but weighting on positive pairs is not helpful. This results in an efficient but surprisingly simple rule to design the weighting scheme, making it significantly different from existing mini-batch based methods which design various sophisticated loss functions to weight pairs carefully. Finally, we conduct extensive experiments on three large-scale visual retrieval benchmarks, and demonstrate the superiority of memory-based DML over recent mini-batch based approaches, by using a simple contrastive loss with momentum-updated memory.
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021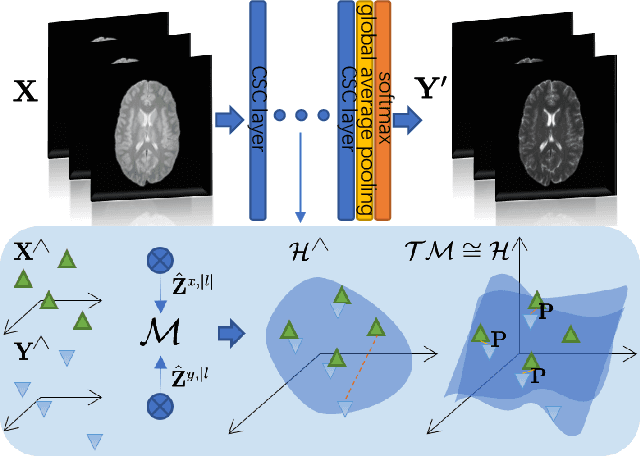
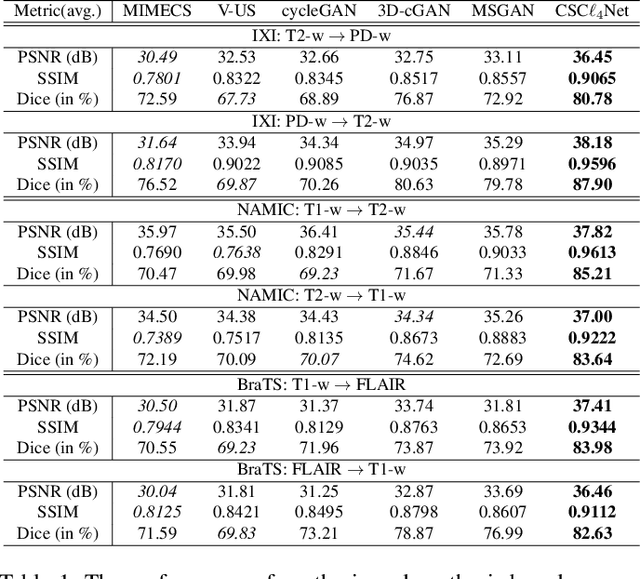
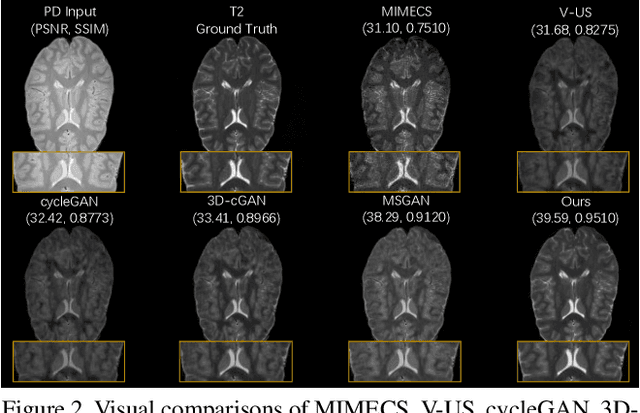
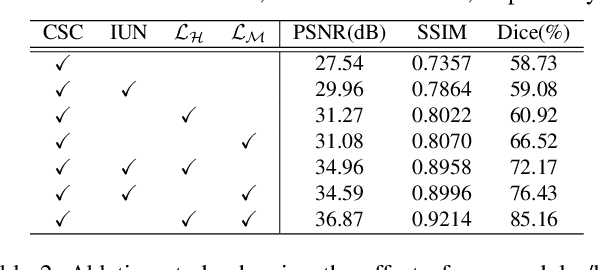
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.
Unchain the Search Space with Hierarchical Differentiable Architecture Search
Jan 12, 2021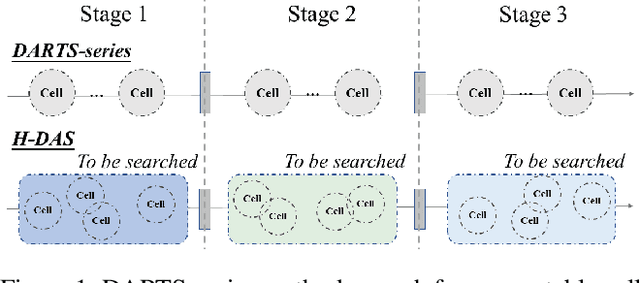
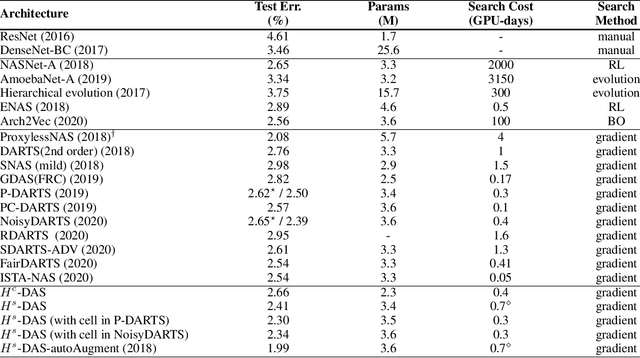
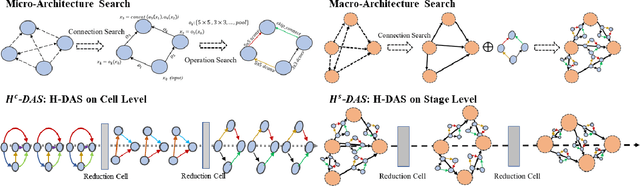
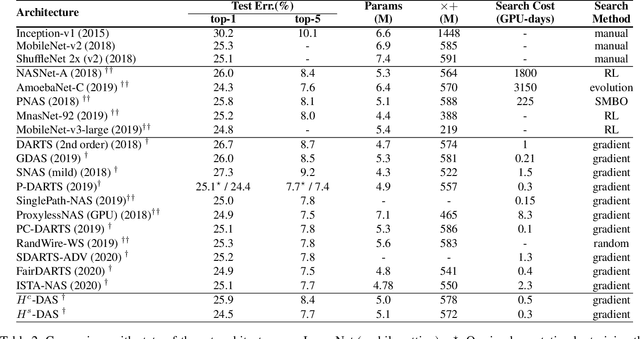
Differentiable architecture search (DAS) has made great progress in searching for high-performance architectures with reduced computational cost. However, DAS-based methods mainly focus on searching for a repeatable cell structure, which is then stacked sequentially in multiple stages to form the networks. This configuration significantly reduces the search space, and ignores the importance of connections between the cells. To overcome this limitation, in this paper, we propose a Hierarchical Differentiable Architecture Search (H-DAS) that performs architecture search both at the cell level and at the stage level. Specifically, the cell-level search space is relaxed so that the networks can learn stage-specific cell structures. For the stage-level search, we systematically study the architectures of stages, including the number of cells in each stage and the connections between the cells. Based on insightful observations, we design several search rules and losses, and mange to search for better stage-level architectures. Such hierarchical search space greatly improves the performance of the networks without introducing expensive search cost. Extensive experiments on CIFAR10 and ImageNet demonstrate the effectiveness of the proposed H-DAS. Moreover, the searched stage-level architectures can be combined with the cell structures searched by existing DAS methods to further boost the performance. Code is available at: https://github.com/MalongTech/research-HDAS
Representation Sharing for Fast Object Detector Search and Beyond
Jul 23, 2020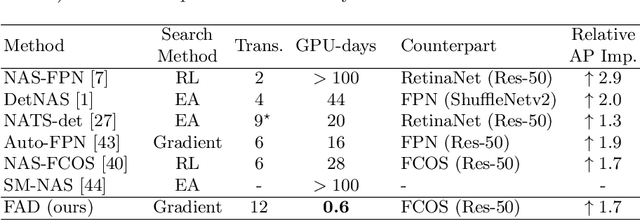
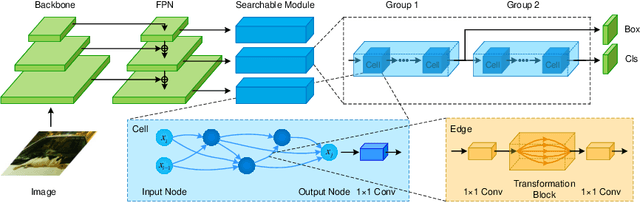
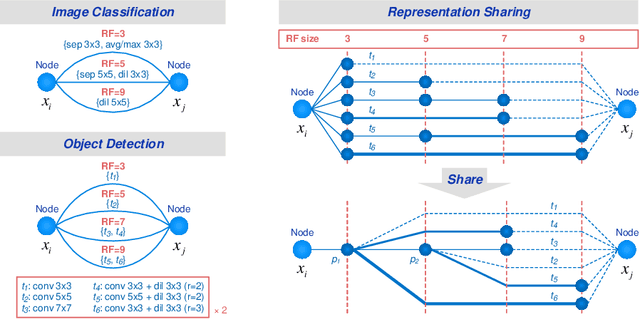
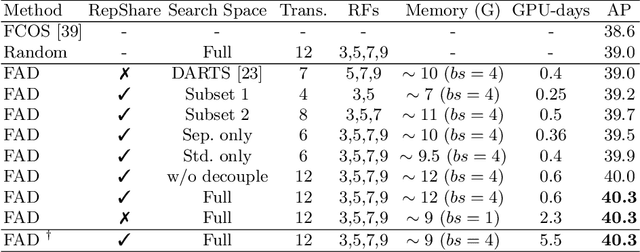
Region Proposal Network (RPN) provides strong support for handling the scale variation of objects in two-stage object detection. For one-stage detectors which do not have RPN, it is more demanding to have powerful sub-networks capable of directly capturing objects of unknown sizes. To enhance such capability, we propose an extremely efficient neural architecture search method, named Fast And Diverse (FAD), to better explore the optimal configuration of receptive fields and convolution types in the sub-networks for one-stage detectors. FAD consists of a designed search space and an efficient architecture search algorithm. The search space contains a rich set of diverse transformations designed specifically for object detection. To cope with the designed search space, a novel search algorithm termed Representation Sharing (RepShare) is proposed to effectively identify the best combinations of the defined transformations. In our experiments, FAD obtains prominent improvements on two types of one-stage detectors with various backbones. In particular, our FAD detector achieves 46.4 AP on MS-COCO (under single-scale testing), outperforming the state-of-the-art detectors, including the most recent NAS-based detectors, Auto-FPN (searched for 16 GPU-days) and NAS-FCOS (28 GPU-days), while significantly reduces the search cost to 0.6 GPU-days. Beyond object detection, we further demonstrate the generality of FAD on the more challenging instance segmentation, and expect it to benefit more tasks.
Deformable Siamese Attention Networks for Visual Object Tracking
Apr 14, 2020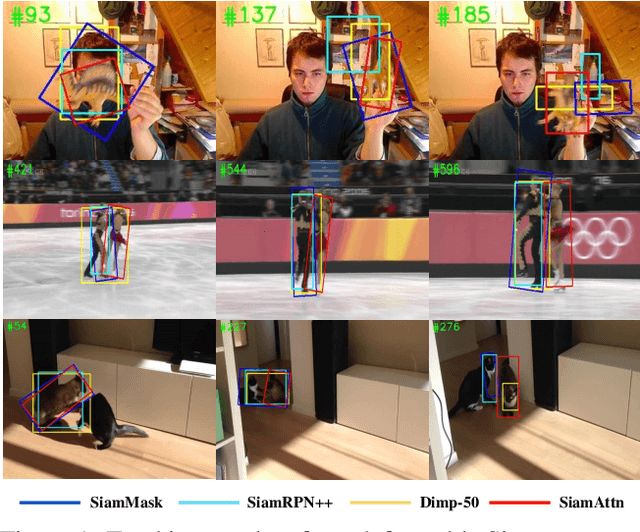
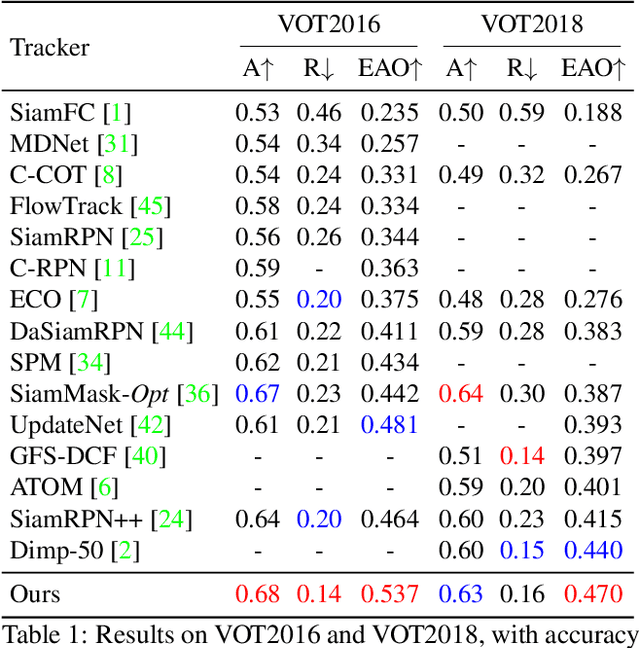
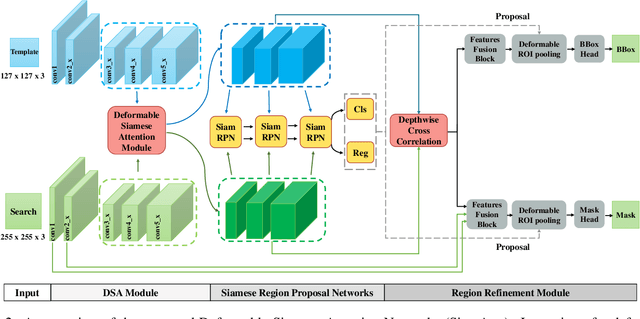
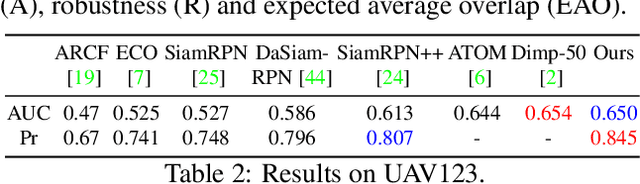
Siamese-based trackers have achieved excellent performance on visual object tracking. However, the target template is not updated online, and the features of the target template and search image are computed independently in a Siamese architecture. In this paper, we propose Deformable Siamese Attention Networks, referred to as SiamAttn, by introducing a new Siamese attention mechanism that computes deformable self-attention and cross-attention. The self attention learns strong context information via spatial attention, and selectively emphasizes interdependent channel-wise features with channel attention. The cross-attention is capable of aggregating rich contextual inter-dependencies between the target template and the search image, providing an implicit manner to adaptively update the target template. In addition, we design a region refinement module that computes depth-wise cross correlations between the attentional features for more accurate tracking. We conduct experiments on six benchmarks, where our method achieves new state of-the-art results, outperforming the strong baseline, SiamRPN++ [24], by 0.464->0.537 and 0.415->0.470 EAO on VOT 2016 and 2018.
Channel Interaction Networks for Fine-Grained Image Categorization
Mar 11, 2020

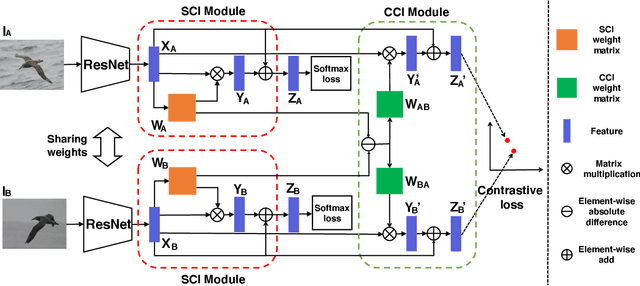
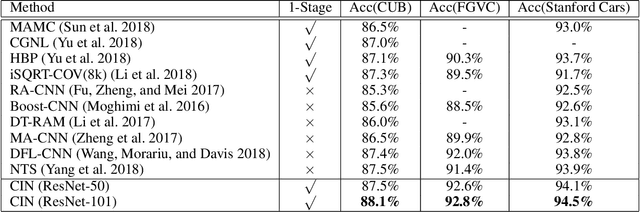
Fine-grained image categorization is challenging due to the subtle inter-class differences.We posit that exploiting the rich relationships between channels can help capture such differences since different channels correspond to different semantics. In this paper, we propose a channel interaction network (CIN), which models the channel-wise interplay both within an image and across images. For a single image, a self-channel interaction (SCI) module is proposed to explore channel-wise correlation within the image. This allows the model to learn the complementary features from the correlated channels, yielding stronger fine-grained features. Furthermore, given an image pair, we introduce a contrastive channel interaction (CCI) module to model the cross-sample channel interaction with a metric learning framework, allowing the CIN to distinguish the subtle visual differences between images. Our model can be trained efficiently in an end-to-end fashion without the need of multi-stage training and testing. Finally, comprehensive experiments are conducted on three publicly available benchmarks, where the proposed method consistently outperforms the state-of-theart approaches, such as DFL-CNN (Wang, Morariu, and Davis 2018) and NTS (Yang et al. 2018).
iFAN: Image-Instance Full Alignment Networks for Adaptive Object Detection
Mar 09, 2020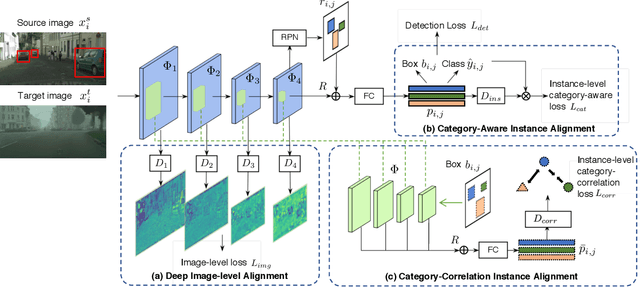
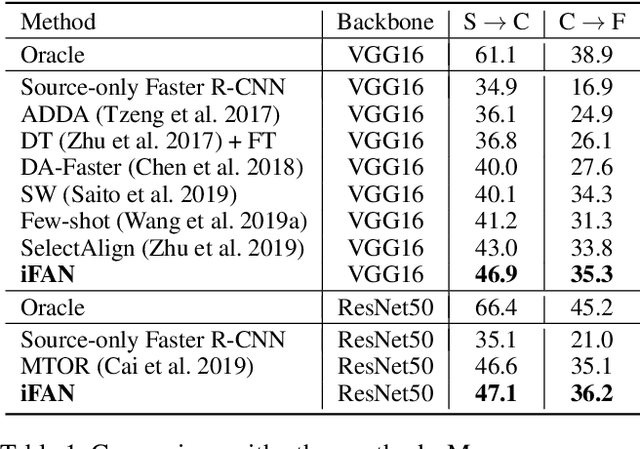
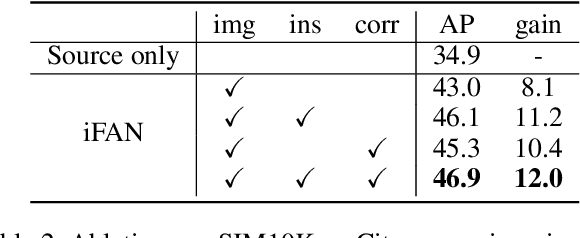

Training an object detector on a data-rich domain and applying it to a data-poor one with limited performance drop is highly attractive in industry, because it saves huge annotation cost. Recent research on unsupervised domain adaptive object detection has verified that aligning data distributions between source and target images through adversarial learning is very useful. The key is when, where and how to use it to achieve best practice. We propose Image-Instance Full Alignment Networks (iFAN) to tackle this problem by precisely aligning feature distributions on both image and instance levels: 1) Image-level alignment: multi-scale features are roughly aligned by training adversarial domain classifiers in a hierarchically-nested fashion. 2) Full instance-level alignment: deep semantic information and elaborate instance representations are fully exploited to establish a strong relationship among categories and domains. Establishing these correlations is formulated as a metric learning problem by carefully constructing instance pairs. Above-mentioned adaptations can be integrated into an object detector (e.g. Faster RCNN), resulting in an end-to-end trainable framework where multiple alignments can work collaboratively in a coarse-tofine manner. In two domain adaptation tasks: synthetic-to-real (SIM10K->Cityscapes) and normal-to-foggy weather (Cityscapes->Foggy Cityscapes), iFAN outperforms the state-of-the-art methods with a boost of 10%+ AP over the source-only baseline.
Knowledge Integration Networks for Action Recognition
Feb 18, 2020
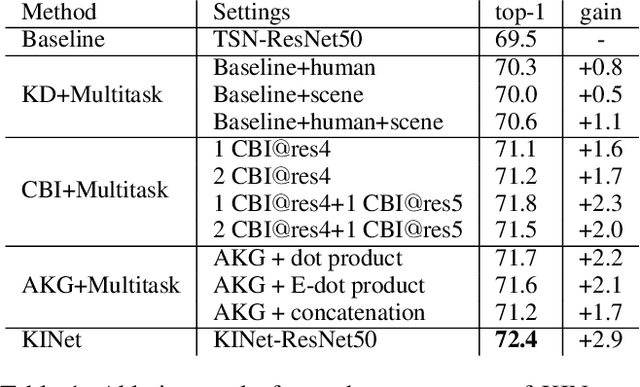
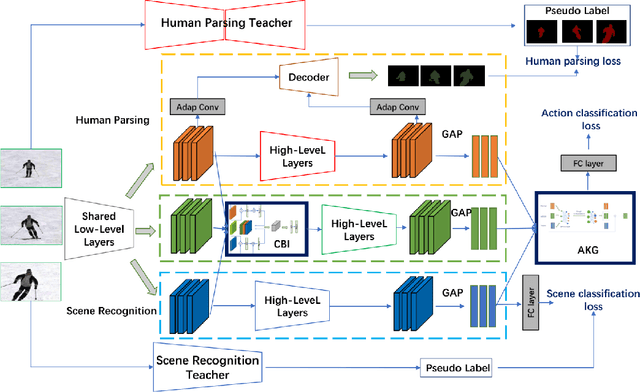
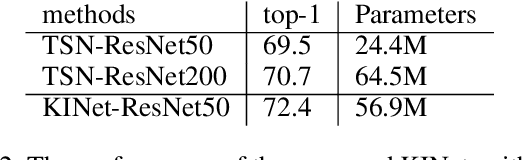
In this work, we propose Knowledge Integration Networks (referred as KINet) for video action recognition. KINet is capable of aggregating meaningful context features which are of great importance to identifying an action, such as human information and scene context. We design a three-branch architecture consisting of a main branch for action recognition, and two auxiliary branches for human parsing and scene recognition which allow the model to encode the knowledge of human and scene for action recognition. We explore two pre-trained models as teacher networks to distill the knowledge of human and scene for training the auxiliary tasks of KINet. Furthermore, we propose a two-level knowledge encoding mechanism which contains a Cross Branch Integration (CBI) module for encoding the auxiliary knowledge into medium-level convolutional features, and an Action Knowledge Graph (AKG) for effectively fusing high-level context information. This results in an end-to-end trainable framework where the three tasks can be trained collaboratively, allowing the model to compute strong context knowledge efficiently. The proposed KINet achieves the state-of-the-art performance on a large-scale action recognition benchmark Kinetics-400, with a top-1 accuracy of 77.8%. We further demonstrate that our KINet has strong capability by transferring the Kinetics-trained model to UCF-101, where it obtains 97.8% top-1 accuracy.
V4D:4D Convolutional Neural Networks for Video-level Representation Learning
Feb 18, 2020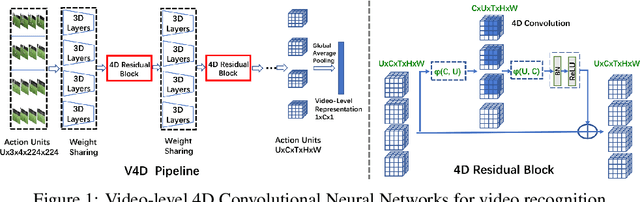

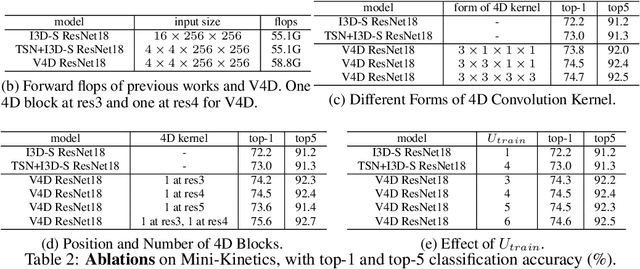
Most existing 3D CNNs for video representation learning are clip-based methods, and thus do not consider video-level temporal evolution of spatio-temporal features. In this paper, we propose Video-level 4D Convolutional Neural Networks, referred as V4D, to model the evolution of long-range spatio-temporal representation with 4D convolutions, and at the same time, to preserve strong 3D spatio-temporal representation with residual connections. Specifically, we design a new 4D residual block able to capture inter-clip interactions, which could enhance the representation power of the original clip-level 3D CNNs. The 4D residual blocks can be easily integrated into the existing 3D CNNs to perform long-range modeling hierarchically. We further introduce the training and inference methods for the proposed V4D. Extensive experiments are conducted on three video recognition benchmarks, where V4D achieves excellent results, surpassing recent 3D CNNs by a large margin.