 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalSUG: Geography-Aware LLM for Query Suggestion in Local-Life Services
Mar 05, 2026In local-life service platforms, the query suggestion module plays a crucial role in enhancing user experience by generating candidate queries based on user input prefixes, thus reducing user effort and accelerating search. Traditional multi-stage cascading systems rely heavily on historical top queries, limiting their ability to address long-tail demand. While LLMs offer strong semantic generalization, deploying them in local-life services introduces three key challenges: lack of geographic grounding, exposure bias in preference optimization, and online inference latency. To address these issues, we propose LocalSUG, an LLM-based query suggestion framework tailored for local-life service platforms. First, we introduce a city-aware candidate mining strategy based on term co-occurrence to inject geographic grounding into generation. Second, we propose a beam-search-driven GRPO algorithm that aligns training with inference-time decoding, reducing exposure bias in autoregressive generation. A multi-objective reward mechanism further optimizes both relevance and business-oriented metrics. Finally, we develop quality-aware beam acceleration and vocabulary pruning techniques that significantly reduce online latency while preserving generation quality. Extensive offline evaluations and large-scale online A/B testing demonstrate that LocalSUG improves click-through rate (CTR) by +0.35% and reduces the low/no-result rate by 2.56%, validating its effectiveness in real-world deployment.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
TeleStyle: Content-Preserving Style Transfer in Images and Videos
Jan 28, 2026Content-preserving style transfer, generating stylized outputs based on content and style references, remains a significant challenge for Diffusion Transformers (DiTs) due to the inherent entanglement of content and style features in their internal representations. In this technical report, we present TeleStyle, a lightweight yet effective model for both image and video stylization. Built upon Qwen-Image-Edit, TeleStyle leverages the base model's robust capabilities in content preservation and style customization. To facilitate effective training, we curated a high-quality dataset of distinct specific styles and further synthesized triplets using thousands of diverse, in-the-wild style categories. We introduce a Curriculum Continual Learning framework to train TeleStyle on this hybrid dataset of clean (curated) and noisy (synthetic) triplets. This approach enables the model to generalize to unseen styles without compromising precise content fidelity. Additionally, we introduce a video-to-video stylization module to enhance temporal consistency and visual quality. TeleStyle achieves state-of-the-art performance across three core evaluation metrics: style similarity, content consistency, and aesthetic quality. Code and pre-trained models are available at https://github.com/Tele-AI/TeleStyle
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
AviationLLM: An LLM-based Knowledge System for Aviation Training
Jun 17, 2025


Aviation training is a core link in ensuring flight safety, improving industry efficiency and promoting sustainable development. It not only involves flight simulation but also requires the learning of a great deal of professional aviation theory knowledge. In the existing training system, the knowledge is mainly imparted by the the instructors. However, the number of instructors is limited and the professional answers obtained from the Internet are not accurate enough, resulting in low training efficiency. To address this, we introduced LLM, but the basic pre-trained model cannot provide accurate answers to professional fields, so we fine-tuned it. Traditional Supervised Fine-Tuning (SFT) risk generating superficially plausible but factually incorrect responses due to insufficient data coverage. To address this, we employ Direct Preference Optimization(DPO). This paper proposes Retrieval-Augmented LLM Alignment via Direct Preference Optimization(RALA-DPO). We select open source pre-trained LLM Qwen and adapt it to aviation theory training through DPO-based domain alignment. Simultaneously, to mitigate hallucinations caused by training data biases, knowledge obsolescence, or domain knowledge gaps, we implement Retrieval-Augmented Generation(RAG) technology that combines generative and retrieval models. RALA-DPO effectively retrieves relevant information from external knowledge bases and delivers precise and high-quality responses through the generative model. Experimental results demonstrate that RALA-DPO can improve accuracy in response to professional aviation knowledge. With integrated RAG mechanisms, this system can further improve the accuracy of answers and achieve zero-cost knowledge updates simultaneously.
DreamO: A Unified Framework for Image Customization
Apr 23, 2025Recently, extensive research on image customization (e.g., identity, subject, style, background, etc.) demonstrates strong customization capabilities in large-scale generative models. However, most approaches are designed for specific tasks, restricting their generalizability to combine different types of condition. Developing a unified framework for image customization remains an open challenge. In this paper, we present DreamO, an image customization framework designed to support a wide range of tasks while facilitating seamless integration of multiple conditions. Specifically, DreamO utilizes a diffusion transformer (DiT) framework to uniformly process input of different types. During training, we construct a large-scale training dataset that includes various customization tasks, and we introduce a feature routing constraint to facilitate the precise querying of relevant information from reference images. Additionally, we design a placeholder strategy that associates specific placeholders with conditions at particular positions, enabling control over the placement of conditions in the generated results. Moreover, we employ a progressive training strategy consisting of three stages: an initial stage focused on simple tasks with limited data to establish baseline consistency, a full-scale training stage to comprehensively enhance the customization capabilities, and a final quality alignment stage to correct quality biases introduced by low-quality data. Extensive experiments demonstrate that the proposed DreamO can effectively perform various image customization tasks with high quality and flexibly integrate different types of control conditions.
Hyper-parameter tuning for text guided image editing
Jul 31, 2024The test-time finetuning text-guided image editing method, Forgedit, is capable of tackling general and complex image editing problems given only the input image itself and the target text prompt. During finetuning stage, using the same set of finetuning hyper-paramters every time for every given image, Forgedit remembers and understands the input image in 30 seconds. During editing stage, the workflow of Forgedit might seem complicated. However, in fact, the editing process of Forgedit is not more complex than previous SOTA Imagic, yet completely solves the overfitting problem of Imagic. In this paper, we will elaborate the workflow of Forgedit editing stage with examples. We will show how to tune the hyper-parameters in an efficient way to obtain ideal editing results.
Forgedit: Text Guided Image Editing via Learning and Forgetting
Sep 19, 2023



Text guided image editing on real images given only the image and the target text prompt as inputs, is a very general and challenging problem, which requires the editing model to reason by itself which part of the image should be edited, to preserve the characteristics of original image, and also to perform complicated non-rigid editing. Previous fine-tuning based solutions are time-consuming and vulnerable to overfitting, limiting their editing capabilities. To tackle these issues, we design a novel text guided image editing method, Forgedit. First, we propose a novel fine-tuning framework which learns to reconstruct the given image in less than one minute by vision language joint learning. Then we introduce vector subtraction and vector projection to explore the proper text embedding for editing. We also find a general property of UNet structures in Diffusion Models and inspired by such a finding, we design forgetting strategies to diminish the fatal overfitting issues and significantly boost the editing abilities of Diffusion Models. Our method, Forgedit, implemented with Stable Diffusion, achieves new state-of-the-art results on the challenging text guided image editing benchmark TEdBench, surpassing the previous SOTA method Imagic with Imagen, in terms of both CLIP score and LPIPS score. Codes are available at https://github.com/witcherofresearch/Forgedit.
TFCNet: Temporal Fully Connected Networks for Static Unbiased Temporal Reasoning
Mar 11, 2022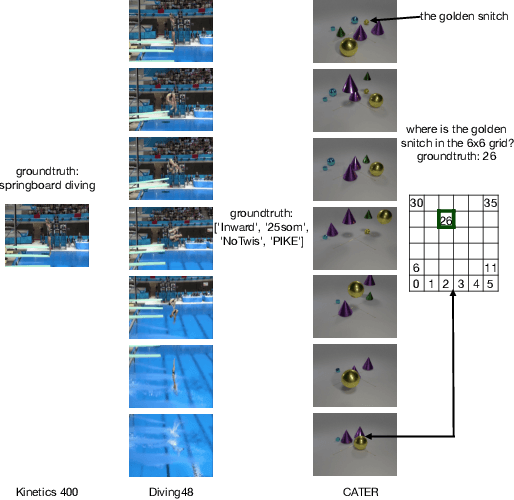
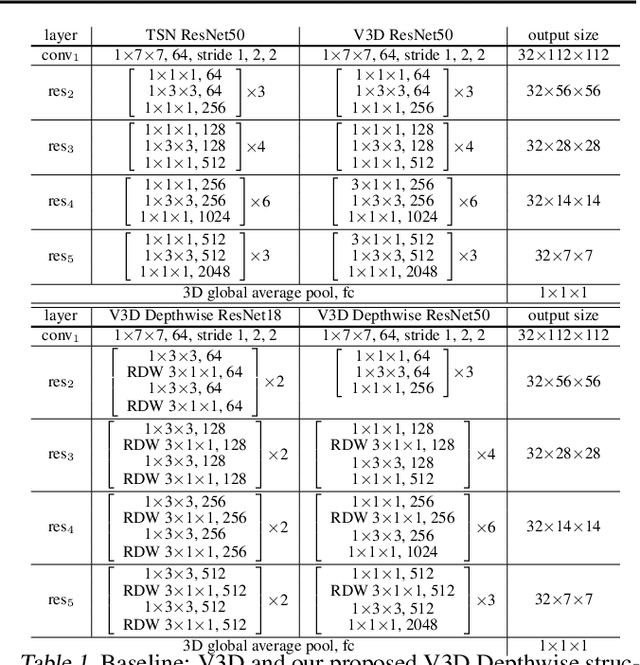
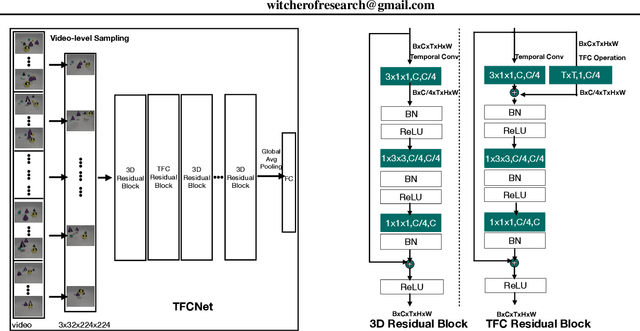

Temporal Reasoning is one important functionality for vision intelligence. In computer vision research community, temporal reasoning is usually studied in the form of video classification, for which many state-of-the-art Neural Network structures and dataset benchmarks are proposed in recent years, especially 3D CNNs and Kinetics. However, some recent works found that current video classification benchmarks contain strong biases towards static features, thus cannot accurately reflect the temporal modeling ability. New video classification benchmarks aiming to eliminate static biases are proposed, with experiments on these new benchmarks showing that the current clip-based 3D CNNs are outperformed by RNN structures and recent video transformers. In this paper, we find that 3D CNNs and their efficient depthwise variants, when video-level sampling strategy is used, are actually able to beat RNNs and recent vision transformers by significant margins on static-unbiased temporal reasoning benchmarks. Further, we propose Temporal Fully Connected Block (TFC Block), an efficient and effective component, which approximates fully connected layers along temporal dimension to obtain video-level receptive field, enhancing the spatiotemporal reasoning ability. With TFC blocks inserted into Video-level 3D CNNs (V3D), our proposed TFCNets establish new state-of-the-art results on synthetic temporal reasoning benchmark, CATER, and real world static-unbiased dataset, Diving48, surpassing all previous methods.
Knowledge Integration Networks for Action Recognition
Feb 18, 2020
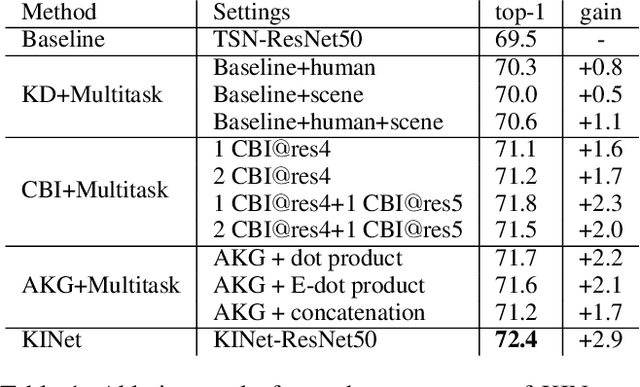
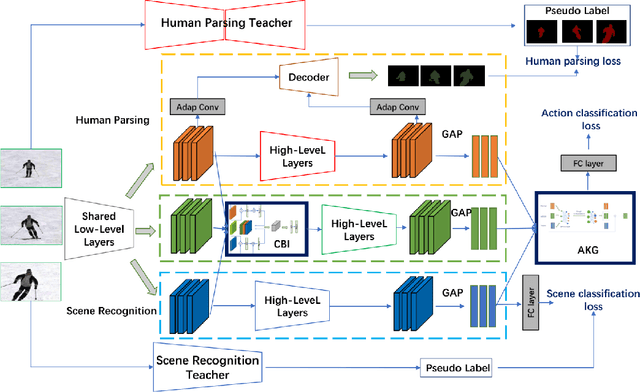
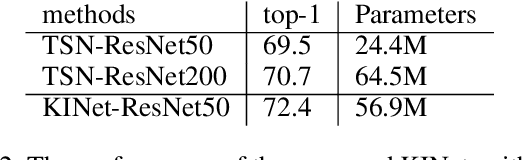
In this work, we propose Knowledge Integration Networks (referred as KINet) for video action recognition. KINet is capable of aggregating meaningful context features which are of great importance to identifying an action, such as human information and scene context. We design a three-branch architecture consisting of a main branch for action recognition, and two auxiliary branches for human parsing and scene recognition which allow the model to encode the knowledge of human and scene for action recognition. We explore two pre-trained models as teacher networks to distill the knowledge of human and scene for training the auxiliary tasks of KINet. Furthermore, we propose a two-level knowledge encoding mechanism which contains a Cross Branch Integration (CBI) module for encoding the auxiliary knowledge into medium-level convolutional features, and an Action Knowledge Graph (AKG) for effectively fusing high-level context information. This results in an end-to-end trainable framework where the three tasks can be trained collaboratively, allowing the model to compute strong context knowledge efficiently. The proposed KINet achieves the state-of-the-art performance on a large-scale action recognition benchmark Kinetics-400, with a top-1 accuracy of 77.8%. We further demonstrate that our KINet has strong capability by transferring the Kinetics-trained model to UCF-101, where it obtains 97.8% top-1 accuracy.