 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsCLR: Improving Instance Retrieval with Self-Supervision
Dec 02, 2021


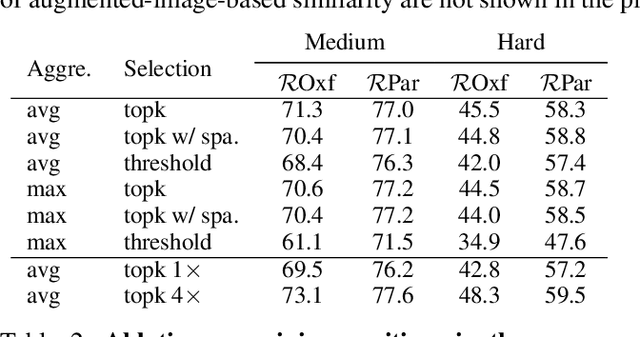
This work aims at improving instance retrieval with self-supervision. We find that fine-tuning using the recently developed self-supervised (SSL) learning methods, such as SimCLR and MoCo, fails to improve the performance of instance retrieval. In this work, we identify that the learnt representations for instance retrieval should be invariant to large variations in viewpoint and background etc., whereas self-augmented positives applied by the current SSL methods can not provide strong enough signals for learning robust instance-level representations. To overcome this problem, we propose InsCLR, a new SSL method that builds on the \textit{instance-level} contrast, to learn the intra-class invariance by dynamically mining meaningful pseudo positive samples from both mini-batches and a memory bank during training. Extensive experiments demonstrate that InsCLR achieves similar or even better performance than the state-of-the-art SSL methods on instance retrieval. Code is available at https://github.com/zeludeng/insclr.
Multi Receptive Field Network for Semantic Segmentation
Nov 17, 2020
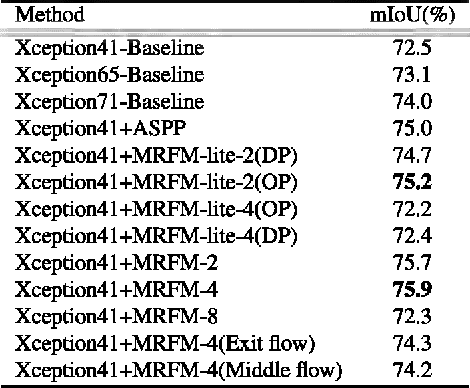


Semantic segmentation is one of the key tasks in computer vision, which is to assign a category label to each pixel in an image. Despite significant progress achieved recently, most existing methods still suffer from two challenging issues: 1) the size of objects and stuff in an image can be very diverse, demanding for incorporating multi-scale features into the fully convolutional networks (FCNs); 2) the pixels close to or at the boundaries of object/stuff are hard to classify due to the intrinsic weakness of convolutional networks. To address the first issue, we propose a new Multi-Receptive Field Module (MRFM), explicitly taking multi-scale features into account. For the second issue, we design an edge-aware loss which is effective in distinguishing the boundaries of object/stuff. With these two designs, our Multi Receptive Field Network achieves new state-of-the-art results on two widely-used semantic segmentation benchmark datasets. Specifically, we achieve a mean IoU of 83.0 on the Cityscapes dataset and 88.4 mean IoU on the Pascal VOC2012 dataset.
Representation Sharing for Fast Object Detector Search and Beyond
Jul 23, 2020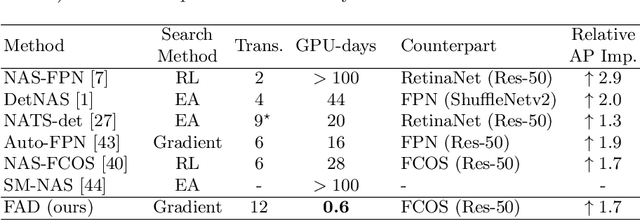
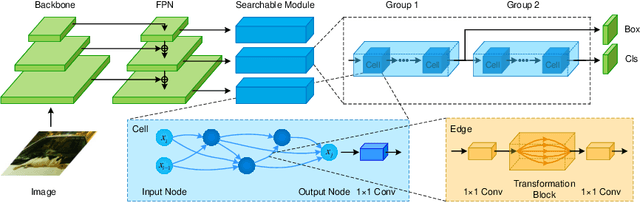
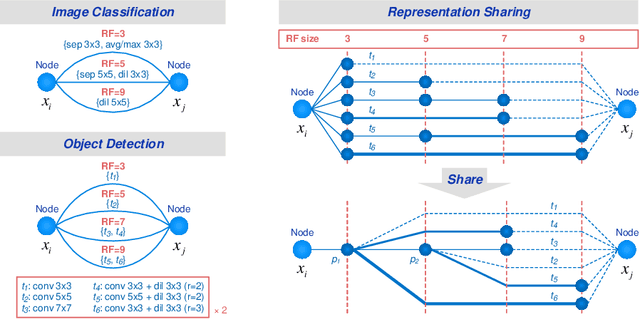
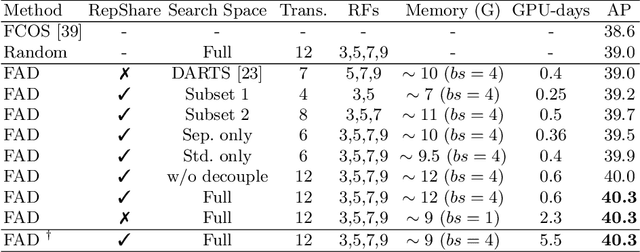
Region Proposal Network (RPN) provides strong support for handling the scale variation of objects in two-stage object detection. For one-stage detectors which do not have RPN, it is more demanding to have powerful sub-networks capable of directly capturing objects of unknown sizes. To enhance such capability, we propose an extremely efficient neural architecture search method, named Fast And Diverse (FAD), to better explore the optimal configuration of receptive fields and convolution types in the sub-networks for one-stage detectors. FAD consists of a designed search space and an efficient architecture search algorithm. The search space contains a rich set of diverse transformations designed specifically for object detection. To cope with the designed search space, a novel search algorithm termed Representation Sharing (RepShare) is proposed to effectively identify the best combinations of the defined transformations. In our experiments, FAD obtains prominent improvements on two types of one-stage detectors with various backbones. In particular, our FAD detector achieves 46.4 AP on MS-COCO (under single-scale testing), outperforming the state-of-the-art detectors, including the most recent NAS-based detectors, Auto-FPN (searched for 16 GPU-days) and NAS-FCOS (28 GPU-days), while significantly reduces the search cost to 0.6 GPU-days. Beyond object detection, we further demonstrate the generality of FAD on the more challenging instance segmentation, and expect it to benefit more tasks.