 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Deep Contrastive Learning with Embedding Memory
Mar 25, 2021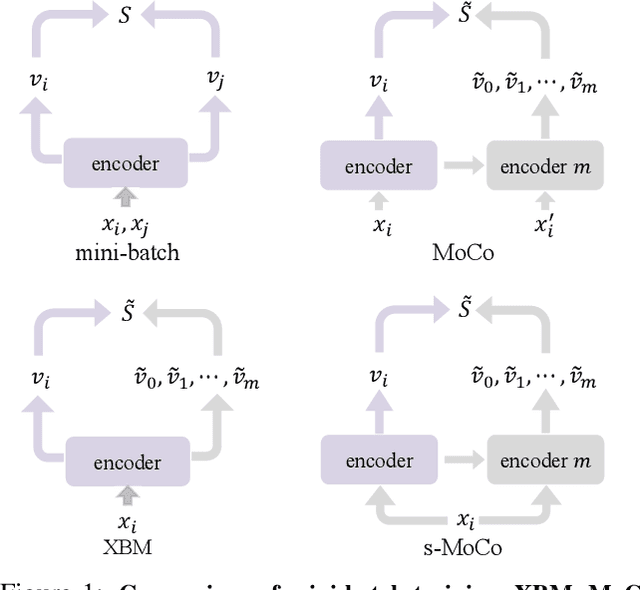

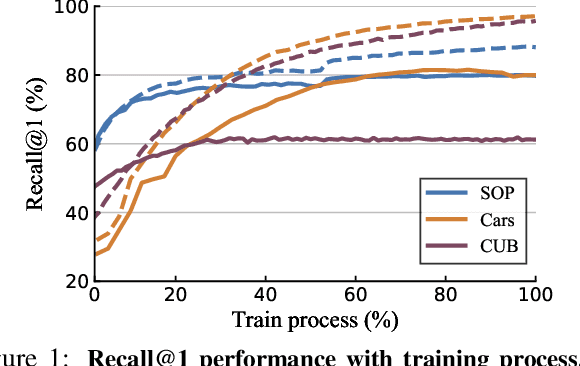
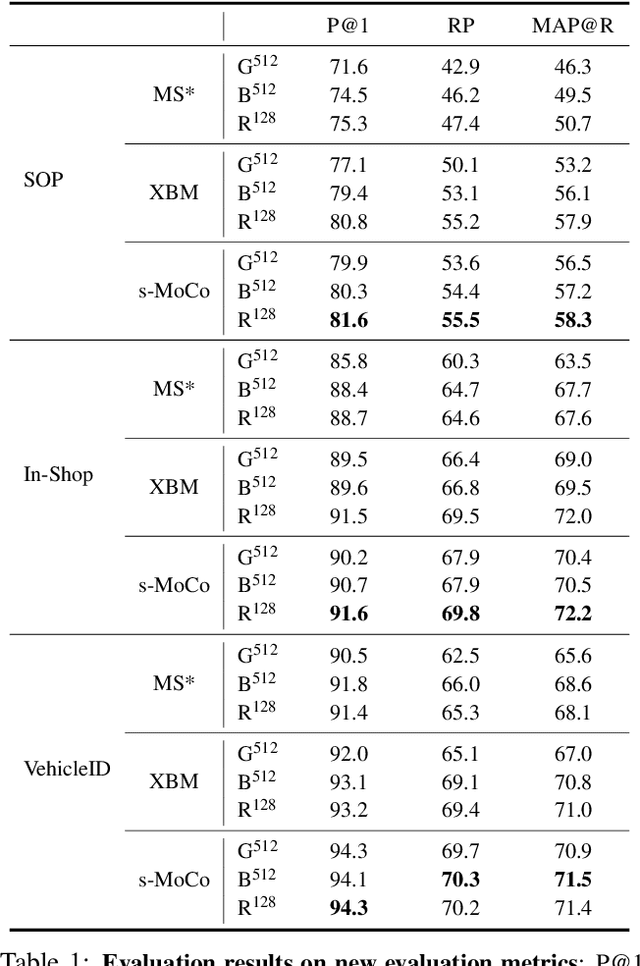
Pair-wise loss functions have been extensively studied and shown to continuously improve the performance of deep metric learning (DML). However, they are primarily designed with intuition based on simple toy examples, and experimentally identifying the truly effective design is difficult in complicated, real-world cases. In this paper, we provide a new methodology for systematically studying weighting strategies of various pair-wise loss functions, and rethink pair weighting with an embedding memory. We delve into the weighting mechanisms by decomposing the pair-wise functions, and study positive and negative weights separately using direct weight assignment. This allows us to study various weighting functions deeply and systematically via weight curves, and identify a number of meaningful, comprehensive and insightful facts, which come up with our key observation on memory-based DML: it is critical to mine hard negatives and discard easy negatives which are less informative and redundant, but weighting on positive pairs is not helpful. This results in an efficient but surprisingly simple rule to design the weighting scheme, making it significantly different from existing mini-batch based methods which design various sophisticated loss functions to weight pairs carefully. Finally, we conduct extensive experiments on three large-scale visual retrieval benchmarks, and demonstrate the superiority of memory-based DML over recent mini-batch based approaches, by using a simple contrastive loss with momentum-updated memory.
Cross-Batch Memory for Embedding Learning
Dec 14, 2019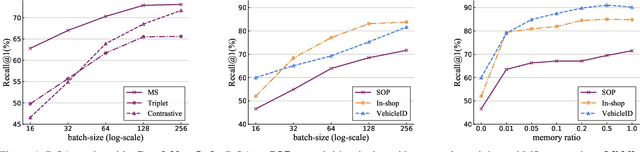

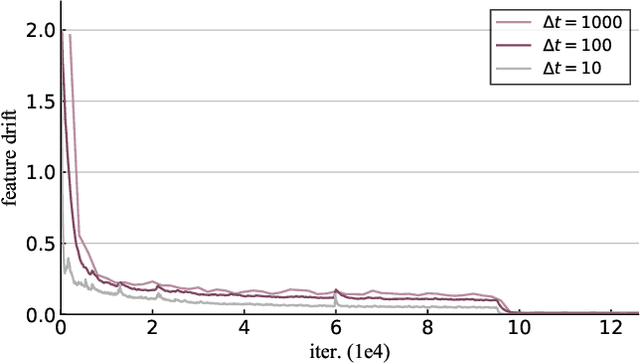
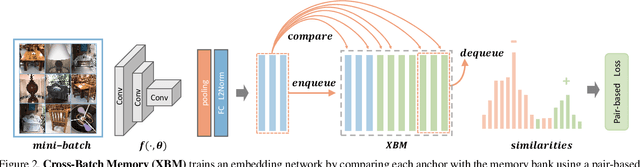
Mining informative negative instances are of central importance to deep metric learning (DML). However, the hard-mining ability of existing DML methods is intrinsically limited by mini-batch training, where only a mini-batch of instances are accessible at each iteration. In this paper, we identify a {"slow drift"} phenomena by observing that the embedding features drift exceptionally slow even as the model parameters are updating throughout the training process. It suggests that the features of instances computed at preceding iterations can considerably approximate to their features extracted by current model. We propose a cross-batch memory (XBM) mechanism that memorizes the embeddings of past iterations, allowing the model to collect sufficient hard negative pairs across multiple mini-batches - even over the whole dataset. Our XBM can be directly integrated into general pair-based DML framework. We demonstrate that, without bells and whistles, XBM augmented DML can boost the performance considerably on image retrieval. In particular, with XBM, a simple contrastive loss can have large R@1 improvements of 12\%-22.5\% on three large-scale datasets, easily surpassing the most sophisticated state-of-the-art methods by a large margin. Our XBM is conceptually simple, easy to implement - using several lines of codes, and is memory efficient - with a negligible 0.2 GB extra GPU memory.
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
Oct 18, 2018
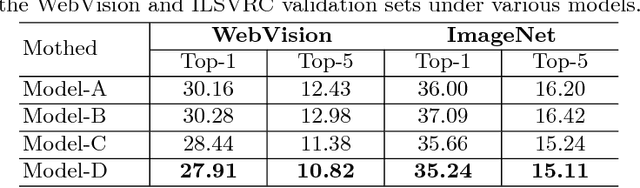
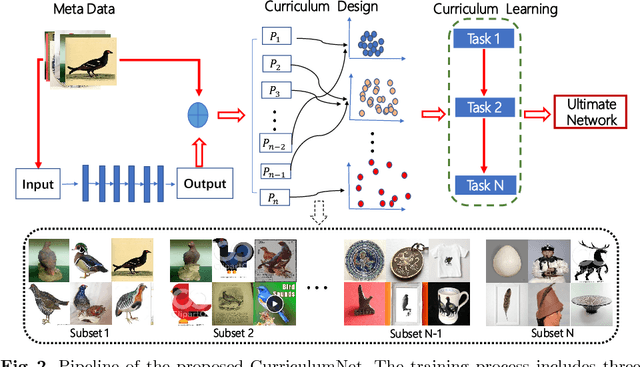

We present a simple yet efficient approach capable of training deep neural networks on large-scale weakly-supervised web images, which are crawled raw from the Internet by using text queries, without any human annotation. We develop a principled learning strategy by leveraging curriculum learning, with the goal of handling a massive amount of noisy labels and data imbalance effectively. We design a new learning curriculum by measuring the complexity of data using its distribution density in a feature space, and rank the complexity in an unsupervised manner. This allows for an efficient implementation of curriculum learning on large-scale web images, resulting in a high-performance CNN model, where the negative impact of noisy labels is reduced substantially. Importantly, we show by experiments that those images with highly noisy labels can surprisingly improve the generalization capability of the model, by serving as a manner of regularization. Our approaches obtain state-of-the-art performance on four benchmarks: WebVision, ImageNet, Clothing-1M and Food-101. With an ensemble of multiple models, we achieved a top-5 error rate of 5.2% on the WebVision challenge for 1000-category classification. This result was the top performance by a wide margin, outperforming second place by a nearly 50% relative error rate. Code and models are available at: https://github.com/MalongTech/CurriculumNet .