 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Batch Memory for Embedding Learning
Paper and Code
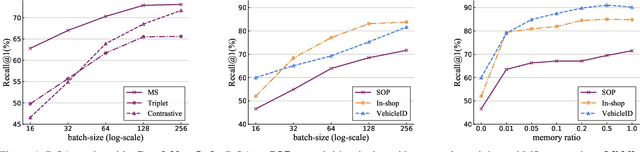

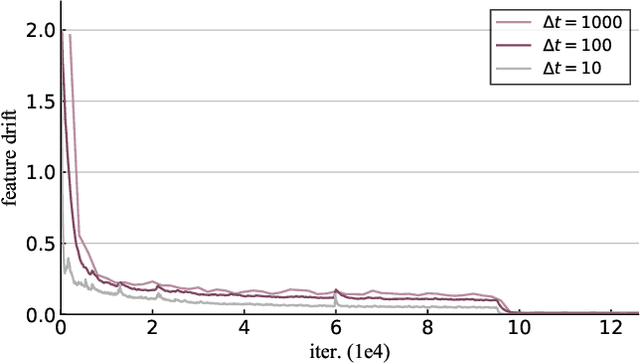
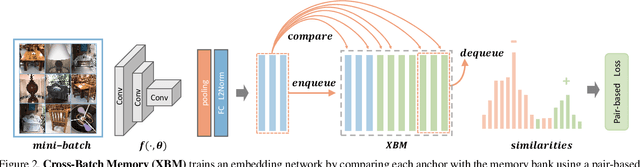
Mining informative negative instances are of central importance to deep metric learning (DML). However, the hard-mining ability of existing DML methods is intrinsically limited by mini-batch training, where only a mini-batch of instances are accessible at each iteration. In this paper, we identify a {"slow drift"} phenomena by observing that the embedding features drift exceptionally slow even as the model parameters are updating throughout the training process. It suggests that the features of instances computed at preceding iterations can considerably approximate to their features extracted by current model. We propose a cross-batch memory (XBM) mechanism that memorizes the embeddings of past iterations, allowing the model to collect sufficient hard negative pairs across multiple mini-batches - even over the whole dataset. Our XBM can be directly integrated into general pair-based DML framework. We demonstrate that, without bells and whistles, XBM augmented DML can boost the performance considerably on image retrieval. In particular, with XBM, a simple contrastive loss can have large R@1 improvements of 12\%-22.5\% on three large-scale datasets, easily surpassing the most sophisticated state-of-the-art methods by a large margin. Our XBM is conceptually simple, easy to implement - using several lines of codes, and is memory efficient - with a negligible 0.2 GB extra GPU memory.