 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review on Prompt Engineering in Large Language Models for K-12 STEM Education
Oct 14, 2024
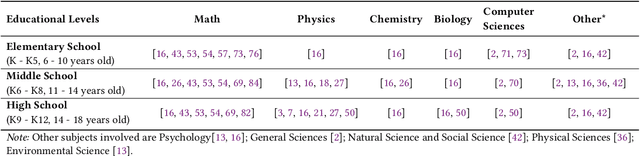
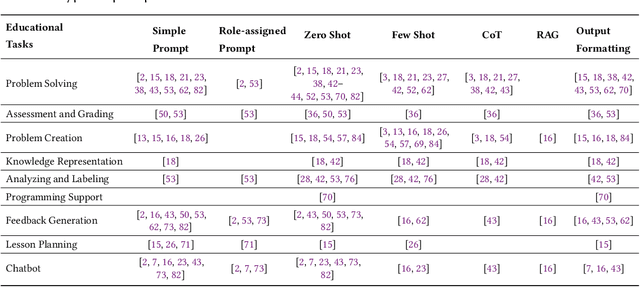
Large language models (LLMs) have the potential to enhance K-12 STEM education by improving both teaching and learning processes. While previous studies have shown promising results, there is still a lack of comprehensive understanding regarding how LLMs are effectively applied, specifically through prompt engineering-the process of designing prompts to generate desired outputs. To address this gap, our study investigates empirical research published between 2021 and 2024 that explores the use of LLMs combined with prompt engineering in K-12 STEM education. Following the PRISMA protocol, we screened 2,654 papers and selected 30 studies for analysis. Our review identifies the prompting strategies employed, the types of LLMs used, methods of evaluating effectiveness, and limitations in prior work. Results indicate that while simple and zero-shot prompting are commonly used, more advanced techniques like few-shot and chain-of-thought prompting have demonstrated positive outcomes for various educational tasks. GPT-series models are predominantly used, but smaller and fine-tuned models (e.g., Blender 7B) paired with effective prompt engineering outperform prompting larger models (e.g., GPT-3) in specific contexts. Evaluation methods vary significantly, with limited empirical validation in real-world settings.
Pessimistic Causal Reinforcement Learning with Mediators for Confounded Offline Data
Mar 18, 2024



In real-world scenarios, datasets collected from randomized experiments are often constrained by size, due to limitations in time and budget. As a result, leveraging large observational datasets becomes a more attractive option for achieving high-quality policy learning. However, most existing offline reinforcement learning (RL) methods depend on two key assumptions--unconfoundedness and positivity--which frequently do not hold in observational data contexts. Recognizing these challenges, we propose a novel policy learning algorithm, PESsimistic CAusal Learning (PESCAL). We utilize the mediator variable based on front-door criterion to remove the confounding bias; additionally, we adopt the pessimistic principle to address the distributional shift between the action distributions induced by candidate policies, and the behavior policy that generates the observational data. Our key observation is that, by incorporating auxiliary variables that mediate the effect of actions on system dynamics, it is sufficient to learn a lower bound of the mediator distribution function, instead of the Q-function, to partially mitigate the issue of distributional shift. This insight significantly simplifies our algorithm, by circumventing the challenging task of sequential uncertainty quantification for the estimated Q-function. Moreover, we provide theoretical guarantees for the algorithms we propose, and demonstrate their efficacy through simulations, as well as real-world experiments utilizing offline datasets from a leading ride-hailing platform.
SUGAR: Spherical Ultrafast Graph Attention Framework for Cortical Surface Registration
Jul 02, 2023



Cortical surface registration plays a crucial role in aligning cortical functional and anatomical features across individuals. However, conventional registration algorithms are computationally inefficient. Recently, learning-based registration algorithms have emerged as a promising solution, significantly improving processing efficiency. Nonetheless, there remains a gap in the development of a learning-based method that exceeds the state-of-the-art conventional methods simultaneously in computational efficiency, registration accuracy, and distortion control, despite the theoretically greater representational capabilities of deep learning approaches. To address the challenge, we present SUGAR, a unified unsupervised deep-learning framework for both rigid and non-rigid registration. SUGAR incorporates a U-Net-based spherical graph attention network and leverages the Euler angle representation for deformation. In addition to the similarity loss, we introduce fold and multiple distortion losses, to preserve topology and minimize various types of distortions. Furthermore, we propose a data augmentation strategy specifically tailored for spherical surface registration, enhancing the registration performance. Through extensive evaluation involving over 10,000 scans from 7 diverse datasets, we showed that our framework exhibits comparable or superior registration performance in accuracy, distortion, and test-retest reliability compared to conventional and learning-based methods. Additionally, SUGAR achieves remarkable sub-second processing times, offering a notable speed-up of approximately 12,000 times in registering 9,000 subjects from the UK Biobank dataset in just 32 minutes. This combination of high registration performance and accelerated processing time may greatly benefit large-scale neuroimaging studies.
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021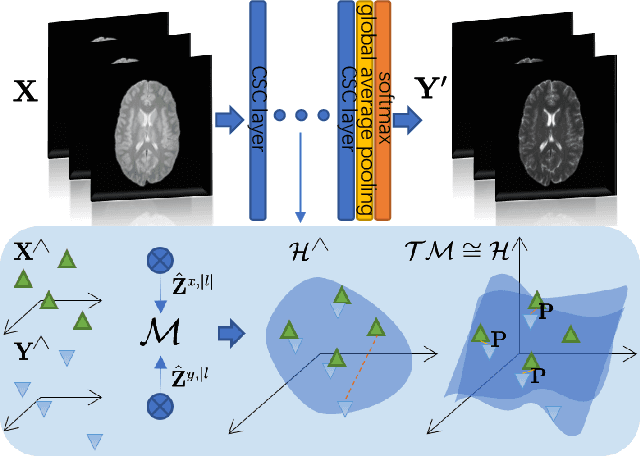
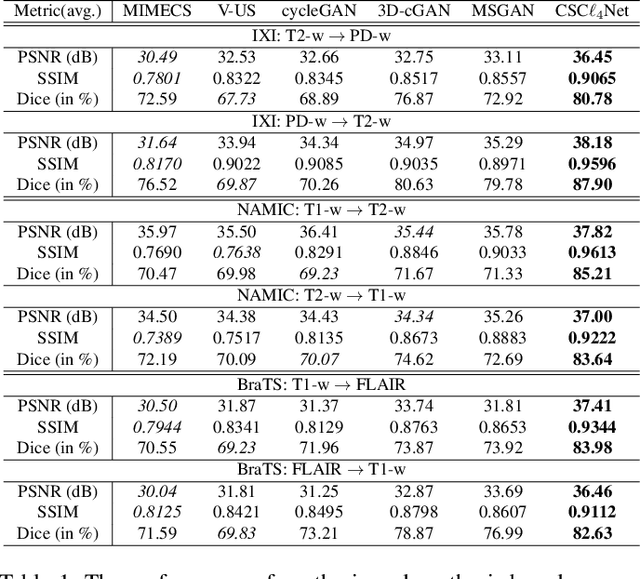
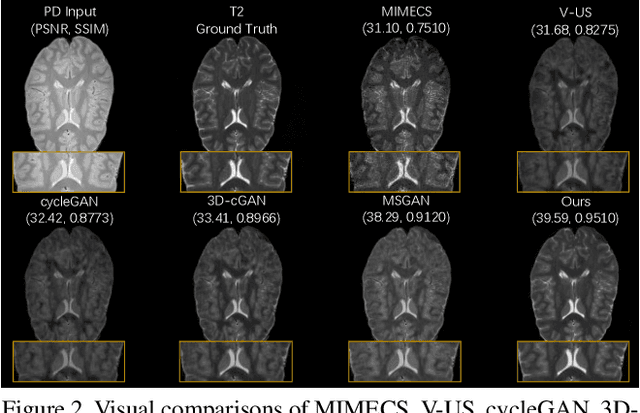
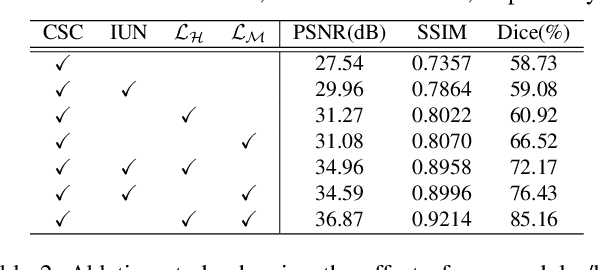
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.