 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should Memory Stay Silent: Measuring Memory-Use Boundaries in Memory-Augmented Conversational Agents
Jun 04, 2026Long-term memory enables language model agents to support personalized interactions, but it remains unclear when available memories warrant integration into responses. Existing memory evaluations emphasize retrieval accuracy and downstream task utility, while overlooking whether retrieved sensitive memory content is warranted in the current turn. We introduce RBI-Eval, a controlled measurement study built around a probe set that compares model behavior with and without access to sensitive memory under identical benign prompts. We evaluate four base LLMs against a matched no-memory reference across four memory-access settings: full-context exposure and three retrieval systems. Our results reveal substantial behavioral divergence. With memory available, the separation score for sensitive-memory integration decreases by 8.9\%--26.6\% relative to the matched no-memory reference for GPT-5.4-mini, but by 51.1\%--82.9\% for Claude-Sonnet-4.6, DeepSeek-V4-Flash, and Qwen3.5-9B. Control experiments on DeepSeek and GPT-5.4-mini show this effect is specific to sensitive content, rather than general personalization. Retrieval systems reduce exposure but do not eliminate integration once sensitive memory reaches the generator. These findings suggest safe personalization requires memory-aware decisions at both retrieval and generation time.
Let Robots Feel Your Touch: Visuo-Tactile Cortical Alignment for Embodied Mirror Resonance
May 14, 2026Observing touch on another's body can elicit corresponding tactile sensations in the observer, a phenomenon termed mirror touch that supports empathy and social perception. This visuo-tactile resonance is thought to rely on structural correspondence between visual and somatosensory cortices, yet robotic systems lack computational frameworks that instantiate this principle. Here we demonstrate that cortical correspondence can be operationalized to endow robots with mirror touch. We introduce Mirror Touch Net, which imposes semantic, distributional and geometric alignment between visual and tactile representations through multi-level constraints, enabling prediction of millimetre-scale tactile signals across 1,140 taxels on a robotic hand from RGB images. Manifold analysis reveals that these constraints reshape visual representations into geometry consistent with the tactile manifold, reducing the complexity of cross-modal mapping. Extending this alignment framework to cross-domain observations of human hands enables tactile prediction and reflexive responses to observed human touch. Our results link a neural principle of visuo-tactile resonance to robotic perception, providing an explainable route towards anticipatory touch and empathic human-robot interaction. Code is available at https://github.com/fun0515/Mirror-Touch-Net.
Search Multilayer Perceptron-Based Fusion for Efficient and Accurate Siamese Tracking
Mar 02, 2026Siamese visual trackers have recently advanced through increasingly sophisticated fusion mechanisms built on convolutional or Transformer architectures. However, both struggle to deliver pixel-level interactions efficiently on resource-constrained hardware, leading to a persistent accuracy-efficiency imbalance. Motivated by this limitation, we redesign the Siamese neck with a simple yet effective Multilayer Perception (MLP)-based fusion module that enables pixel-level interaction with minimal structural overhead. Nevertheless, naively stacking MLP blocks introduces a new challenge: computational cost can scale quadratically with channel width. To overcome this, we construct a hierarchical search space of carefully designed MLP modules and introduce a customized relaxation strategy that enables differentiable neural architecture search (DNAS) to decouple channel-width optimization from other architectural choices. This targeted decoupling automatically balances channel width and depth, yielding a low-complexity architecture. The resulting tracker achieves state-of-the-art accuracy-efficiency trade-offs. It ranks among the top performers on four general-purpose and three aerial tracking benchmarks, while maintaining real-time performance on both resource-constrained Graphics Processing Units (GPUs) and Neural Processing Units (NPUs).
GSM-GS: Geometry-Constrained Single and Multi-view Gaussian Splatting for Surface Reconstruction
Feb 13, 2026Recently, 3D Gaussian Splatting has emerged as a prominent research direction owing to its ultrarapid training speed and high-fidelity rendering capabilities. However, the unstructured and irregular nature of Gaussian point clouds poses challenges to reconstruction accuracy. This limitation frequently causes high-frequency detail loss in complex surface microstructures when relying solely on routine strategies. To address this limitation, we propose GSM-GS: a synergistic optimization framework integrating single-view adaptive sub-region weighting constraints and multi-view spatial structure refinement. For single-view optimization, we leverage image gradient features to partition scenes into texture-rich and texture-less sub-regions. The reconstruction quality is enhanced through adaptive filtering mechanisms guided by depth discrepancy features. This preserves high-weight regions while implementing a dual-branch constraint strategy tailored to regional texture variations, thereby improving geometric detail characterization. For multi-view optimization, we introduce a geometry-guided cross-view point cloud association method combined with a dynamic weight sampling strategy. This constructs 3D structural normal constraints across adjacent point cloud frames, effectively reinforcing multi-view consistency and reconstruction fidelity. Extensive experiments on public datasets demonstrate that our method achieves both competitive rendering quality and geometric reconstruction. See our interactive project page
Cross-Modal Geometric Hierarchy Fusion: An Implicit-Submap Driven Framework for Resilient 3D Place Recognition
Jun 17, 2025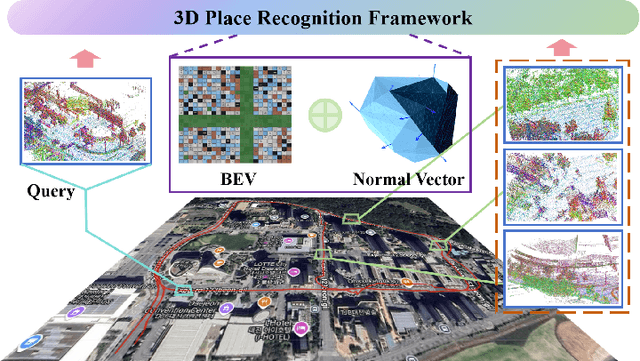
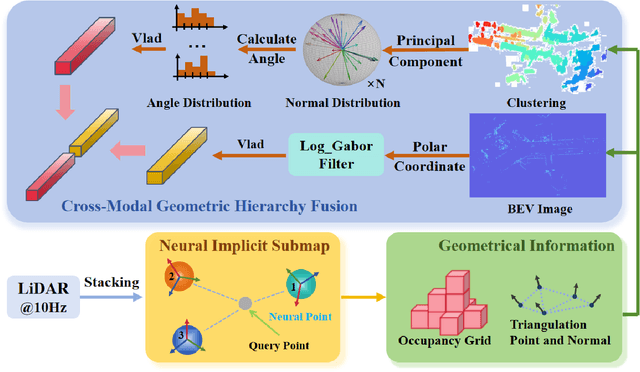
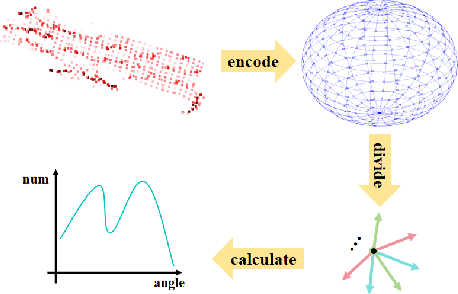

LiDAR-based place recognition serves as a crucial enabler for long-term autonomy in robotics and autonomous driving systems. Yet, prevailing methodologies relying on handcrafted feature extraction face dual challenges: (1) Inconsistent point cloud density, induced by ego-motion dynamics and environmental disturbances during repeated traversals, leads to descriptor instability, and (2) Representation fragility stems from reliance on single-level geometric abstractions that lack discriminative power in structurally complex scenarios. To address these limitations, we propose a novel framework that redefines 3D place recognition through density-agnostic geometric reasoning. Specifically, we introduce an implicit 3D representation based on elastic points, which is immune to the interference of original scene point cloud density and achieves the characteristic of uniform distribution. Subsequently, we derive the occupancy grid and normal vector information of the scene from this implicit representation. Finally, with the aid of these two types of information, we obtain descriptors that fuse geometric information from both bird's-eye view (capturing macro-level spatial layouts) and 3D segment (encoding micro-scale surface geometries) perspectives. We conducted extensive experiments on numerous datasets (KITTI, KITTI-360, MulRan, NCLT) across diverse environments. The experimental results demonstrate that our method achieves state-of-the-art performance. Moreover, our approach strikes an optimal balance between accuracy, runtime, and memory optimization for historical maps, showcasing excellent Resilient and scalability. Our code will be open-sourced in the future.
Topology-Aware 3D Gaussian Splatting: Leveraging Persistent Homology for Optimized Structural Integrity
Dec 21, 2024Gaussian Splatting (GS) has emerged as a crucial technique for representing discrete volumetric radiance fields. It leverages unique parametrization to mitigate computational demands in scene optimization. This work introduces Topology-Aware 3D Gaussian Splatting (Topology-GS), which addresses two key limitations in current approaches: compromised pixel-level structural integrity due to incomplete initial geometric coverage, and inadequate feature-level integrity from insufficient topological constraints during optimization. To overcome these limitations, Topology-GS incorporates a novel interpolation strategy, Local Persistent Voronoi Interpolation (LPVI), and a topology-focused regularization term based on persistent barcodes, named PersLoss. LPVI utilizes persistent homology to guide adaptive interpolation, enhancing point coverage in low-curvature areas while preserving topological structure. PersLoss aligns the visual perceptual similarity of rendered images with ground truth by constraining distances between their topological features. Comprehensive experiments on three novel-view synthesis benchmarks demonstrate that Topology-GS outperforms existing methods in terms of PSNR, SSIM, and LPIPS metrics, while maintaining efficient memory usage. This study pioneers the integration of topology with 3D-GS, laying the groundwork for future research in this area.
Multimodal Relational Triple Extraction with Query-based Entity Object Transformer
Aug 16, 2024Multimodal Relation Extraction is crucial for constructing flexible and realistic knowledge graphs. Recent studies focus on extracting the relation type with entity pairs present in different modalities, such as one entity in the text and another in the image. However, existing approaches require entities and objects given beforehand, which is costly and impractical. To address the limitation, we propose a novel task, Multimodal Entity-Object Relational Triple Extraction, which aims to extract all triples (entity span, relation, object region) from image-text pairs. To facilitate this study, we modified a multimodal relation extraction dataset MORE, which includes 21 relation types, to create a new dataset containing 20,264 triples, averaging 5.75 triples per image-text pair. Moreover, we propose QEOT, a query-based model with a selective attention mechanism, to dynamically explore the interaction and fusion of textual and visual information. In particular, the proposed method can simultaneously accomplish entity extraction, relation classification, and object detection with a set of queries. Our method is suitable for downstream applications and reduces error accumulation due to the pipeline-style approaches. Extensive experimental results demonstrate that our proposed method outperforms the existing baselines by 8.06% and achieves state-of-the-art performance.
Deep Frequency Derivative Learning for Non-stationary Time Series Forecasting
Jun 29, 2024While most time series are non-stationary, it is inevitable for models to face the distribution shift issue in time series forecasting. Existing solutions manipulate statistical measures (usually mean and std.) to adjust time series distribution. However, these operations can be theoretically seen as the transformation towards zero frequency component of the spectrum which cannot reveal full distribution information and would further lead to information utilization bottleneck in normalization, thus hindering forecasting performance. To address this problem, we propose to utilize the whole frequency spectrum to transform time series to make full use of data distribution from the frequency perspective. We present a deep frequency derivative learning framework, DERITS, for non-stationary time series forecasting. Specifically, DERITS is built upon a novel reversible transformation, namely Frequency Derivative Transformation (FDT) that makes signals derived in the frequency domain to acquire more stationary frequency representations. Then, we propose the Order-adaptive Fourier Convolution Network to conduct adaptive frequency filtering and learning. Furthermore, we organize DERITS as a parallel-stacked architecture for the multi-order derivation and fusion for forecasting. Finally, we conduct extensive experiments on several datasets which show the consistent superiority in both time series forecasting and shift alleviation.
RTF: Region-based Table Filling Method for Relational Triple Extraction
Apr 29, 2024



Relational triple extraction is crucial work for the automatic construction of knowledge graphs. Existing methods only construct shallow representations from a token or token pair-level. However, previous works ignore local spatial dependencies of relational triples, resulting in a weakness of entity pair boundary detection. To tackle this problem, we propose a novel Region-based Table Filling method (RTF). We devise a novel region-based tagging scheme and bi-directional decoding strategy, which regard each relational triple as a region on the relation-specific table, and identifies triples by determining two endpoints of each region. We also introduce convolution to construct region-level table representations from a spatial perspective which makes triples easier to be captured. In addition, we share partial tagging scores among different relations to improve learning efficiency of relation classifier. Experimental results show that our method achieves state-of-the-art with better generalization capability on three variants of two widely used benchmark datasets.
Deep Coupling Network For Multivariate Time Series Forecasting
Feb 23, 2024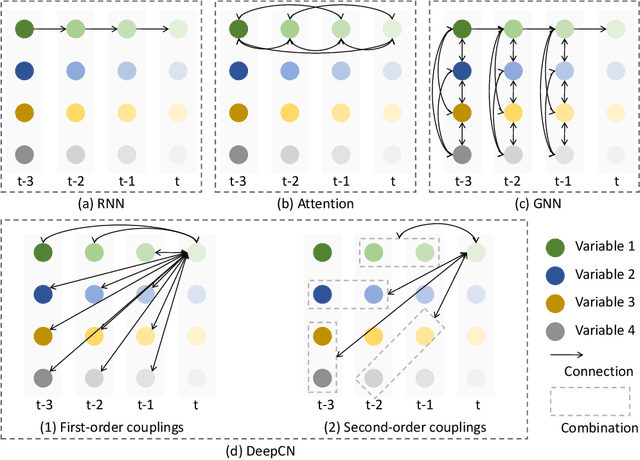



Multivariate time series (MTS) forecasting is crucial in many real-world applications. To achieve accurate MTS forecasting, it is essential to simultaneously consider both intra- and inter-series relationships among time series data. However, previous work has typically modeled intra- and inter-series relationships separately and has disregarded multi-order interactions present within and between time series data, which can seriously degrade forecasting accuracy. In this paper, we reexamine intra- and inter-series relationships from the perspective of mutual information and accordingly construct a comprehensive relationship learning mechanism tailored to simultaneously capture the intricate multi-order intra- and inter-series couplings. Based on the mechanism, we propose a novel deep coupling network for MTS forecasting, named DeepCN, which consists of a coupling mechanism dedicated to explicitly exploring the multi-order intra- and inter-series relationships among time series data concurrently, a coupled variable representation module aimed at encoding diverse variable patterns, and an inference module facilitating predictions through one forward step. Extensive experiments conducted on seven real-world datasets demonstrate that our proposed DeepCN achieves superior performance compared with the state-of-the-art baselines.