 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Reliable Spatiotemporal Dependencies for Efficient Visual Tracking
Jan 14, 2026Recent advances in transformer-based lightweight object tracking have established new standards across benchmarks, leveraging the global receptive field and powerful feature extraction capabilities of attention mechanisms. Despite these achievements, existing methods universally employ sparse sampling during training--utilizing only one template and one search image per sequence--which fails to comprehensively explore spatiotemporal information in videos. This limitation constrains performance and cause the gap between lightweight and high-performance trackers. To bridge this divide while maintaining real-time efficiency, we propose STDTrack, a framework that pioneers the integration of reliable spatiotemporal dependencies into lightweight trackers. Our approach implements dense video sampling to maximize spatiotemporal information utilization. We introduce a temporally propagating spatiotemporal token to guide per-frame feature extraction. To ensure comprehensive target state representation, we disign the Multi-frame Information Fusion Module (MFIFM), which augments current dependencies using historical context. The MFIFM operates on features stored in our constructed Spatiotemporal Token Maintainer (STM), where a quality-based update mechanism ensures information reliability. Considering the scale variation among tracking targets, we develop a multi-scale prediction head to dynamically adapt to objects of different sizes. Extensive experiments demonstrate state-of-the-art results across six benchmarks. Notably, on GOT-10k, STDTrack rivals certain high-performance non-real-time trackers (e.g., MixFormer) while operating at 192 FPS(GPU) and 41 FPS(CPU).
* 8 pages, 6 figures
LTA-thinker: Latent Thought-Augmented Training Framework for Large Language Models on Complex Reasoning
Sep 16, 2025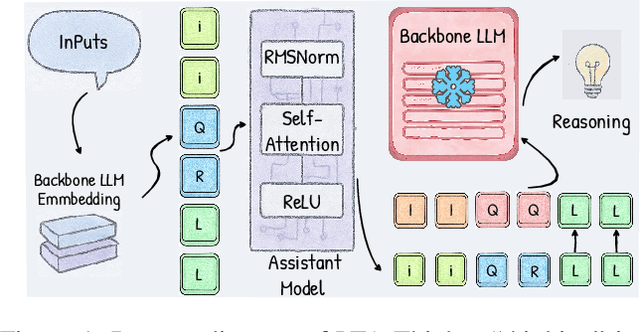
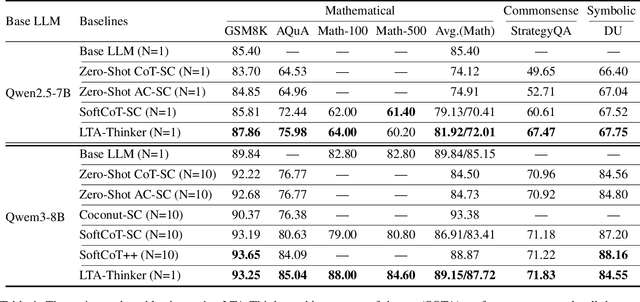
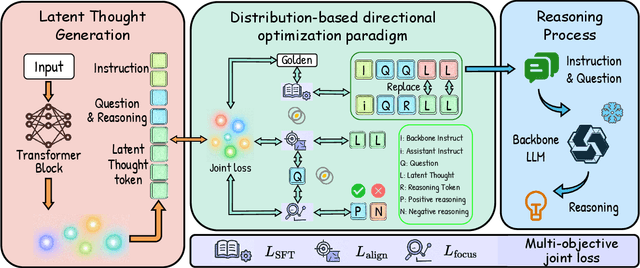
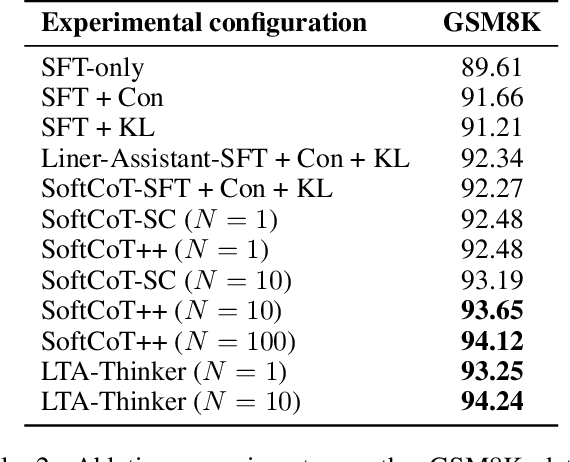
Complex Reasoning in Large Language Models can be dynamically optimized using Test-Time Scaling (TTS) to mitigate Overthinking. Methods such as Coconut, SoftCoT and its variant are effective in continuous latent space inference, the core bottleneck still lies in the efficient generation and utilization of high-quality Latent Thought. Drawing from the theory of SoftCoT++ that a larger variance in the generated Latent Thought distribution more closely approximates the golden truth distribution, we propose a Latent Thought-Augmented Training Framework--LTA-Thinker, which improves distributional variance and enhances reasoning performance from two perspectives. First, LTA-Thinker constructs a Latent Thought generation architecture based on a learnable prior. This architecture aims to increase the variance distribution of generated Latent Thought Vectors in order to simplify the overall structure and raise the performance ceiling. Second, LTA-Thinker introduces a distribution-based directional optimization paradigm that jointly constrains both distribution locality and distribution scale. This mechanism improves information efficiency and computational cost through a multi-objective co-training strategy, which combines standard Supervised Fine-Tuning (SFT) loss with two novel losses: Semantic Alignment Loss, which utilizes KL divergence to ensure that the Latent Thought is highly relevant to the semantics of the question; Reasoning Focus Loss, which utilizes a contrastive learning mechanism to guide the model to focus on the most critical reasoning steps. Experiments show that LTA-thinker achieves state-of-the-art (SOTA) performance among various baselines and demonstrates a higher performance ceiling and better scaling effects.
TechGPT-2.0: A large language model project to solve the task of knowledge graph construction
Jan 09, 2024Large language models have exhibited robust performance across diverse natural language processing tasks. This report introduces TechGPT-2.0, a project designed to enhance the capabilities of large language models specifically in knowledge graph construction tasks, including named entity recognition (NER) and relationship triple extraction (RTE) tasks in NLP applications. Additionally, it serves as a LLM accessible for research within the Chinese open-source model community. We offer two 7B large language model weights and a QLoRA weight specialized for processing lengthy texts.Notably, TechGPT-2.0 is trained on Huawei's Ascend server. Inheriting all functionalities from TechGPT-1.0, it exhibits robust text processing capabilities, particularly in the domains of medicine and law. Furthermore, we introduce new capabilities to the model, enabling it to process texts in various domains such as geographical areas, transportation, organizations, literary works, biology, natural sciences, astronomical objects, and architecture. These enhancements also fortified the model's adeptness in handling hallucinations, unanswerable queries, and lengthy texts. This report provides a comprehensive and detailed introduction to the full fine-tuning process on Huawei's Ascend servers, encompassing experiences in Ascend server debugging, instruction fine-tuning data processing, and model training. Our code is available at https://github.com/neukg/TechGPT-2.0
Towards Stable Adversarial Feature Learning for LiDAR based Loop Closure Detection
Nov 21, 2017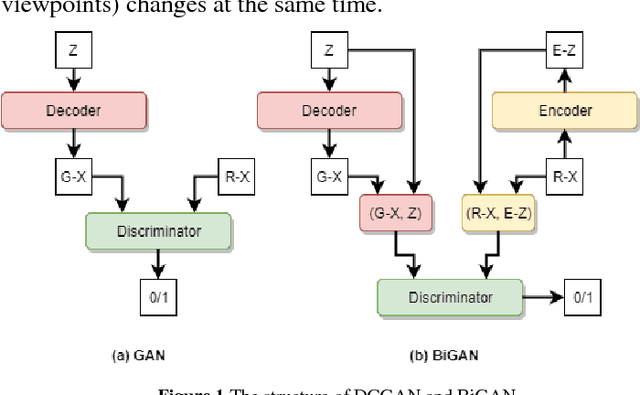
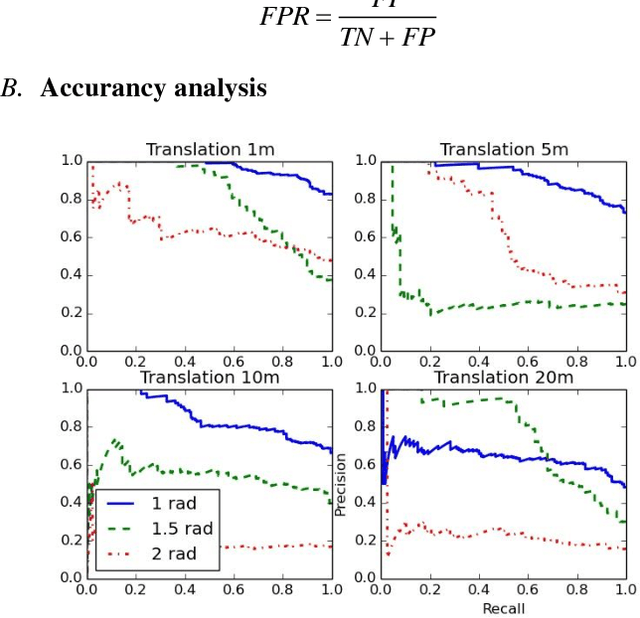
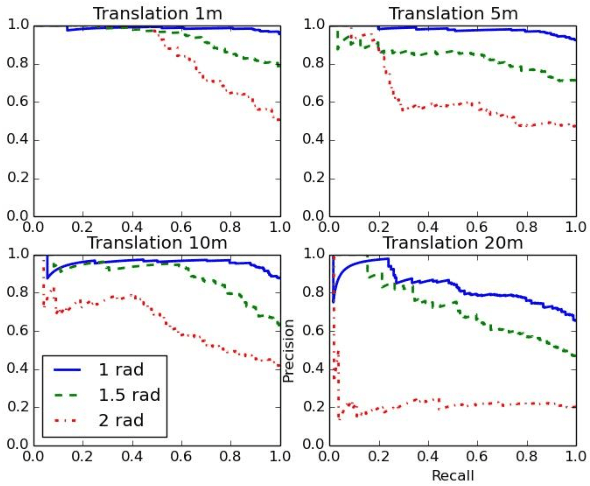
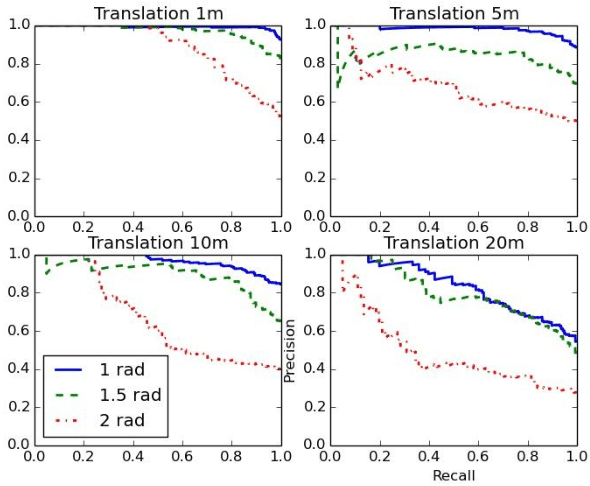
Stable feature extraction is the key for the Loop closure detection (LCD) task in the simultaneously localization and mapping (SLAM) framework. In our paper, the feature extraction is operated by using a generative adversarial networks (GANs) based unsupervised learning. GANs are powerful generative models, however, GANs based adversarial learning suffers from training instability. We find that the data-code joint distribution in the adversarial learning is a more complex manifold than in the original GANs. And the loss function that drive the attractive force between synthesis and target distributions is unable for efficient latent code learning for LCD task. To relieve this problem, we combines the original adversarial learning with an inner cycle restriction module and a side updating module. To our best knowledge, we are the first to extract the adversarial features from the light detection and ranging (LiDAR) based inputs, which is invariant to the changes caused by illumination and appearance as in the visual inputs. We use the KITTI odometry datasets to investigate the performance of our method. The extensive experiments results shows that, with the same LiDAR projection maps, the proposed features are more stable in training, and could significantly improve the robustness on viewpoints differences than other state-of-art methods.