 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergeWriter: Data-Driven Bottom-Up Article Construction
Sep 16, 2025Large Language Models (LLMs) have shown remarkable prowess in text generation, yet producing long-form, factual documents grounded in extensive external knowledge bases remains a significant challenge. Existing "top-down" methods, which first generate a hypothesis or outline and then retrieve evidence, often suffer from a disconnect between the model's plan and the available knowledge, leading to content fragmentation and factual inaccuracies. To address these limitations, we propose a novel "bottom-up," data-driven framework that inverts the conventional generation pipeline. Our approach is predicated on a "Retrieval-First for Knowledge, Clustering for Structure" strategy, which first establishes the "knowledge boundaries" of the source corpus before any generative planning occurs. Specifically, we perform exhaustive iterative retrieval from the knowledge base and then employ an unsupervised clustering algorithm to organize the retrieved documents into distinct "knowledge clusters." These clusters form an objective, data-driven foundation that directly guides the subsequent generation of a hierarchical outline and the final document content. This bottom-up process ensures that the generated text is strictly constrained by and fully traceable to the source material, proactively adapting to the finite scope of the knowledge base and fundamentally mitigating the risk of hallucination. Experimental results on both 14B and 32B parameter models demonstrate that our method achieves performance comparable to or exceeding state-of-the-art baselines, and is expected to demonstrate unique advantages in knowledge-constrained scenarios that demand high fidelity and structural coherence. Our work presents an effective paradigm for generating reliable, structured, long-form documents, paving the way for more robust LLM applications in high-stakes, knowledge-intensive domains.
CogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
Jul 23, 2025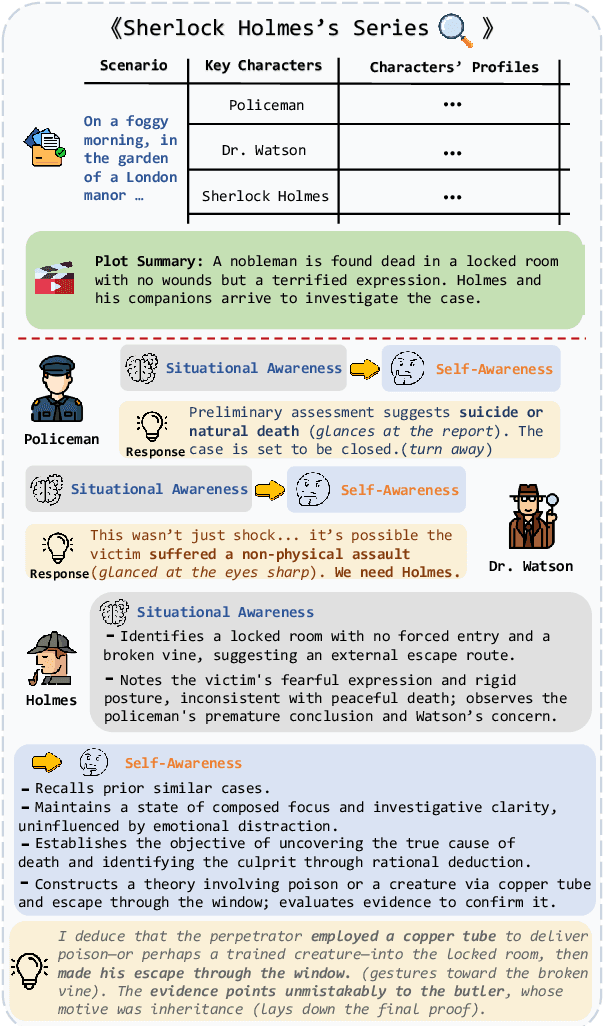
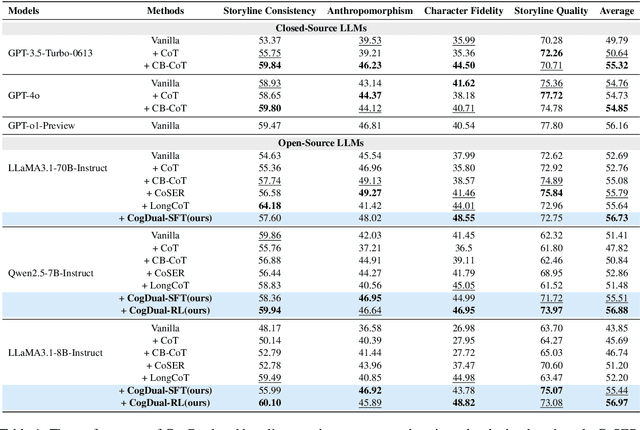
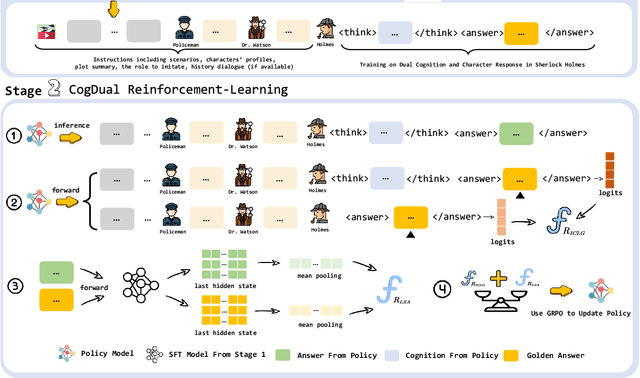
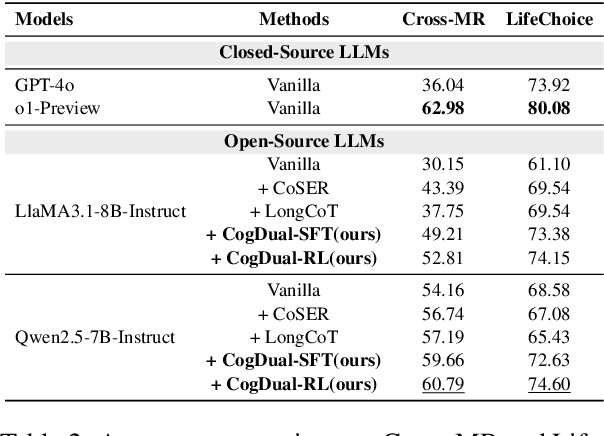
Role-Playing Language Agents (RPLAs) have emerged as a significant application direction for Large Language Models (LLMs). Existing approaches typically rely on prompt engineering or supervised fine-tuning to enable models to imitate character behaviors in specific scenarios, but often neglect the underlying \emph{cognitive} mechanisms driving these behaviors. Inspired by cognitive psychology, we introduce \textbf{CogDual}, a novel RPLA adopting a \textit{cognize-then-respond } reasoning paradigm. By jointly modeling external situational awareness and internal self-awareness, CogDual generates responses with improved character consistency and contextual alignment. To further optimize the performance, we employ reinforcement learning with two general-purpose reward schemes designed for open-domain text generation. Extensive experiments on the CoSER benchmark, as well as Cross-MR and LifeChoice, demonstrate that CogDual consistently outperforms existing baselines and generalizes effectively across diverse role-playing tasks.
Augmenting the Veracity and Explanations of Complex Fact Checking via Iterative Self-Revision with LLMs
Oct 19, 2024
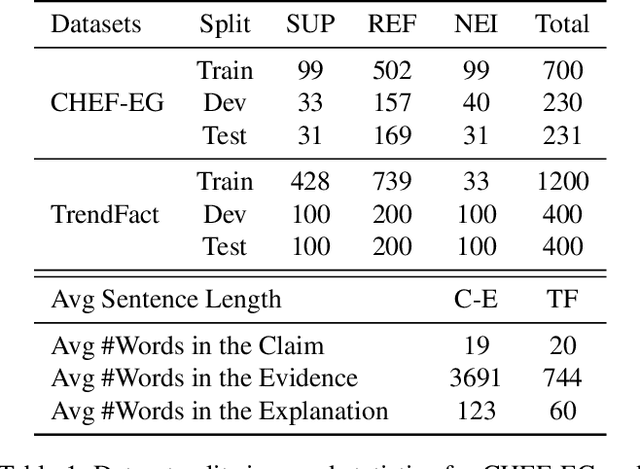
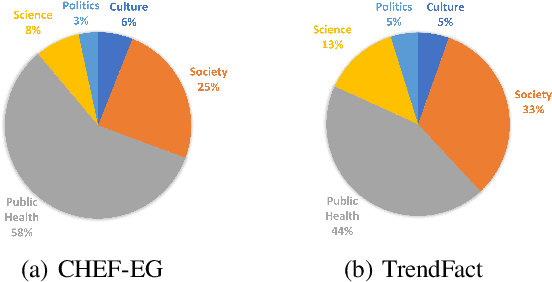
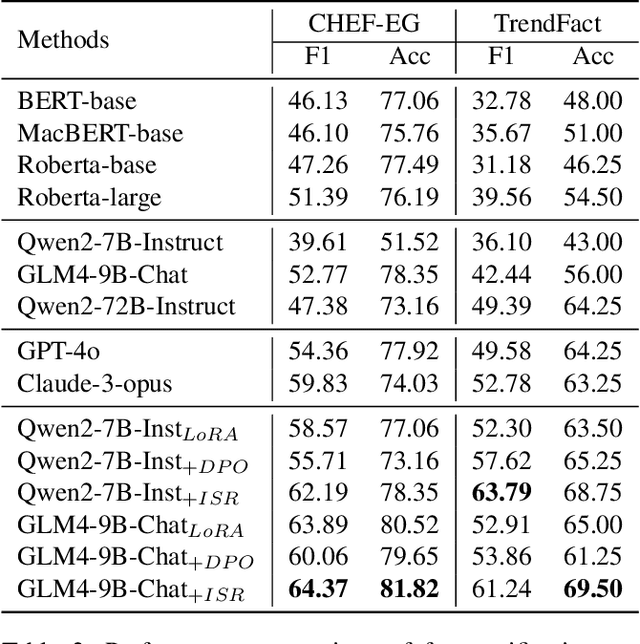
Explanation generation plays a more pivotal role than fact verification in producing interpretable results and facilitating comprehensive fact-checking, which has recently garnered considerable attention. However, previous studies on explanation generation has shown several limitations, such as being confined to English scenarios, involving overly complex inference processes, and not fully unleashing the potential of the mutual feedback between veracity labels and explanation texts. To address these issues, we construct two complex fact-checking datasets in the Chinese scenarios: CHEF-EG and TrendFact. These datasets involve complex facts in areas such as health, politics, and society, presenting significant challenges for fact verification methods. In response to these challenges, we propose a unified framework called FactISR (Augmenting Fact-Checking via Iterative Self-Revision) to perform mutual feedback between veracity and explanations by leveraging the capabilities of large language models(LLMs). FactISR uses a single model to address tasks such as fact verification and explanation generation. Its self-revision mechanism can further revision the consistency between veracity labels, explanation texts, and evidence, as well as eliminate irrelevant noise. We conducted extensive experiments with baselines and FactISR on the proposed datasets. The experimental results demonstrate the effectiveness of our method.
TechGPT-2.0: A large language model project to solve the task of knowledge graph construction
Jan 09, 2024Large language models have exhibited robust performance across diverse natural language processing tasks. This report introduces TechGPT-2.0, a project designed to enhance the capabilities of large language models specifically in knowledge graph construction tasks, including named entity recognition (NER) and relationship triple extraction (RTE) tasks in NLP applications. Additionally, it serves as a LLM accessible for research within the Chinese open-source model community. We offer two 7B large language model weights and a QLoRA weight specialized for processing lengthy texts.Notably, TechGPT-2.0 is trained on Huawei's Ascend server. Inheriting all functionalities from TechGPT-1.0, it exhibits robust text processing capabilities, particularly in the domains of medicine and law. Furthermore, we introduce new capabilities to the model, enabling it to process texts in various domains such as geographical areas, transportation, organizations, literary works, biology, natural sciences, astronomical objects, and architecture. These enhancements also fortified the model's adeptness in handling hallucinations, unanswerable queries, and lengthy texts. This report provides a comprehensive and detailed introduction to the full fine-tuning process on Huawei's Ascend servers, encompassing experiences in Ascend server debugging, instruction fine-tuning data processing, and model training. Our code is available at https://github.com/neukg/TechGPT-2.0