 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Geometric Hierarchy Fusion: An Implicit-Submap Driven Framework for Resilient 3D Place Recognition
Jun 17, 2025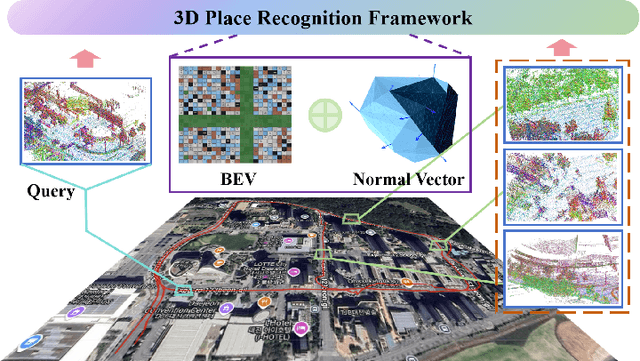
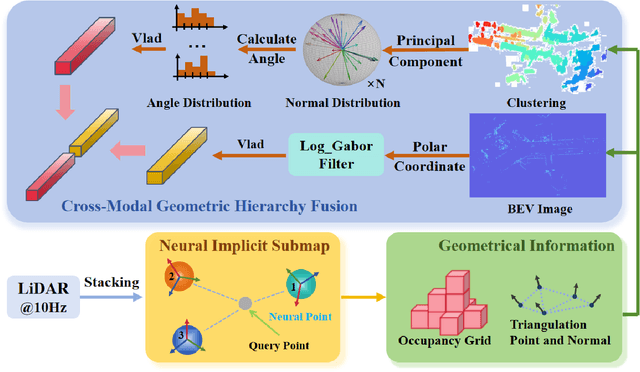
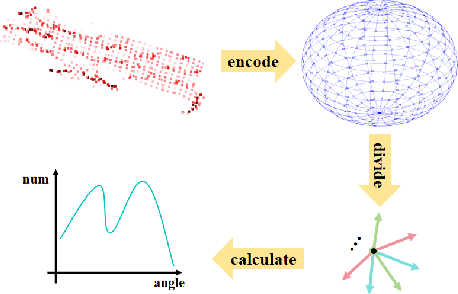

LiDAR-based place recognition serves as a crucial enabler for long-term autonomy in robotics and autonomous driving systems. Yet, prevailing methodologies relying on handcrafted feature extraction face dual challenges: (1) Inconsistent point cloud density, induced by ego-motion dynamics and environmental disturbances during repeated traversals, leads to descriptor instability, and (2) Representation fragility stems from reliance on single-level geometric abstractions that lack discriminative power in structurally complex scenarios. To address these limitations, we propose a novel framework that redefines 3D place recognition through density-agnostic geometric reasoning. Specifically, we introduce an implicit 3D representation based on elastic points, which is immune to the interference of original scene point cloud density and achieves the characteristic of uniform distribution. Subsequently, we derive the occupancy grid and normal vector information of the scene from this implicit representation. Finally, with the aid of these two types of information, we obtain descriptors that fuse geometric information from both bird's-eye view (capturing macro-level spatial layouts) and 3D segment (encoding micro-scale surface geometries) perspectives. We conducted extensive experiments on numerous datasets (KITTI, KITTI-360, MulRan, NCLT) across diverse environments. The experimental results demonstrate that our method achieves state-of-the-art performance. Moreover, our approach strikes an optimal balance between accuracy, runtime, and memory optimization for historical maps, showcasing excellent Resilient and scalability. Our code will be open-sourced in the future.
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025
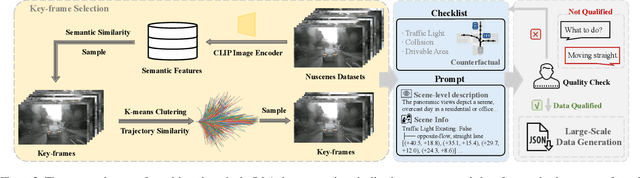
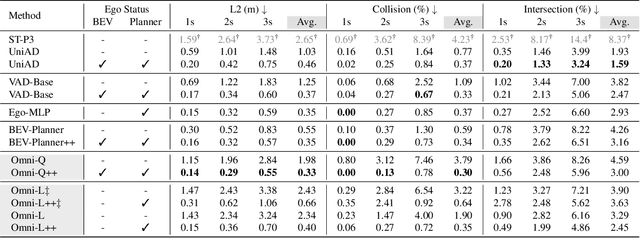
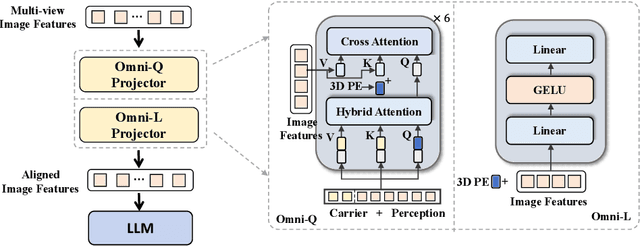
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
May 02, 2024
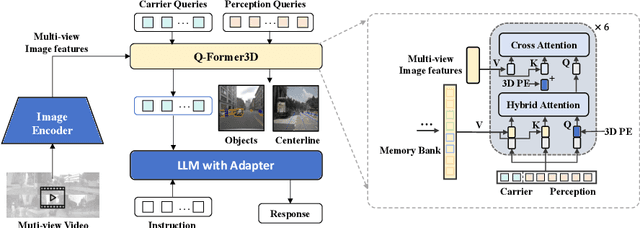
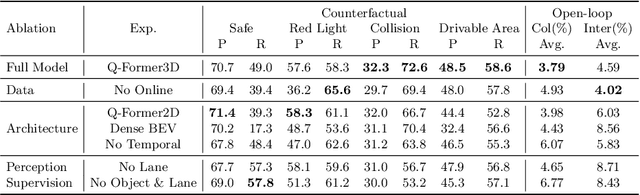

The advances in multimodal large language models (MLLMs) have led to growing interests in LLM-based autonomous driving agents to leverage their strong reasoning capabilities. However, capitalizing on MLLMs' strong reasoning capabilities for improved planning behavior is challenging since planning requires full 3D situational awareness beyond 2D reasoning. To address this challenge, our work proposes a holistic framework for strong alignment between agent models and 3D driving tasks. Our framework starts with a novel 3D MLLM architecture that uses sparse queries to lift and compress visual representations into 3D before feeding them into an LLM. This query-based representation allows us to jointly encode dynamic objects and static map elements (e.g., traffic lanes), providing a condensed world model for perception-action alignment in 3D. We further propose OmniDrive-nuScenes, a new visual question-answering dataset challenging the true 3D situational awareness of a model with comprehensive visual question-answering (VQA) tasks, including scene description, traffic regulation, 3D grounding, counterfactual reasoning, decision making and planning. Extensive studies show the effectiveness of the proposed architecture as well as the importance of the VQA tasks for reasoning and planning in complex 3D scenes.
Far3D: Expanding the Horizon for Surround-view 3D Object Detection
Aug 18, 2023
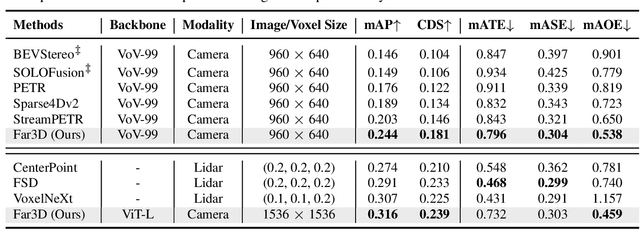
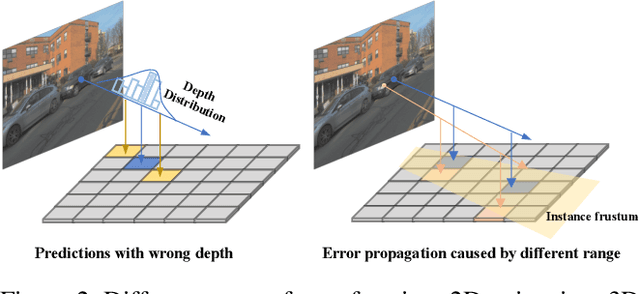
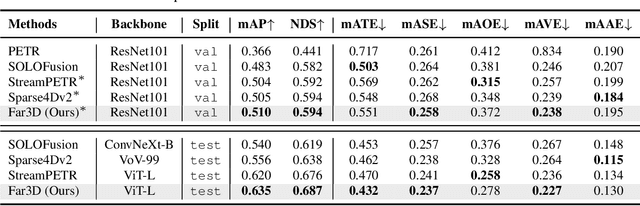
Recently 3D object detection from surround-view images has made notable advancements with its low deployment cost. However, most works have primarily focused on close perception range while leaving long-range detection less explored. Expanding existing methods directly to cover long distances poses challenges such as heavy computation costs and unstable convergence. To address these limitations, this paper proposes a novel sparse query-based framework, dubbed Far3D. By utilizing high-quality 2D object priors, we generate 3D adaptive queries that complement the 3D global queries. To efficiently capture discriminative features across different views and scales for long-range objects, we introduce a perspective-aware aggregation module. Additionally, we propose a range-modulated 3D denoising approach to address query error propagation and mitigate convergence issues in long-range tasks. Significantly, Far3D demonstrates SoTA performance on the challenging Argoverse 2 dataset, covering a wide range of 150 meters, surpassing several LiDAR-based approaches. Meanwhile, Far3D exhibits superior performance compared to previous methods on the nuScenes dataset. The code will be available soon.
Focal-PETR: Embracing Foreground for Efficient Multi-Camera 3D Object Detection
Dec 13, 2022



The dominant multi-camera 3D detection paradigm is based on explicit 3D feature construction, which requires complicated indexing of local image-view features via 3D-to-2D projection. Other methods implicitly introduce geometric positional encoding and perform global attention (e.g., PETR) to build the relationship between image tokens and 3D objects. The 3D-to-2D perspective inconsistency and global attention lead to a weak correlation between foreground tokens and queries, resulting in slow convergence. We propose Focal-PETR with instance-guided supervision and spatial alignment module to adaptively focus object queries on discriminative foreground regions. Focal-PETR additionally introduces a down-sampling strategy to reduce the consumption of global attention. Due to the highly parallelized implementation and down-sampling strategy, our model, without depth supervision, achieves leading performance on the large-scale nuScenes benchmark and a superior speed of 30 FPS on a single RTX3090 GPU. Extensive experiments show that our method outperforms PETR while consuming 3x fewer training hours. The code will be made publicly available.