 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Distributional Learning with Non-crossing Quantile Network
Apr 11, 2025In this paper, we introduce a non-crossing quantile (NQ) network for conditional distribution learning. By leveraging non-negative activation functions, the NQ network ensures that the learned distributions remain monotonic, effectively addressing the issue of quantile crossing. Furthermore, the NQ network-based deep distributional learning framework is highly adaptable, applicable to a wide range of applications, from classical non-parametric quantile regression to more advanced tasks such as causal effect estimation and distributional reinforcement learning (RL). We also develop a comprehensive theoretical foundation for the deep NQ estimator and its application to distributional RL, providing an in-depth analysis that demonstrates its effectiveness across these domains. Our experimental results further highlight the robustness and versatility of the NQ network.
Causal Deepsets for Off-policy Evaluation under Spatial or Spatio-temporal Interferences
Jul 25, 2024



Off-policy evaluation (OPE) is widely applied in sectors such as pharmaceuticals and e-commerce to evaluate the efficacy of novel products or policies from offline datasets. This paper introduces a causal deepset framework that relaxes several key structural assumptions, primarily the mean-field assumption, prevalent in existing OPE methodologies that handle spatio-temporal interference. These traditional assumptions frequently prove inadequate in real-world settings, thereby restricting the capability of current OPE methods to effectively address complex interference effects. In response, we advocate for the implementation of the permutation invariance (PI) assumption. This innovative approach enables the data-driven, adaptive learning of the mean-field function, offering a more flexible estimation method beyond conventional averaging. Furthermore, we present novel algorithms that incorporate the PI assumption into OPE and thoroughly examine their theoretical foundations. Our numerical analyses demonstrate that this novel approach yields significantly more precise estimations than existing baseline algorithms, thereby substantially improving the practical applicability and effectiveness of OPE methodologies. A Python implementation of our proposed method is available at https://github.com/BIG-S2/Causal-Deepsets.
Pessimistic Causal Reinforcement Learning with Mediators for Confounded Offline Data
Mar 18, 2024



In real-world scenarios, datasets collected from randomized experiments are often constrained by size, due to limitations in time and budget. As a result, leveraging large observational datasets becomes a more attractive option for achieving high-quality policy learning. However, most existing offline reinforcement learning (RL) methods depend on two key assumptions--unconfoundedness and positivity--which frequently do not hold in observational data contexts. Recognizing these challenges, we propose a novel policy learning algorithm, PESsimistic CAusal Learning (PESCAL). We utilize the mediator variable based on front-door criterion to remove the confounding bias; additionally, we adopt the pessimistic principle to address the distributional shift between the action distributions induced by candidate policies, and the behavior policy that generates the observational data. Our key observation is that, by incorporating auxiliary variables that mediate the effect of actions on system dynamics, it is sufficient to learn a lower bound of the mediator distribution function, instead of the Q-function, to partially mitigate the issue of distributional shift. This insight significantly simplifies our algorithm, by circumventing the challenging task of sequential uncertainty quantification for the estimated Q-function. Moreover, we provide theoretical guarantees for the algorithms we propose, and demonstrate their efficacy through simulations, as well as real-world experiments utilizing offline datasets from a leading ride-hailing platform.
Robust Offline Policy Evaluation and Optimization with Heavy-Tailed Rewards
Oct 28, 2023This paper endeavors to augment the robustness of offline reinforcement learning (RL) in scenarios laden with heavy-tailed rewards, a prevalent circumstance in real-world applications. We propose two algorithmic frameworks, ROAM and ROOM, for robust off-policy evaluation (OPE) and offline policy optimization (OPO), respectively. Central to our frameworks is the strategic incorporation of the median-of-means method with offline RL, enabling straightforward uncertainty estimation for the value function estimator. This not only adheres to the principle of pessimism in OPO but also adeptly manages heavy-tailed rewards. Theoretical results and extensive experiments demonstrate that our two frameworks outperform existing methods on the logged dataset exhibits heavy-tailed reward distributions.
An Instrumental Variable Approach to Confounded Off-Policy Evaluation
Dec 29, 2022Off-policy evaluation (OPE) is a method for estimating the return of a target policy using some pre-collected observational data generated by a potentially different behavior policy. In some cases, there may be unmeasured variables that can confound the action-reward or action-next-state relationships, rendering many existing OPE approaches ineffective. This paper develops an instrumental variable (IV)-based method for consistent OPE in confounded Markov decision processes (MDPs). Similar to single-stage decision making, we show that IV enables us to correctly identify the target policy's value in infinite horizon settings as well. Furthermore, we propose an efficient and robust value estimator and illustrate its effectiveness through extensive simulations and analysis of real data from a world-leading short-video platform.
Quantile Off-Policy Evaluation via Deep Conditional Generative Learning
Dec 29, 2022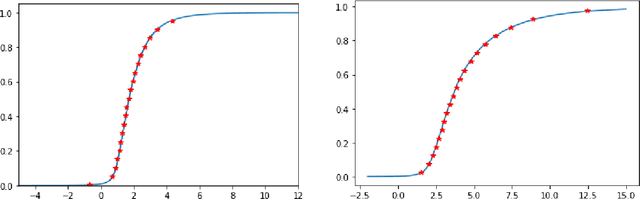

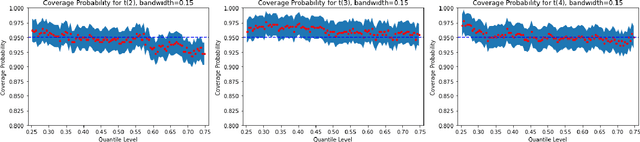

Off-Policy evaluation (OPE) is concerned with evaluating a new target policy using offline data generated by a potentially different behavior policy. It is critical in a number of sequential decision making problems ranging from healthcare to technology industries. Most of the work in existing literature is focused on evaluating the mean outcome of a given policy, and ignores the variability of the outcome. However, in a variety of applications, criteria other than the mean may be more sensible. For example, when the reward distribution is skewed and asymmetric, quantile-based metrics are often preferred for their robustness. In this paper, we propose a doubly-robust inference procedure for quantile OPE in sequential decision making and study its asymptotic properties. In particular, we propose utilizing state-of-the-art deep conditional generative learning methods to handle parameter-dependent nuisance function estimation. We demonstrate the advantages of this proposed estimator through both simulations and a real-world dataset from a short-video platform. In particular, we find that our proposed estimator outperforms classical OPE estimators for the mean in settings with heavy-tailed reward distributions.
Conformal Off-Policy Prediction
Jun 14, 2022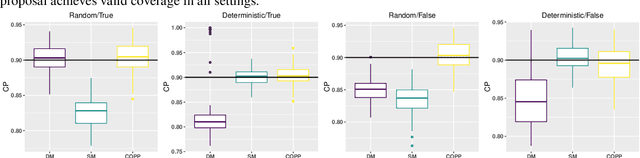
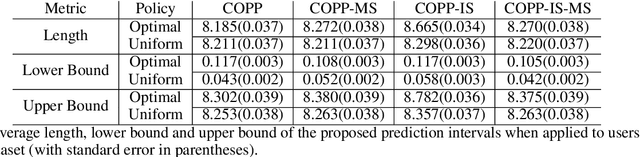
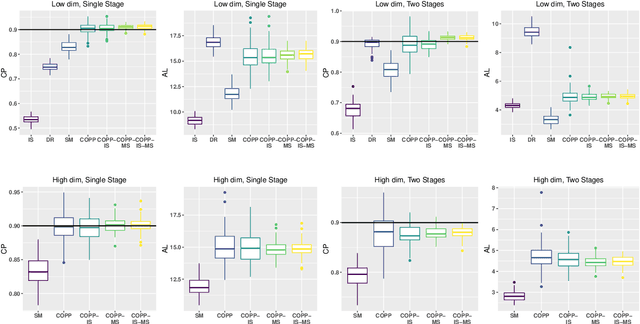
Off-policy evaluation is critical in a number of applications where new policies need to be evaluated offline before online deployment. Most existing methods focus on the expected return, define the target parameter through averaging and provide a point estimator only. In this paper, we develop a novel procedure to produce reliable interval estimators for a target policy's return starting from any initial state. Our proposal accounts for the variability of the return around its expectation, focuses on the individual effect and offers valid uncertainty quantification. Our main idea lies in designing a pseudo policy that generates subsamples as if they were sampled from the target policy so that existing conformal prediction algorithms are applicable to prediction interval construction. Our methods are justified by theories, synthetic data and real data from short-video platforms.
Off-Policy Confidence Interval Estimation with Confounded Markov Decision Process
Mar 12, 2022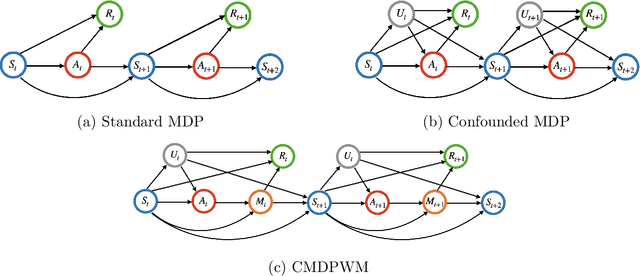

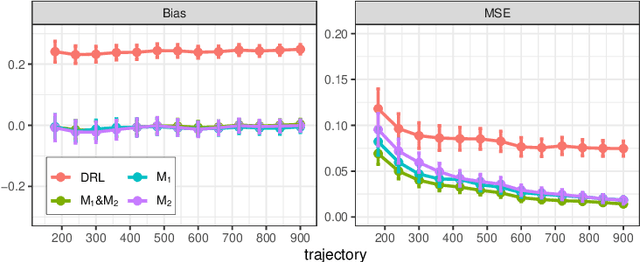
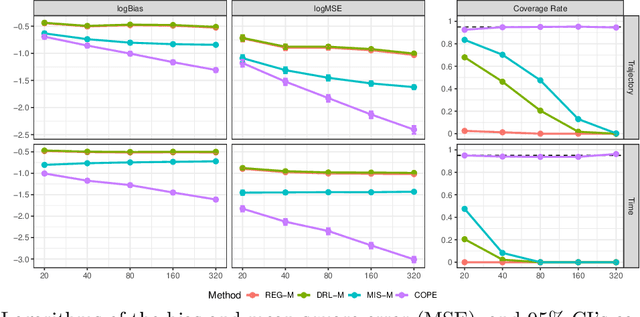
This paper is concerned with constructing a confidence interval for a target policy's value offline based on a pre-collected observational data in infinite horizon settings. Most of the existing works assume no unmeasured variables exist that confound the observed actions. This assumption, however, is likely to be violated in real applications such as healthcare and technological industries. In this paper, we show that with some auxiliary variables that mediate the effect of actions on the system dynamics, the target policy's value is identifiable in a confounded Markov decision process. Based on this result, we develop an efficient off-policy value estimator that is robust to potential model misspecification and provide rigorous uncertainty quantification. Our method is justified by theoretical results, simulated and real datasets obtained from ridesharing companies.
Statistically Efficient Advantage Learning for Offline Reinforcement Learning in Infinite Horizons
Feb 26, 2022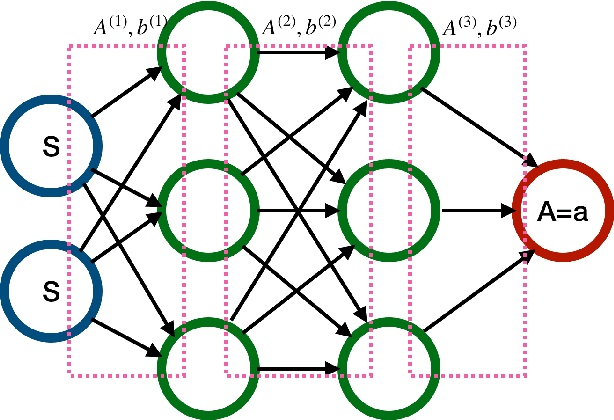
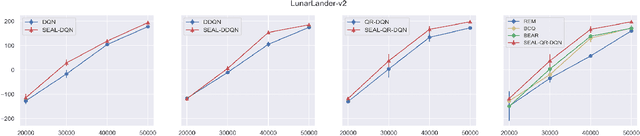
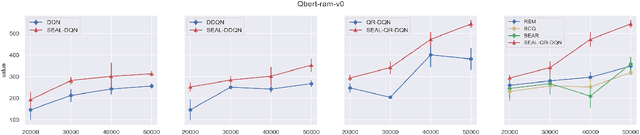

We consider reinforcement learning (RL) methods in offline domains without additional online data collection, such as mobile health applications. Most of existing policy optimization algorithms in the computer science literature are developed in online settings where data are easy to collect or simulate. Their generalizations to mobile health applications with a pre-collected offline dataset remain unknown. The aim of this paper is to develop a novel advantage learning framework in order to efficiently use pre-collected data for policy optimization. The proposed method takes an optimal Q-estimator computed by any existing state-of-the-art RL algorithms as input, and outputs a new policy whose value is guaranteed to converge at a faster rate than the policy derived based on the initial Q-estimator. Extensive numerical experiments are conducted to back up our theoretical findings.
Policy Evaluation for Temporal and/or Spatial Dependent Experiments in Ride-sourcing Platforms
Feb 22, 2022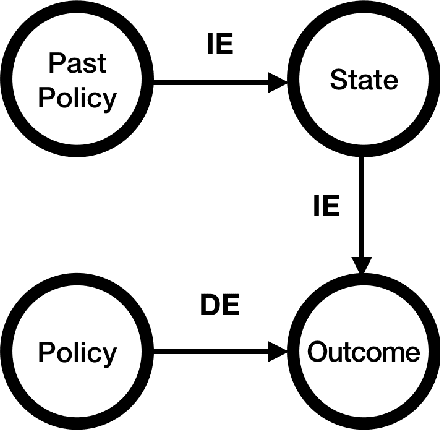
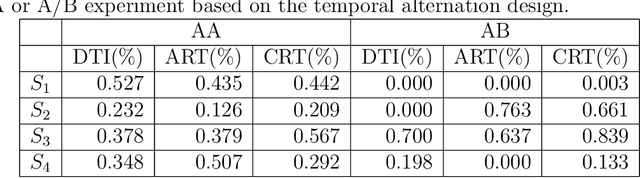
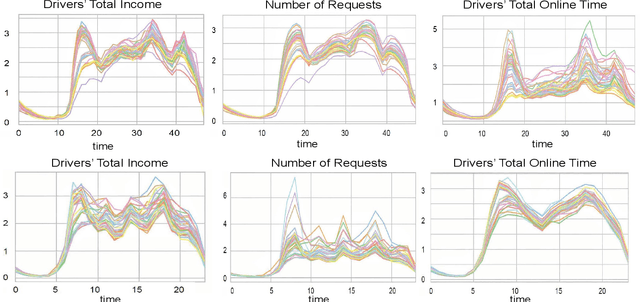

Policy evaluation based on A/B testing has attracted considerable interest in digital marketing, but such evaluation in ride-sourcing platforms (e.g., Uber and Didi) is not well studied primarily due to the complex structure of their temporal and/or spatial dependent experiments. Motivated by policy evaluation in ride-sourcing platforms, the aim of this paper is to establish causal relationship between platform's policies and outcomes of interest under a switchback design. We propose a novel potential outcome framework based on a temporal varying coefficient decision process (VCDP) model to capture the dynamic treatment effects in temporal dependent experiments. We further characterize the average treatment effect by decomposing it as the sum of direct effect (DE) and indirect effect (IE). We develop estimation and inference procedures for both DE and IE. Furthermore, we propose a spatio-temporal VCDP to deal with spatiotemporal dependent experiments. For both VCDP models, we establish the statistical properties (e.g., weak convergence and asymptotic power) of our estimation and inference procedures. We conduct extensive simulations to investigate the finite-sample performance of the proposed estimation and inference procedures. We examine how our VCDP models can help improve policy evaluation for various dispatching and dispositioning policies in Didi.