 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Off-Policy Prediction
Paper and Code
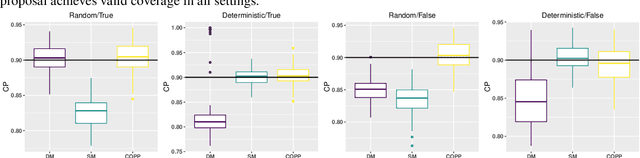
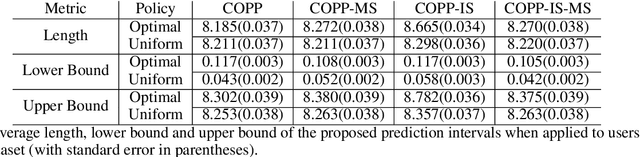
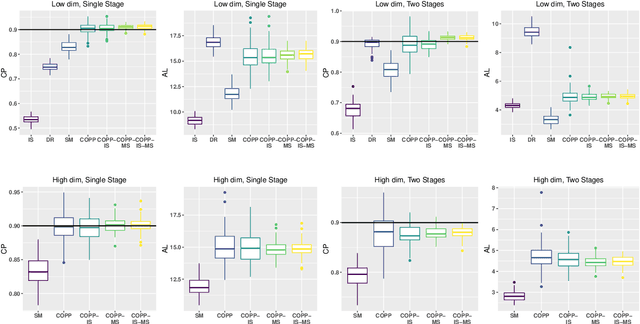
Off-policy evaluation is critical in a number of applications where new policies need to be evaluated offline before online deployment. Most existing methods focus on the expected return, define the target parameter through averaging and provide a point estimator only. In this paper, we develop a novel procedure to produce reliable interval estimators for a target policy's return starting from any initial state. Our proposal accounts for the variability of the return around its expectation, focuses on the individual effect and offers valid uncertainty quantification. Our main idea lies in designing a pseudo policy that generates subsamples as if they were sampled from the target policy so that existing conformal prediction algorithms are applicable to prediction interval construction. Our methods are justified by theories, synthetic data and real data from short-video platforms.