 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Sequential Experimental Design for A/B Testing
May 13, 2026Experimental design has emerged as a powerful approach for improving the sample efficiency of A/B testing, yet existing designs rely critically on correctly specified models. We study robust sequential experimental design under model misspecification and develop a unified framework that covers both contextual bandit and dynamic settings. Theoretically, we prove that our design bounds the worst-case mean squared error of the estimated treatment effect. Empirically, we demonstrate the effectiveness of the proposed approach using synthetic and real-world datasets from a leading technology company.
AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild
Feb 12, 2026Benchmarks are paramount for gauging progress in the domain of Mobile GUI Agents. In practical scenarios, users frequently fail to articulate precise directives containing full task details at the onset, and their expressions are typically ambiguous. Consequently, agents are required to converge on the user's true intent via active clarification and interaction during execution. However, existing benchmarks predominantly operate under the idealized assumption that user-issued instructions are complete and unequivocal. This paradigm focuses exclusively on assessing single-turn execution while overlooking the alignment capability of the agent. To address this limitation, we introduce AmbiBench, the first benchmark incorporating a taxonomy of instruction clarity to shift evaluation from unidirectional instruction following to bidirectional intent alignment. Grounded in Cognitive Gap theory, we propose a taxonomy of four clarity levels: Detailed, Standard, Incomplete, and Ambiguous. We construct a rigorous dataset of 240 ecologically valid tasks across 25 applications, subject to strict review protocols. Furthermore, targeting evaluation in dynamic environments, we develop MUSE (Mobile User Satisfaction Evaluator), an automated framework utilizing an MLLM-as-a-judge multi-agent architecture. MUSE performs fine-grained auditing across three dimensions: Outcome Effectiveness, Execution Quality, and Interaction Quality. Empirical results on AmbiBench reveal the performance boundaries of SoTA agents across different clarity levels, quantify the gains derived from active interaction, and validate the strong correlation between MUSE and human judgment. This work redefines evaluation standards, laying the foundation for next-generation agents capable of truly understanding user intent.
ECG-R1: Protocol-Guided and Modality-Agnostic MLLM for Reliable ECG Interpretation
Feb 04, 2026Electrocardiography (ECG) serves as an indispensable diagnostic tool in clinical practice, yet existing multimodal large language models (MLLMs) remain unreliable for ECG interpretation, often producing plausible but clinically incorrect analyses. To address this, we propose ECG-R1, the first reasoning MLLM designed for reliable ECG interpretation via three innovations. First, we construct the interpretation corpus using \textit{Protocol-Guided Instruction Data Generation}, grounding interpretation in measurable ECG features and monograph-defined quantitative thresholds and diagnostic logic. Second, we present a modality-decoupled architecture with \textit{Interleaved Modality Dropout} to improve robustness and cross-modal consistency when either the ECG signal or ECG image is missing. Third, we present \textit{Reinforcement Learning with ECG Diagnostic Evidence Rewards} to strengthen evidence-grounded ECG interpretation. Additionally, we systematically evaluate the ECG interpretation capabilities of proprietary, open-source, and medical MLLMs, and provide the first quantitative evidence that severe hallucinations are widespread, suggesting that the public should not directly trust these outputs without independent verification. Code and data are publicly available at \href{https://github.com/PKUDigitalHealth/ECG-R1}{here}, and an online platform can be accessed at \href{http://ai.heartvoice.com.cn/ECG-R1/}{here}.
Designing Time Series Experiments in A/B Testing with Transformer Reinforcement Learning
Feb 02, 2026A/B testing has become a gold standard for modern technological companies to conduct policy evaluation. Yet, its application to time series experiments, where policies are sequentially assigned over time, remains challenging. Existing designs suffer from two limitations: (i) they do not fully leverage the entire history for treatment allocation; (ii) they rely on strong assumptions to approximate the objective function (e.g., the mean squared error of the estimated treatment effect) for optimizing the design. We first establish an impossibility theorem showing that failure to condition on the full history leads to suboptimal designs, due to the dynamic dependencies in time series experiments. To address both limitations simultaneously, we next propose a transformer reinforcement learning (RL) approach which leverages transformers to condition allocation on the entire history and employs RL to directly optimize the MSE without relying on restrictive assumptions. Empirical evaluations on synthetic data, a publicly available dispatch simulator, and a real-world ridesharing dataset demonstrate that our proposal consistently outperforms existing designs.
R-GenIMA: Integrating Neuroimaging and Genetics with Interpretable Multimodal AI for Alzheimer's Disease Progression
Dec 22, 2025Early detection of Alzheimer's disease (AD) requires models capable of integrating macro-scale neuroanatomical alterations with micro-scale genetic susceptibility, yet existing multimodal approaches struggle to align these heterogeneous signals. We introduce R-GenIMA, an interpretable multimodal large language model that couples a novel ROI-wise vision transformer with genetic prompting to jointly model structural MRI and single nucleotide polymorphisms (SNPs) variations. By representing each anatomically parcellated brain region as a visual token and encoding SNP profiles as structured text, the framework enables cross-modal attention that links regional atrophy patterns to underlying genetic factors. Applied to the ADNI cohort, R-GenIMA achieves state-of-the-art performance in four-way classification across normal cognition (NC), subjective memory concerns (SMC), mild cognitive impairment (MCI), and AD. Beyond predictive accuracy, the model yields biologically meaningful explanations by identifying stage-specific brain regions and gene signatures, as well as coherent ROI-Gene association patterns across the disease continuum. Attention-based attribution revealed genes consistently enriched for established GWAS-supported AD risk loci, including APOE, BIN1, CLU, and RBFOX1. Stage-resolved neuroanatomical signatures identified shared vulnerability hubs across disease stages alongside stage-specific patterns: striatal involvement in subjective decline, frontotemporal engagement during prodromal impairment, and consolidated multimodal network disruption in AD. These results demonstrate that interpretable multimodal AI can synthesize imaging and genetics to reveal mechanistic insights, providing a foundation for clinically deployable tools that enable earlier risk stratification and inform precision therapeutic strategies in Alzheimer's disease.
AutoLugano: A Deep Learning Framework for Fully Automated Lymphoma Segmentation and Lugano Staging on FDG-PET/CT
Dec 08, 2025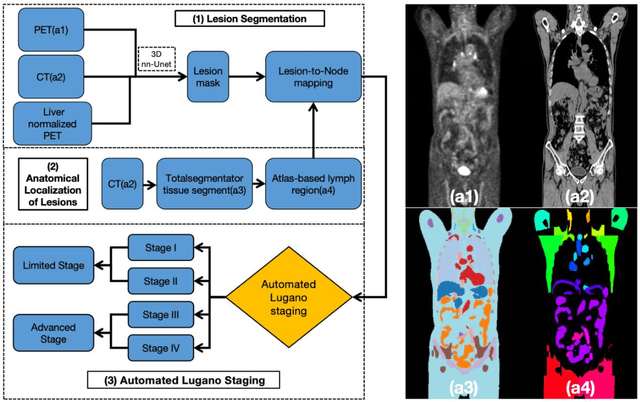
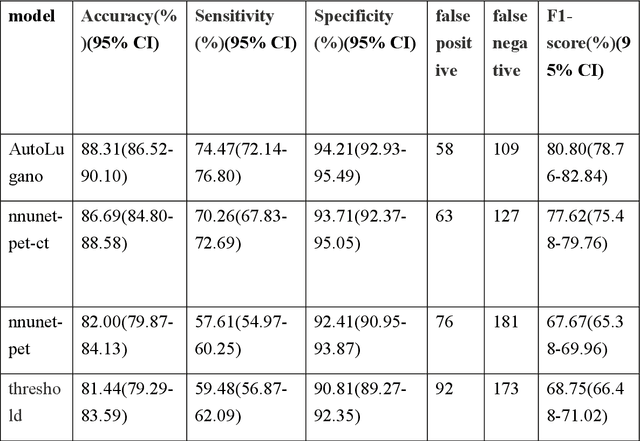
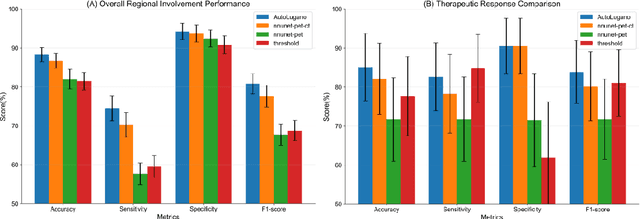
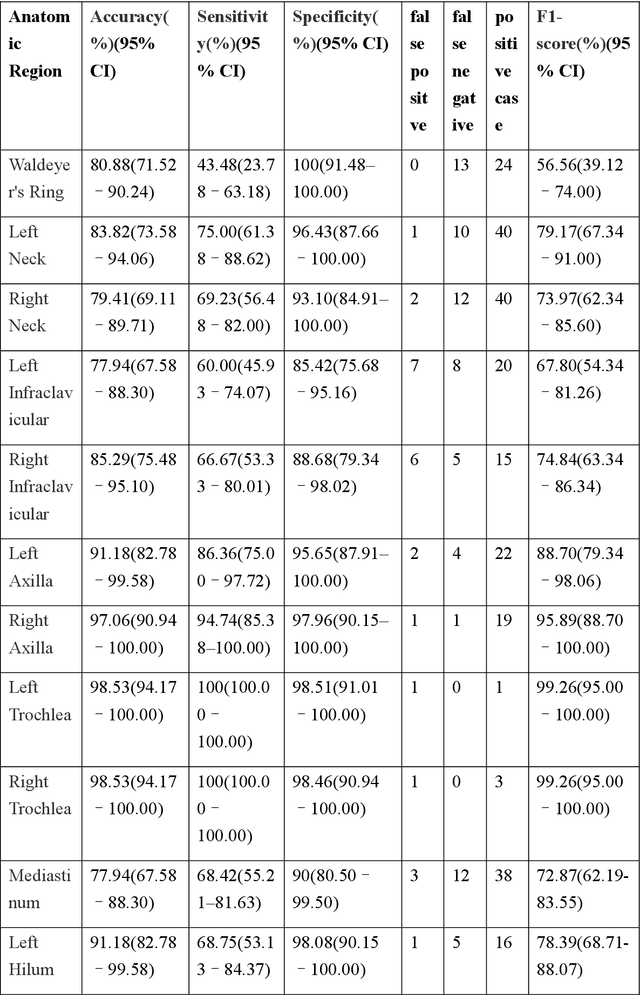
Purpose: To develop a fully automated deep learning system, AutoLugano, for end-to-end lymphoma classification by performing lesion segmentation, anatomical localization, and automated Lugano staging from baseline FDG-PET/CT scans. Methods: The AutoLugano system processes baseline FDG-PET/CT scans through three sequential modules:(1) Anatomy-Informed Lesion Segmentation, a 3D nnU-Net model, trained on multi-channel inputs, performs automated lesion detection (2) Atlas-based Anatomical Localization, which leverages the TotalSegmentator toolkit to map segmented lesions to 21 predefined lymph node regions using deterministic anatomical rules; and (3) Automated Lugano Staging, where the spatial distribution of involved regions is translated into Lugano stages and therapeutic groups (Limited vs. Advanced Stage).The system was trained on the public autoPET dataset (n=1,007) and externally validated on an independent cohort of 67 patients. Performance was assessed using accuracy, sensitivity, specificity, F1-scorefor regional involvement detection and staging agreement. Results: On the external validation set, the proposed model demonstrated robust performance, achieving an overall accuracy of 88.31%, sensitivity of 74.47%, Specificity of 94.21% and an F1-score of 80.80% for regional involvement detection,outperforming baseline models. Most notably, for the critical clinical task of therapeutic stratification (Limited vs. Advanced Stage), the system achieved a high accuracy of 85.07%, with a specificity of 90.48% and a sensitivity of 82.61%.Conclusion: AutoLugano represents the first fully automated, end-to-end pipeline that translates a single baseline FDG-PET/CT scan into a complete Lugano stage. This study demonstrates its strong potential to assist in initial staging, treatment stratification, and supporting clinical decision-making.
Conformal Prediction Beyond the Horizon: Distribution-Free Inference for Policy Evaluation
Oct 29, 2025Reliable uncertainty quantification is crucial for reinforcement learning (RL) in high-stakes settings. We propose a unified conformal prediction framework for infinite-horizon policy evaluation that constructs distribution-free prediction intervals {for returns} in both on-policy and off-policy settings. Our method integrates distributional RL with conformal calibration, addressing challenges such as unobserved returns, temporal dependencies, and distributional shifts. We propose a modular pseudo-return construction based on truncated rollouts and a time-aware calibration strategy using experience replay and weighted subsampling. These innovations mitigate model bias and restore approximate exchangeability, enabling uncertainty quantification even under policy shifts. Our theoretical analysis provides coverage guarantees that account for model misspecification and importance weight estimation. Empirical results, including experiments in synthetic and benchmark environments like Mountain Car, show that our method significantly improves coverage and reliability over standard distributional RL baselines.
Copy-Paste to Mitigate Large Language Model Hallucinations
Oct 01, 2025While Retrieval-Augmented Generation (RAG) enables large language models (LLMs) to generate contextually grounded responses, contextual faithfulness remains challenging as LLMs may not consistently trust provided context, leading to hallucinations that undermine reliability. We observe an inverse correlation between response copying degree and context-unfaithful hallucinations on RAGTruth, suggesting that higher copying degrees reduce hallucinations by fostering genuine contextual belief. We propose CopyPasteLLM, obtained through two-stage high-copying response preference training. We design three prompting methods to enhance copying degree, demonstrating that high-copying responses achieve superior contextual faithfulness and hallucination control. These approaches enable a fully automated pipeline that transforms generated responses into high-copying preference data for training CopyPasteLLM. On FaithEval, ConFiQA and PubMedQA, CopyPasteLLM achieves best performance in both counterfactual and original contexts, remarkably with 12.2% to 24.5% accuracy improvements on FaithEval over the best baseline, while requiring only 365 training samples -- 1/50th of baseline data. To elucidate CopyPasteLLM's effectiveness, we propose the Context-Parameter Copying Capturing algorithm. Interestingly, this reveals that CopyPasteLLM recalibrates reliance on internal parametric knowledge rather than external knowledge during generation. All codes are available at https://github.com/longyongchao/CopyPasteLLM
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Aug 17, 2025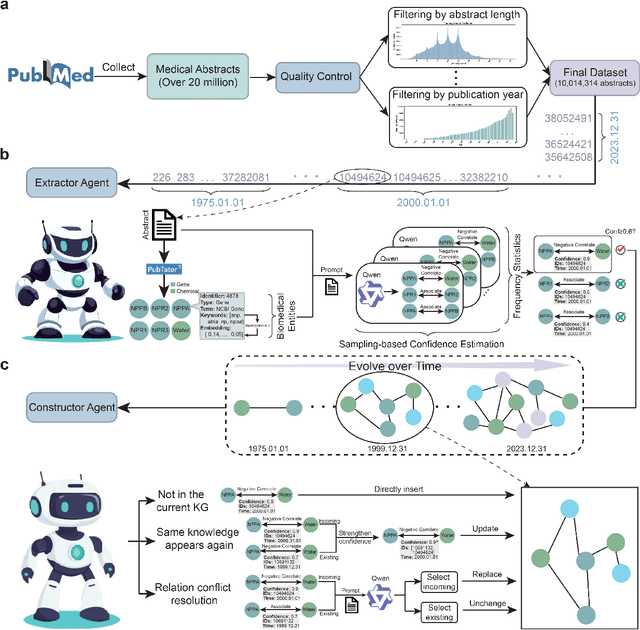
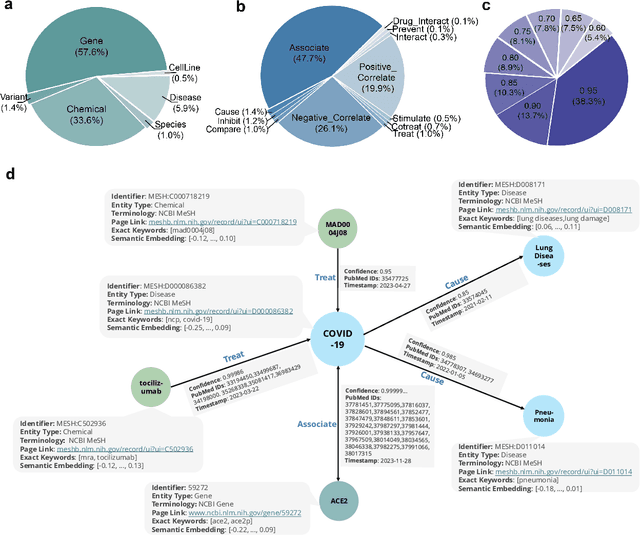
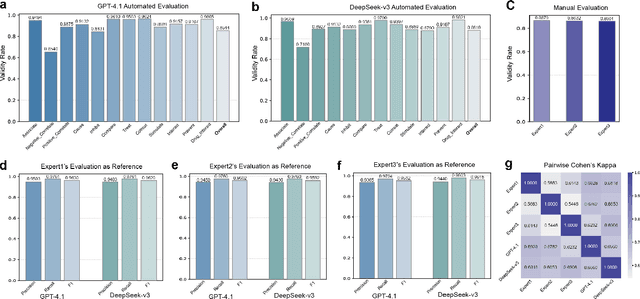
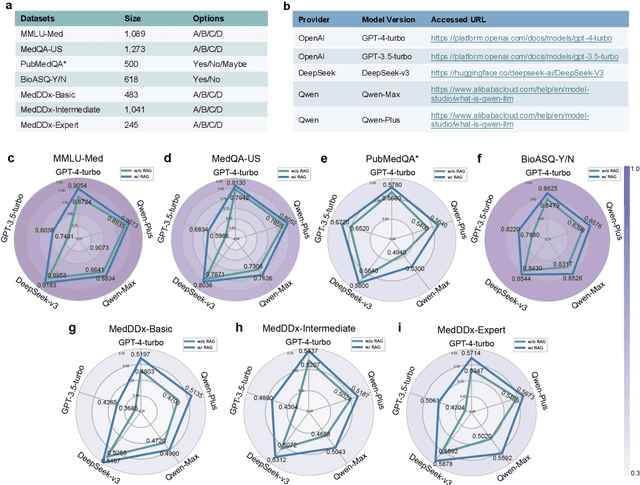
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90\%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG's value in literature-based drug repurposing via confidence-aware causal inference.
CaPulse: Detecting Anomalies by Tuning in to the Causal Rhythms of Time Series
Aug 06, 2025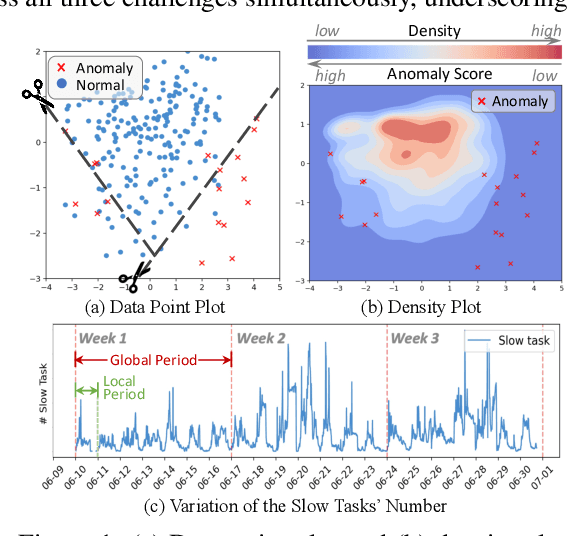
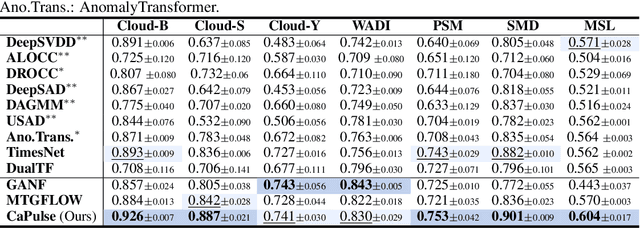

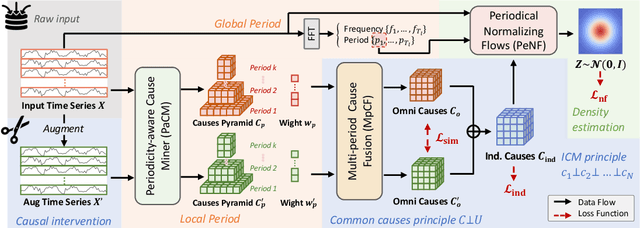
Time series anomaly detection has garnered considerable attention across diverse domains. While existing methods often fail to capture the underlying mechanisms behind anomaly generation in time series data. In addition, time series anomaly detection often faces several data-related inherent challenges, i.e., label scarcity, data imbalance, and complex multi-periodicity. In this paper, we leverage causal tools and introduce a new causality-based framework, CaPulse, which tunes in to the underlying causal pulse of time series data to effectively detect anomalies. Concretely, we begin by building a structural causal model to decipher the generation processes behind anomalies. To tackle the challenges posed by the data, we propose Periodical Normalizing Flows with a novel mask mechanism and carefully designed periodical learners, creating a periodicity-aware, density-based anomaly detection approach. Extensive experiments on seven real-world datasets demonstrate that CaPulse consistently outperforms existing methods, achieving AUROC improvements of 3% to 17%, with enhanced interpretability.