 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVP-AP: Self-supervised Automatic View Positioning in 3D cardiac CT via Atlas Prompting
Apr 08, 2025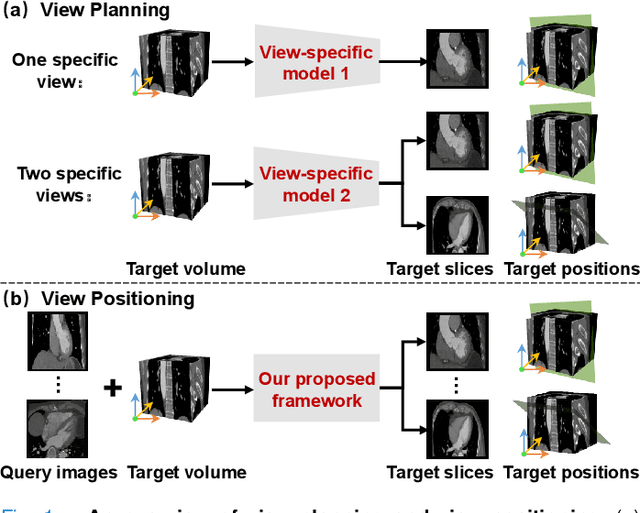
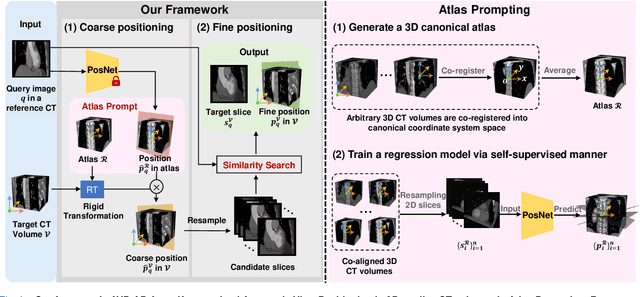
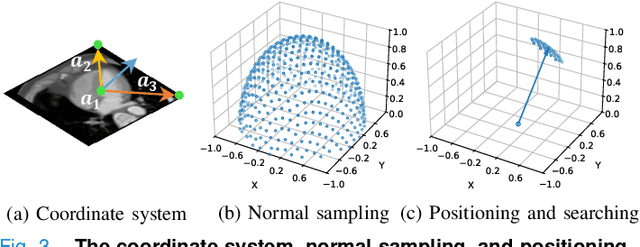
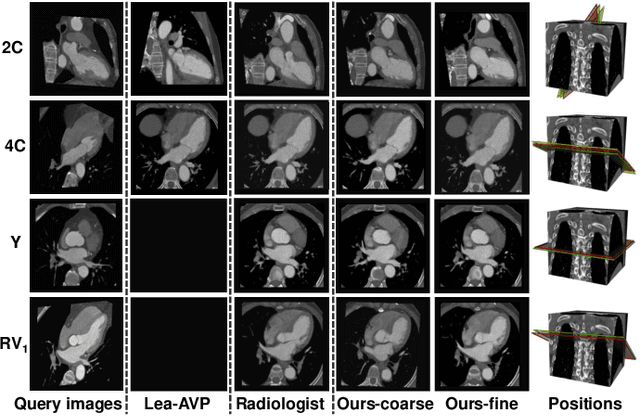
Automatic view positioning is crucial for cardiac computed tomography (CT) examinations, including disease diagnosis and surgical planning. However, it is highly challenging due to individual variability and large 3D search space. Existing work needs labor-intensive and time-consuming manual annotations to train view-specific models, which are limited to predicting only a fixed set of planes. However, in real clinical scenarios, the challenge of positioning semantic 2D slices with any orientation into varying coordinate space in arbitrary 3D volume remains unsolved. We thus introduce a novel framework, AVP-AP, the first to use Atlas Prompting for self-supervised Automatic View Positioning in the 3D CT volume. Specifically, this paper first proposes an atlas prompting method, which generates a 3D canonical atlas and trains a network to map slices into their corresponding positions in the atlas space via a self-supervised manner. Then, guided by atlas prompts corresponding to the given query images in a reference CT, we identify the coarse positions of slices in the target CT volume using rigid transformation between the 3D atlas and target CT volume, effectively reducing the search space. Finally, we refine the coarse positions by maximizing the similarity between the predicted slices and the query images in the feature space of a given foundation model. Our framework is flexible and efficient compared to other methods, outperforming other methods by 19.8% average structural similarity (SSIM) in arbitrary view positioning and achieving 9% SSIM in two-chamber view compared to four radiologists. Meanwhile, experiments on a public dataset validate our framework's generalizability.
* 12 pages, 8 figures, published to TMI
EVA-S2PLoR: A Secure Element-wise Multiplication Meets Logistic Regression on Heterogeneous Database
Jan 09, 2025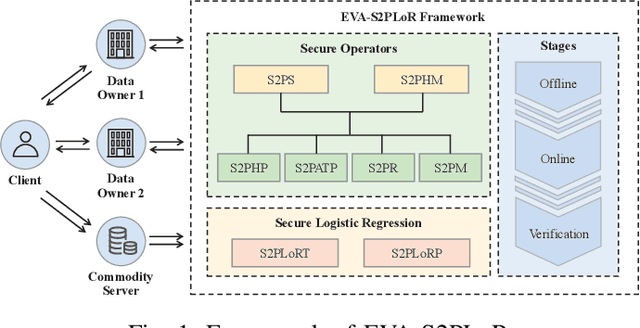
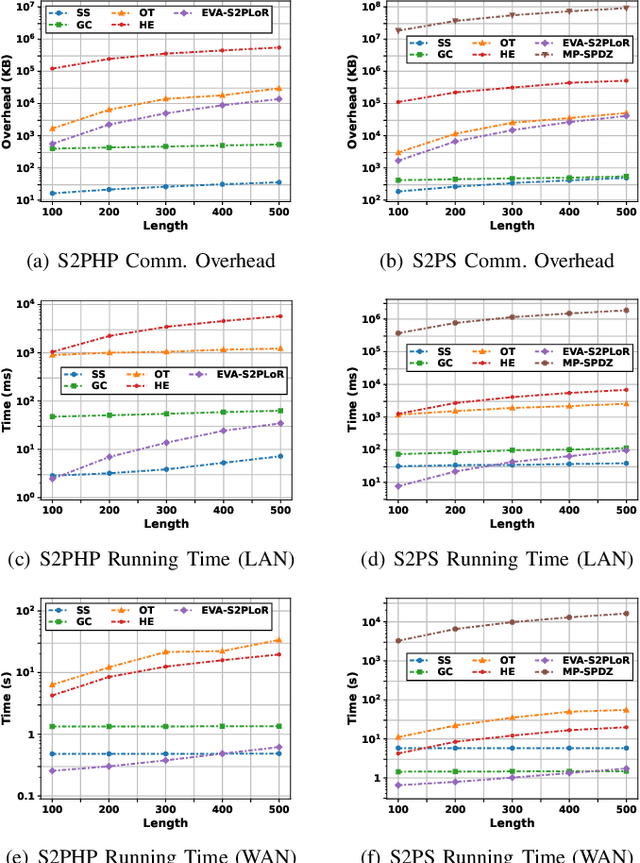
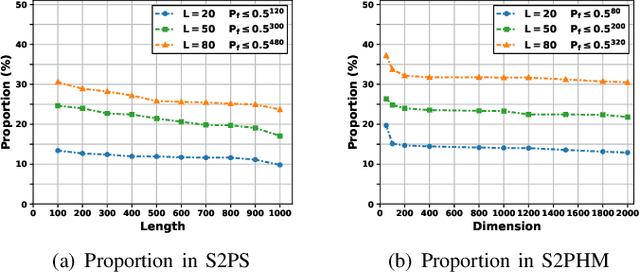
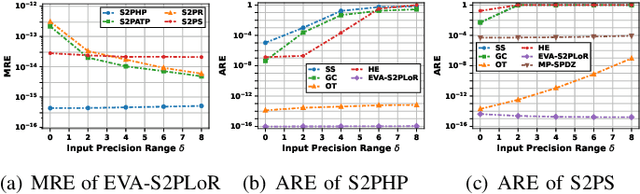
Accurate nonlinear computation is a key challenge in privacy-preserving machine learning (PPML). Most existing frameworks approximate it through linear operations, resulting in significant precision loss. This paper proposes an efficient, verifiable and accurate security 2-party logistic regression framework (EVA-S2PLoR), which achieves accurate nonlinear function computation through a novel secure element-wise multiplication protocol and its derived protocols. Our framework primarily includes secure 2-party vector element-wise multiplication, addition to multiplication, reciprocal, and sigmoid function based on data disguising technology, where high efficiency and accuracy are guaranteed by the simple computation flow based on the real number domain and the few number of fixed communication rounds. We provide secure and robust anomaly detection through dimension transformation and Monte Carlo methods. EVA-S2PLoR outperforms many advanced frameworks in terms of precision (improving the performance of the sigmoid function by about 10 orders of magnitude compared to most frameworks) and delivers the best overall performance in secure logistic regression experiments.
Temporal Action Localization with Enhanced Instant Discriminability
Sep 11, 2023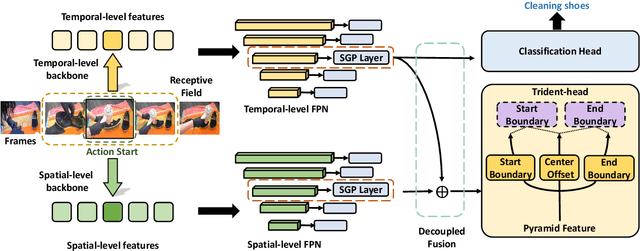
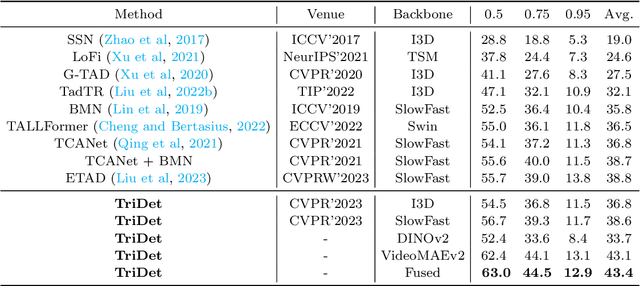
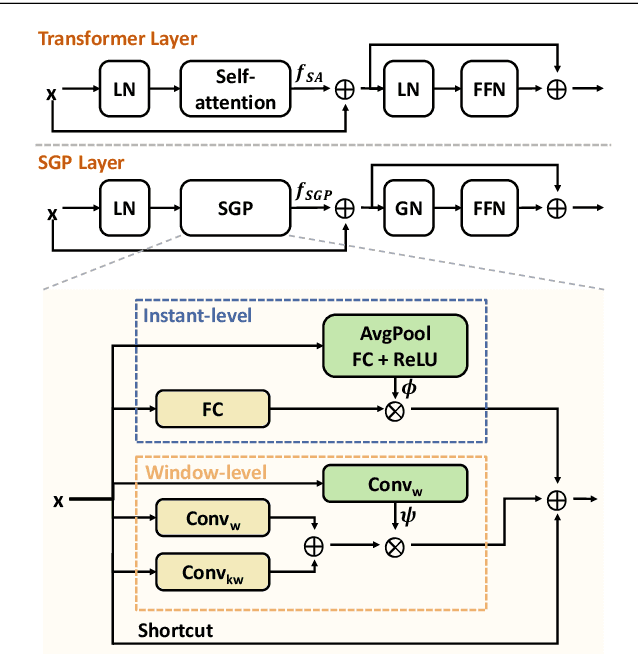
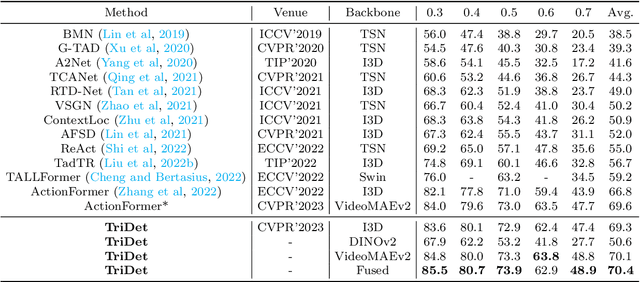
Temporal action detection (TAD) aims to detect all action boundaries and their corresponding categories in an untrimmed video. The unclear boundaries of actions in videos often result in imprecise predictions of action boundaries by existing methods. To resolve this issue, we propose a one-stage framework named TriDet. First, we propose a Trident-head to model the action boundary via an estimated relative probability distribution around the boundary. Then, we analyze the rank-loss problem (i.e. instant discriminability deterioration) in transformer-based methods and propose an efficient scalable-granularity perception (SGP) layer to mitigate this issue. To further push the limit of instant discriminability in the video backbone, we leverage the strong representation capability of pretrained large models and investigate their performance on TAD. Last, considering the adequate spatial-temporal context for classification, we design a decoupled feature pyramid network with separate feature pyramids to incorporate rich spatial context from the large model for localization. Experimental results demonstrate the robustness of TriDet and its state-of-the-art performance on multiple TAD datasets, including hierarchical (multilabel) TAD datasets.
FVP: Fourier Visual Prompting for Source-Free Unsupervised Domain Adaptation of Medical Image Segmentation
Apr 26, 2023Medical image segmentation methods normally perform poorly when there is a domain shift between training and testing data. Unsupervised Domain Adaptation (UDA) addresses the domain shift problem by training the model using both labeled data from the source domain and unlabeled data from the target domain. Source-Free UDA (SFUDA) was recently proposed for UDA without requiring the source data during the adaptation, due to data privacy or data transmission issues, which normally adapts the pre-trained deep model in the testing stage. However, in real clinical scenarios of medical image segmentation, the trained model is normally frozen in the testing stage. In this paper, we propose Fourier Visual Prompting (FVP) for SFUDA of medical image segmentation. Inspired by prompting learning in natural language processing, FVP steers the frozen pre-trained model to perform well in the target domain by adding a visual prompt to the input target data. In FVP, the visual prompt is parameterized using only a small amount of low-frequency learnable parameters in the input frequency space, and is learned by minimizing the segmentation loss between the predicted segmentation of the prompted target image and reliable pseudo segmentation label of the target image under the frozen model. To our knowledge, FVP is the first work to apply visual prompts to SFUDA for medical image segmentation. The proposed FVP is validated using three public datasets, and experiments demonstrate that FVP yields better segmentation results, compared with various existing methods.
ARShoe: Real-Time Augmented Reality Shoe Try-on System on Smartphones
Aug 24, 2021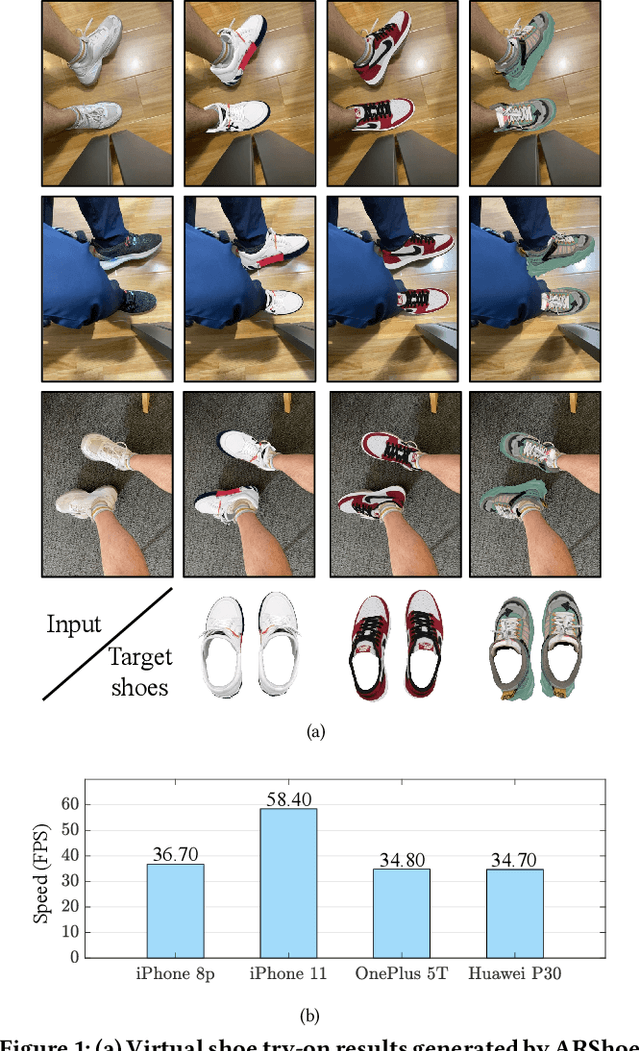
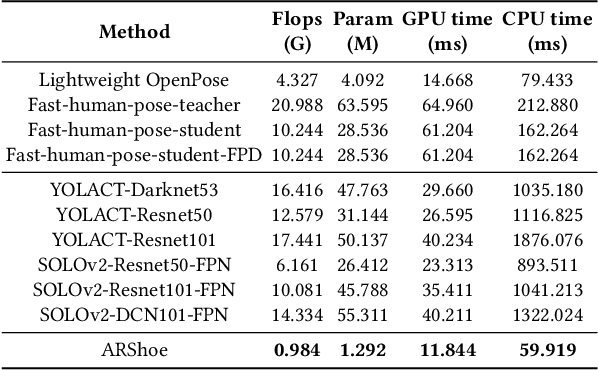
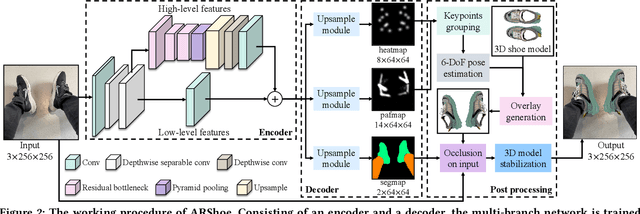
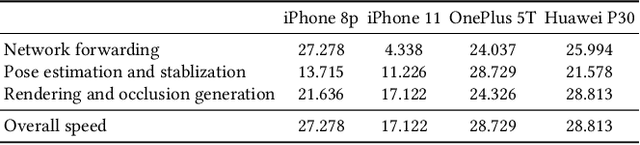
Virtual try-on technology enables users to try various fashion items using augmented reality and provides a convenient online shopping experience. However, most previous works focus on the virtual try-on for clothes while neglecting that for shoes, which is also a promising task. To this concern, this work proposes a real-time augmented reality virtual shoe try-on system for smartphones, namely ARShoe. Specifically, ARShoe adopts a novel multi-branch network to realize pose estimation and segmentation simultaneously. A solution to generate realistic 3D shoe model occlusion during the try-on process is presented. To achieve a smooth and stable try-on effect, this work further develop a novel stabilization method. Moreover, for training and evaluation, we construct the very first large-scale foot benchmark with multiple virtual shoe try-on task-related labels annotated. Exhaustive experiments on our newly constructed benchmark demonstrate the satisfying performance of ARShoe. Practical tests on common smartphones validate the real-time performance and stabilization of the proposed approach.
Real-Time Monocular Human Depth Estimation and Segmentation on Embedded Systems
Aug 24, 2021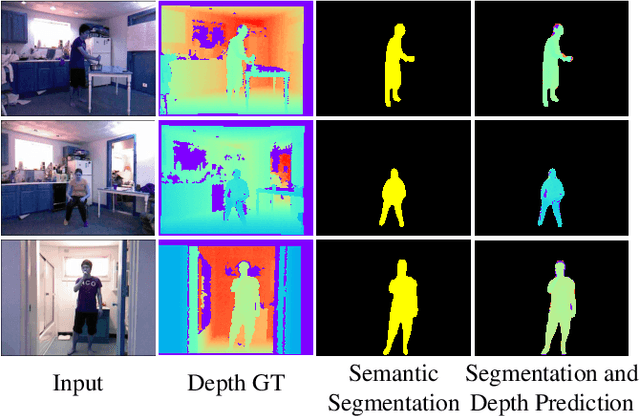
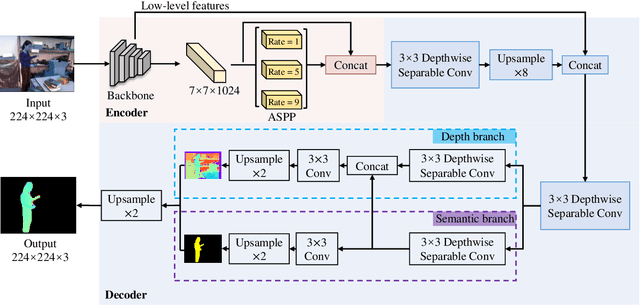
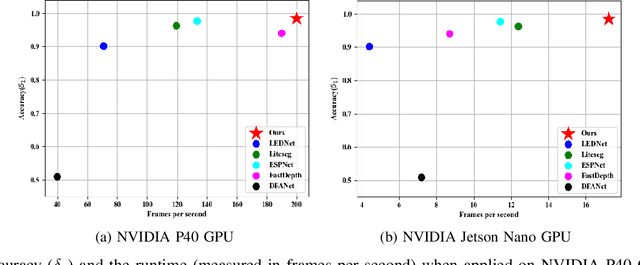
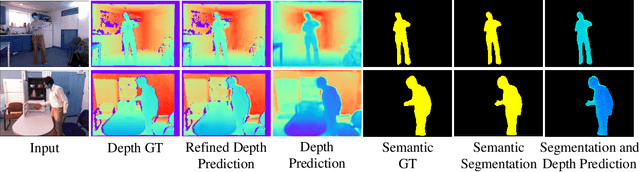
Estimating a scene's depth to achieve collision avoidance against moving pedestrians is a crucial and fundamental problem in the robotic field. This paper proposes a novel, low complexity network architecture for fast and accurate human depth estimation and segmentation in indoor environments, aiming to applications for resource-constrained platforms (including battery-powered aerial, micro-aerial, and ground vehicles) with a monocular camera being the primary perception module. Following the encoder-decoder structure, the proposed framework consists of two branches, one for depth prediction and another for semantic segmentation. Moreover, network structure optimization is employed to improve its forward inference speed. Exhaustive experiments on three self-generated datasets prove our pipeline's capability to execute in real-time, achieving higher frame rates than contemporary state-of-the-art frameworks (114.6 frames per second on an NVIDIA Jetson Nano GPU with TensorRT) while maintaining comparable accuracy.
Brain Age Estimation From MRI Using Cascade Networks with Ranking Loss
Jun 06, 2021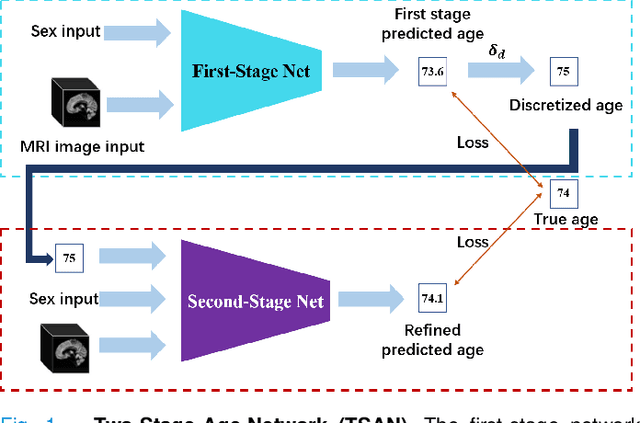
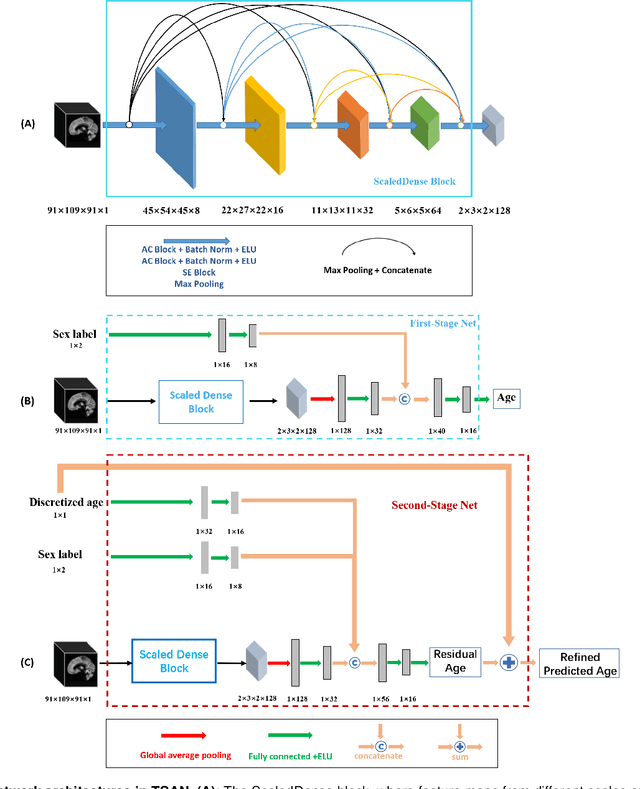
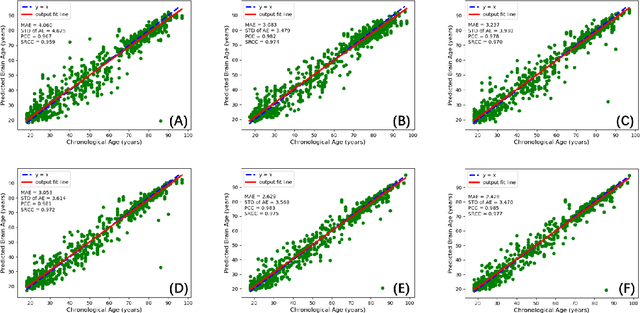
Chronological age of healthy people is able to be predicted accurately using deep neural networks from neuroimaging data, and the predicted brain age could serve as a biomarker for detecting aging-related diseases. In this paper, a novel 3D convolutional network, called two-stage-age-network (TSAN), is proposed to estimate brain age from T1-weighted MRI data. Compared with existing methods, TSAN has the following improvements. First, TSAN uses a two-stage cascade network architecture, where the first-stage network estimates a rough brain age, then the second-stage network estimates the brain age more accurately from the discretized brain age by the first-stage network. Second, to our knowledge, TSAN is the first work to apply novel ranking losses in brain age estimation, together with the traditional mean square error (MSE) loss. Third, densely connected paths are used to combine feature maps with different scales. The experiments with $6586$ MRIs showed that TSAN could provide accurate brain age estimation, yielding mean absolute error (MAE) of $2.428$ and Pearson's correlation coefficient (PCC) of $0.985$, between the estimated and chronological ages. Furthermore, using the brain age gap between brain age and chronological age as a biomarker, Alzheimer's disease (AD) and Mild Cognitive Impairment (MCI) can be distinguished from healthy control (HC) subjects by support vector machine (SVM). Classification AUC in AD/HC and MCI/HC was $0.904$ and $0.823$, respectively. It showed that brain age gap is an effective biomarker associated with risk of dementia, and has potential for early-stage dementia risk screening. The codes and trained models have been released on GitHub: https://github.com/Milan-BUAA/TSAN-brain-age-estimation.
FastHand: Fast Hand Pose Estimation From A Monocular Camera
Feb 14, 2021

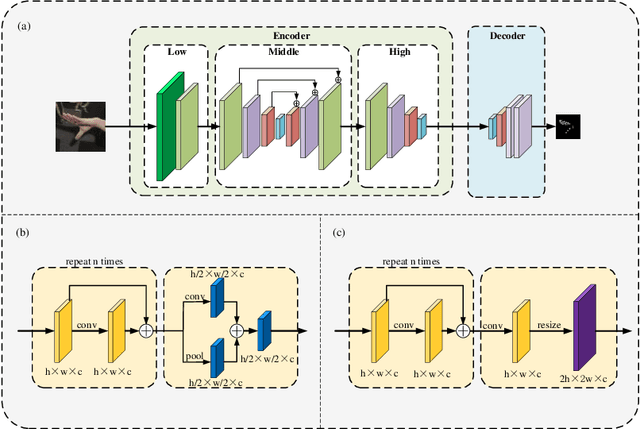

Hand gesture recognition constitutes the initial step in most methods related to human-robot interaction. There are two key challenges in this task. The first one corresponds to the difficulty of achieving stable and accurate hand landmark predictions in real-world scenarios, while the second to the decreased time of forward inference. In this paper, we propose a fast and accurate framework for hand pose estimation, dubbed as "FastHand". Using a lightweight encoder-decoder network architecture, we achieve to fulfil the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.
Fast and Incremental Loop Closure Detection with Deep Features and Proximity Graphs
Sep 29, 2020

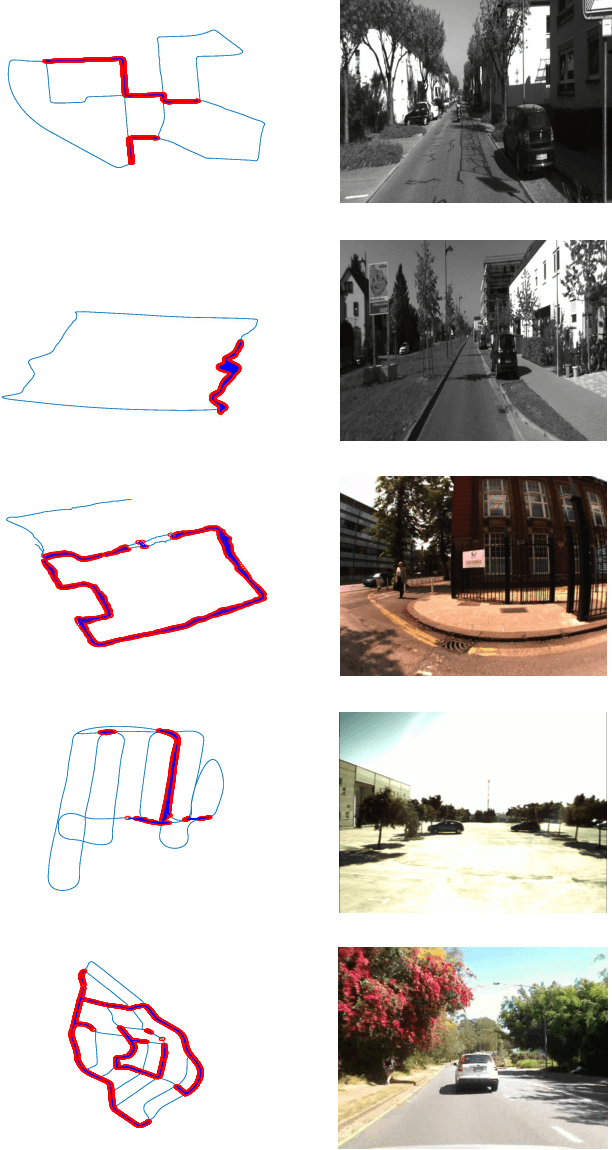
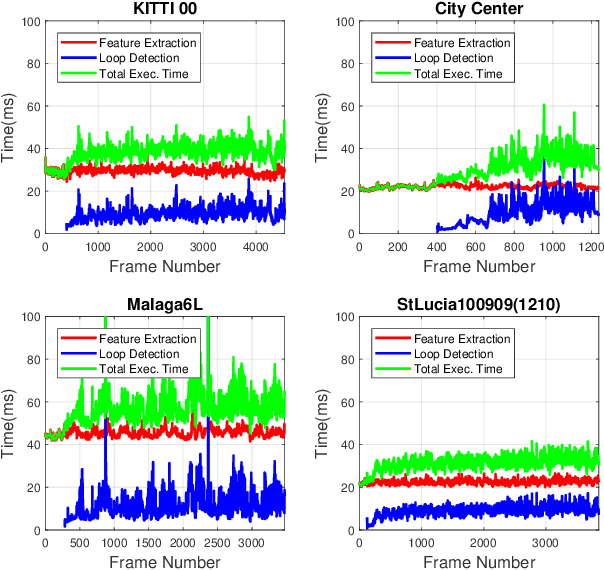
In recent years, methods concerning the place recognition task have been extensively examined from the robotics community within the scope of simultaneous localization and mapping applications. In this article, an appearance-based loop closure detection pipeline is proposed, entitled "FILD++" (Fast and Incremental Loop closure Detection). When the incoming camera observation arrives, global and local visual features are extracted through two passes of a single convolutional neural network. Subsequently, a modified hierarchical-navigable small-world graph incrementally generates a visual database that represents the robot's traversed path based on global features. Given the query sensor measurement, similar locations from the trajectory are retrieved using these representations, while an image-to-image pairing is further evaluated thanks to the spatial information provided by the local features. Exhaustive experiments on several publicly-available datasets exhibit the system's high performance and low execution time compared to other contemporary state-of-the-art pipelines.