 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVP: Fourier Visual Prompting for Source-Free Unsupervised Domain Adaptation of Medical Image Segmentation
Apr 26, 2023Medical image segmentation methods normally perform poorly when there is a domain shift between training and testing data. Unsupervised Domain Adaptation (UDA) addresses the domain shift problem by training the model using both labeled data from the source domain and unlabeled data from the target domain. Source-Free UDA (SFUDA) was recently proposed for UDA without requiring the source data during the adaptation, due to data privacy or data transmission issues, which normally adapts the pre-trained deep model in the testing stage. However, in real clinical scenarios of medical image segmentation, the trained model is normally frozen in the testing stage. In this paper, we propose Fourier Visual Prompting (FVP) for SFUDA of medical image segmentation. Inspired by prompting learning in natural language processing, FVP steers the frozen pre-trained model to perform well in the target domain by adding a visual prompt to the input target data. In FVP, the visual prompt is parameterized using only a small amount of low-frequency learnable parameters in the input frequency space, and is learned by minimizing the segmentation loss between the predicted segmentation of the prompted target image and reliable pseudo segmentation label of the target image under the frozen model. To our knowledge, FVP is the first work to apply visual prompts to SFUDA for medical image segmentation. The proposed FVP is validated using three public datasets, and experiments demonstrate that FVP yields better segmentation results, compared with various existing methods.
Brain Age Estimation From MRI Using Cascade Networks with Ranking Loss
Jun 06, 2021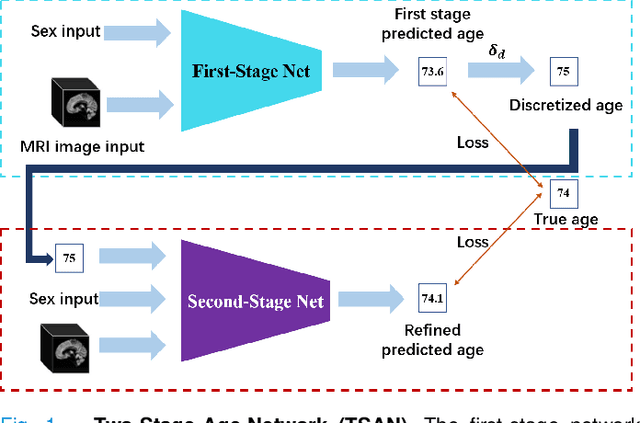
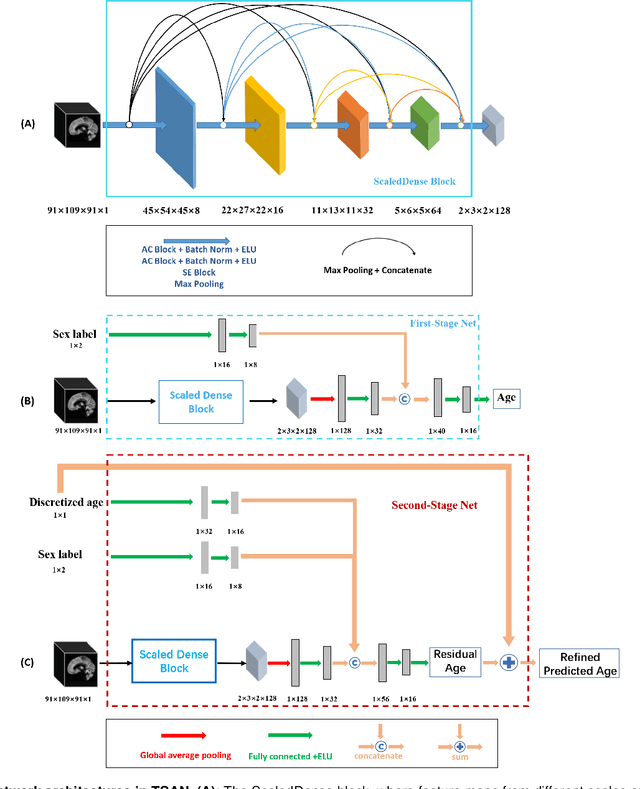
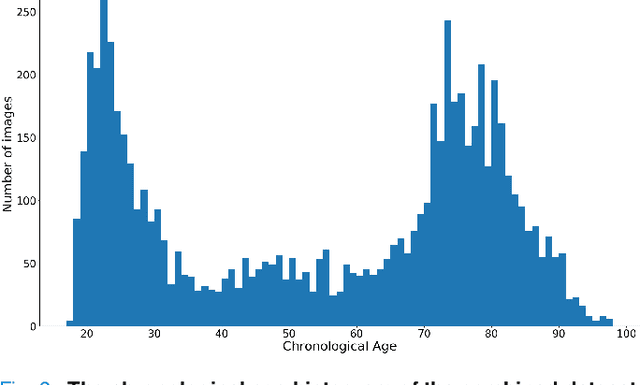
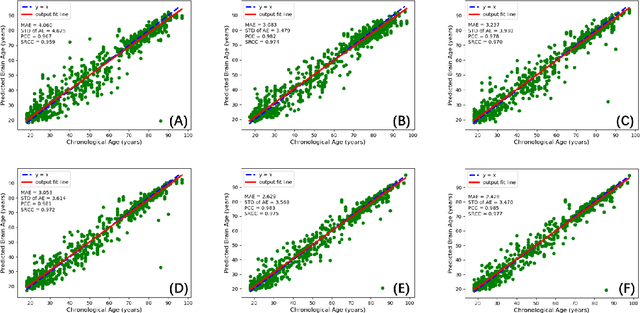
Chronological age of healthy people is able to be predicted accurately using deep neural networks from neuroimaging data, and the predicted brain age could serve as a biomarker for detecting aging-related diseases. In this paper, a novel 3D convolutional network, called two-stage-age-network (TSAN), is proposed to estimate brain age from T1-weighted MRI data. Compared with existing methods, TSAN has the following improvements. First, TSAN uses a two-stage cascade network architecture, where the first-stage network estimates a rough brain age, then the second-stage network estimates the brain age more accurately from the discretized brain age by the first-stage network. Second, to our knowledge, TSAN is the first work to apply novel ranking losses in brain age estimation, together with the traditional mean square error (MSE) loss. Third, densely connected paths are used to combine feature maps with different scales. The experiments with $6586$ MRIs showed that TSAN could provide accurate brain age estimation, yielding mean absolute error (MAE) of $2.428$ and Pearson's correlation coefficient (PCC) of $0.985$, between the estimated and chronological ages. Furthermore, using the brain age gap between brain age and chronological age as a biomarker, Alzheimer's disease (AD) and Mild Cognitive Impairment (MCI) can be distinguished from healthy control (HC) subjects by support vector machine (SVM). Classification AUC in AD/HC and MCI/HC was $0.904$ and $0.823$, respectively. It showed that brain age gap is an effective biomarker associated with risk of dementia, and has potential for early-stage dementia risk screening. The codes and trained models have been released on GitHub: https://github.com/Milan-BUAA/TSAN-brain-age-estimation.
Adversarial Data Encryption
Feb 11, 2020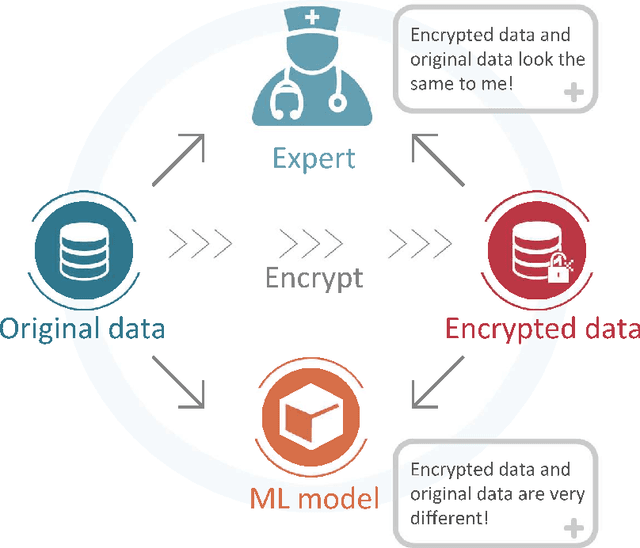

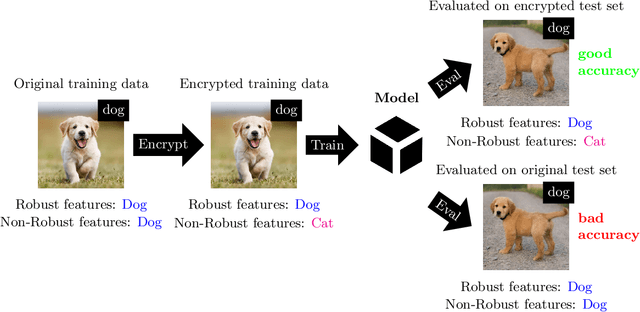

In the big data era, many organizations face the dilemma of data sharing. Regular data sharing is often necessary for human-centered discussion and communication, especially in medical scenarios. However, unprotected data sharing may also lead to data leakage. Inspired by adversarial attack, we propose a method for data encryption, so that for human beings the encrypted data look identical to the original version, but for machine learning methods they are misleading. To show the effectiveness of our method, we collaborate with the Beijing Tiantan Hospital, which has a world leading neurological center. We invite $3$ doctors to manually inspect our encryption method based on real world medical images. The results show that the encrypted images can be used for diagnosis by the doctors, but not by machine learning methods.
HiNet: Hierarchical Classification with Neural Network
Jan 12, 2018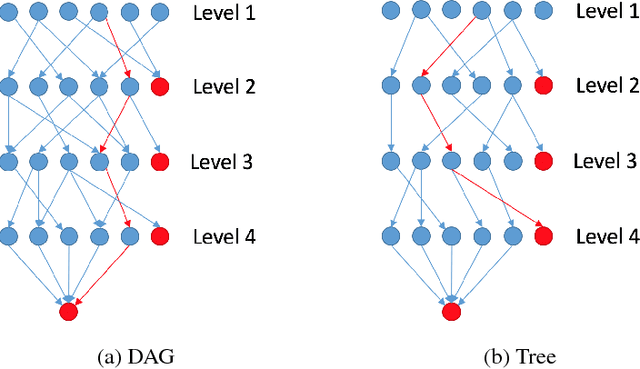

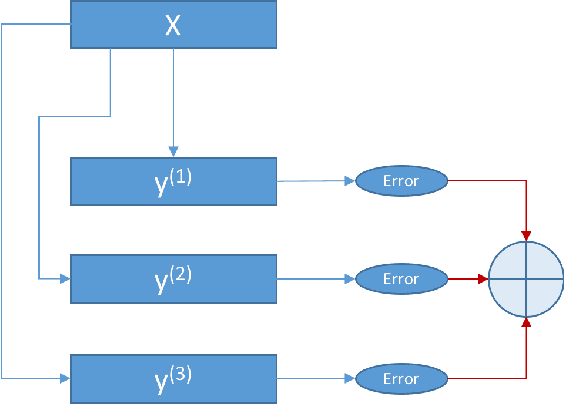
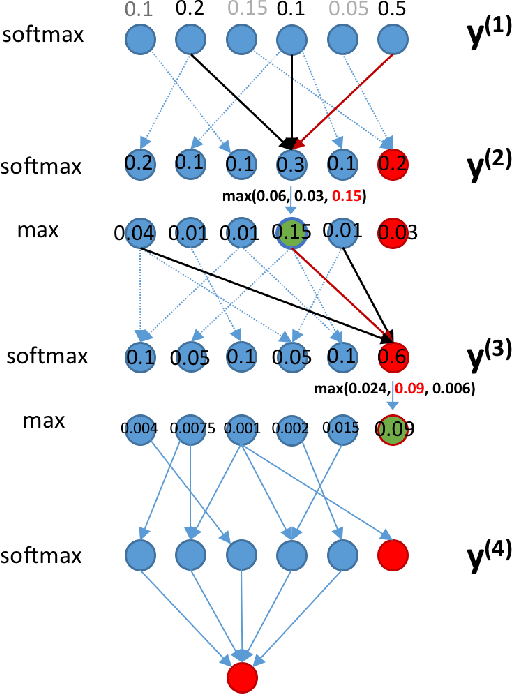
Traditionally, classifying large hierarchical labels with more than 10000 distinct traces can only be achieved with flatten labels. Although flatten labels is feasible, it misses the hierarchical information in the labels. Hierarchical models like HSVM by \cite{vural2004hierarchical} becomes impossible to train because of the sheer number of SVMs in the whole architecture. We developed a hierarchical architecture based on neural networks that is simple to train. Also, we derived an inference algorithm that can efficiently infer the MAP (maximum a posteriori) trace guaranteed by our theorems. Furthermore, the complexity of the model is only $O(n^2)$ compared to $O(n^h)$ in a flatten model, where $h$ is the height of the hierarchy.
Character-Based Text Classification using Top Down Semantic Model for Sentence Representation
May 29, 2017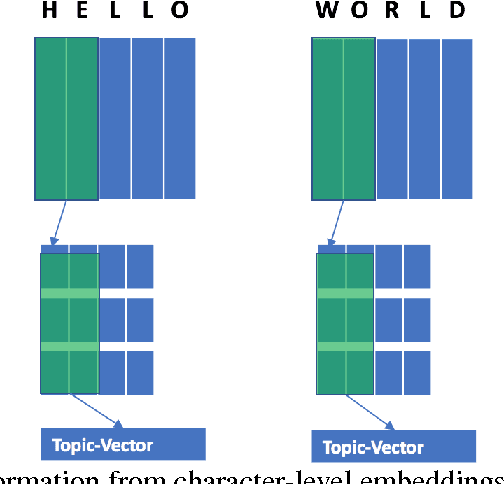
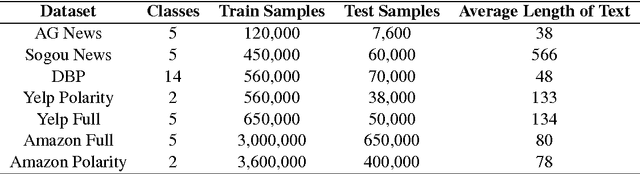
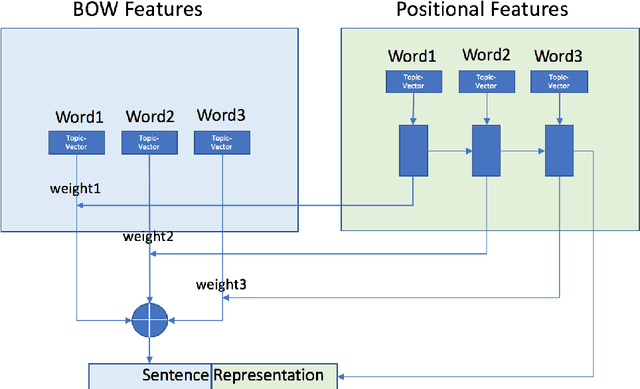

Despite the success of deep learning on many fronts especially image and speech, its application in text classification often is still not as good as a simple linear SVM on n-gram TF-IDF representation especially for smaller datasets. Deep learning tends to emphasize on sentence level semantics when learning a representation with models like recurrent neural network or recursive neural network, however from the success of TF-IDF representation, it seems a bag-of-words type of representation has its strength. Taking advantage of both representions, we present a model known as TDSM (Top Down Semantic Model) for extracting a sentence representation that considers both the word-level semantics by linearly combining the words with attention weights and the sentence-level semantics with BiLSTM and use it on text classification. We apply the model on characters and our results show that our model is better than all the other character-based and word-based convolutional neural network models by \cite{zhang15} across seven different datasets with only 1\% of their parameters. We also demonstrate that this model beats traditional linear models on TF-IDF vectors on small and polished datasets like news article in which typically deep learning models surrender.
Multi-Modal Hybrid Deep Neural Network for Speech Enhancement
Jun 15, 2016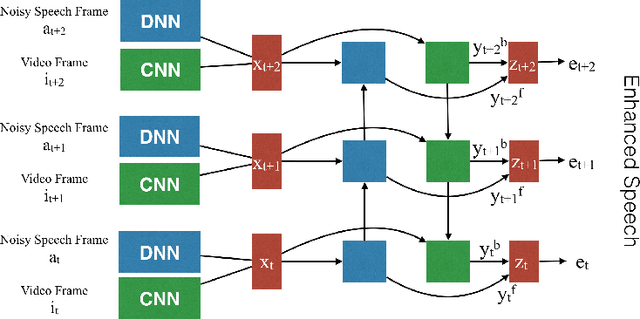
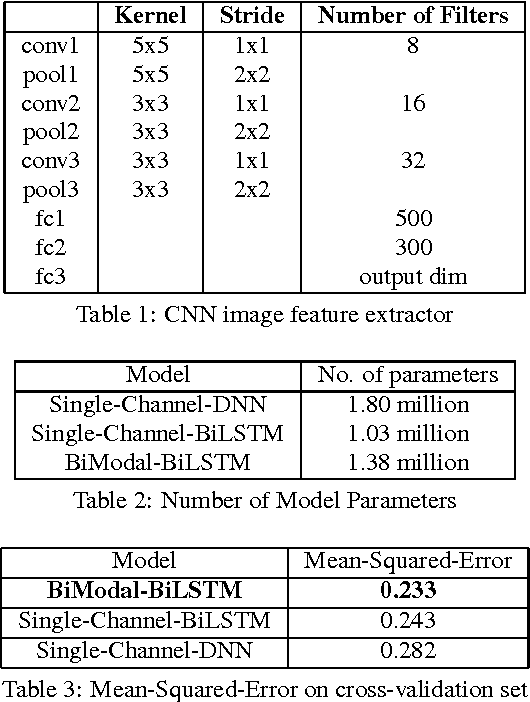
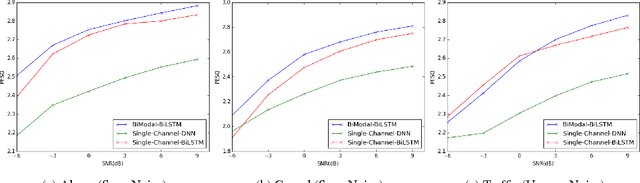
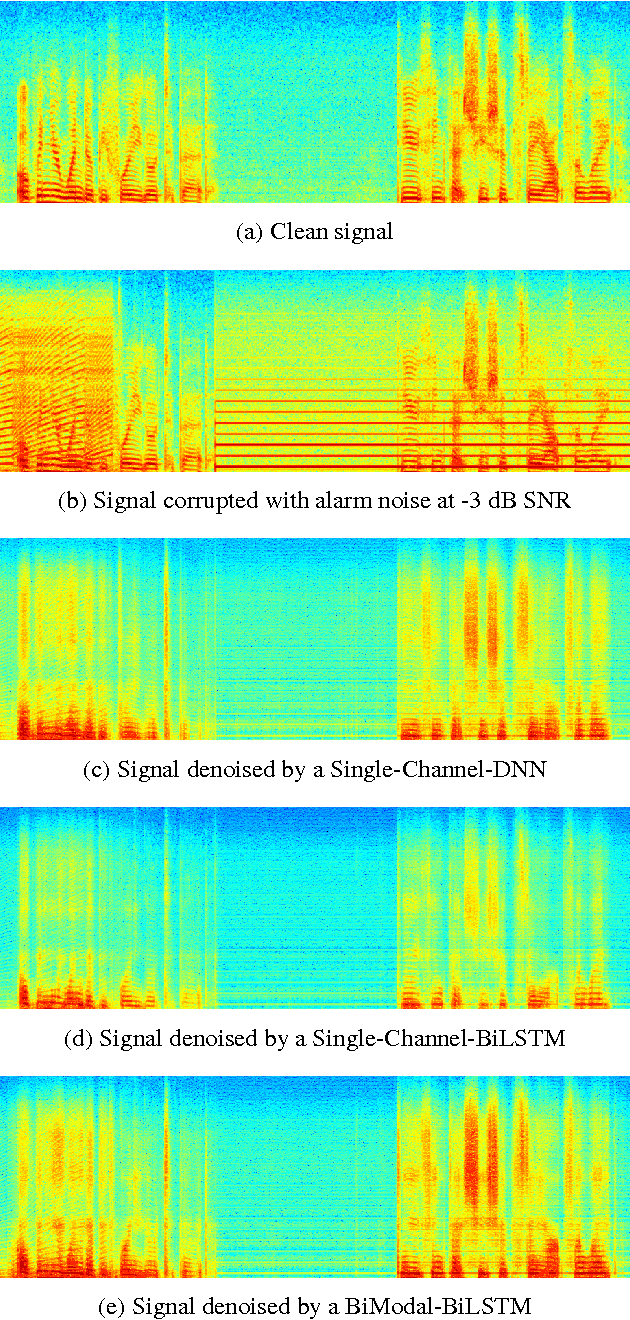
Deep Neural Networks (DNN) have been successful in en- hancing noisy speech signals. Enhancement is achieved by learning a nonlinear mapping function from the features of the corrupted speech signal to that of the reference clean speech signal. The quality of predicted features can be improved by providing additional side channel information that is robust to noise, such as visual cues. In this paper we propose a novel deep learning model inspired by insights from human audio visual perception. In the proposed unified hybrid architecture, features from a Convolution Neural Network (CNN) that processes the visual cues and features from a fully connected DNN that processes the audio signal are integrated using a Bidirectional Long Short-Term Memory (BiLSTM) network. The parameters of the hybrid model are jointly learned using backpropagation. We compare the quality of enhanced speech from the hybrid models with those from traditional DNN and BiLSTM models.
Deep Denoising Auto-encoder for Statistical Speech Synthesis
Jun 17, 2015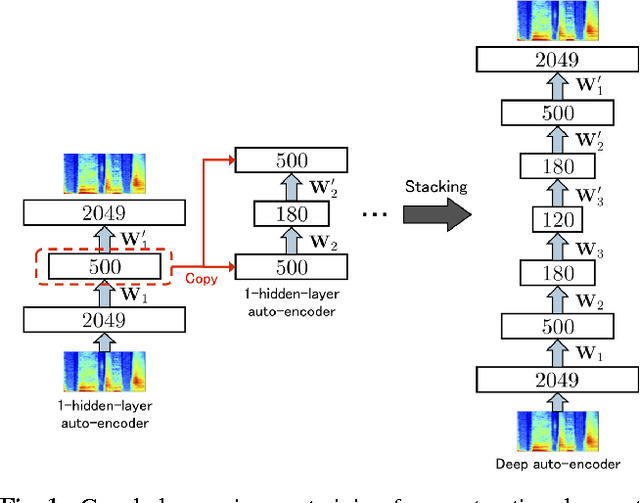
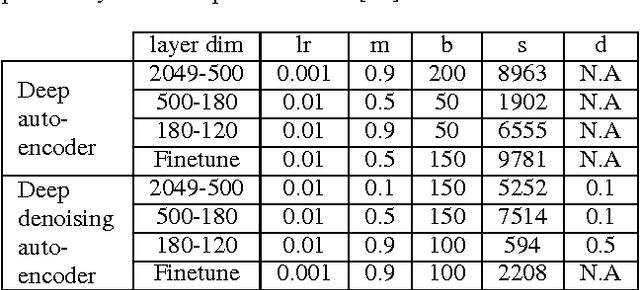
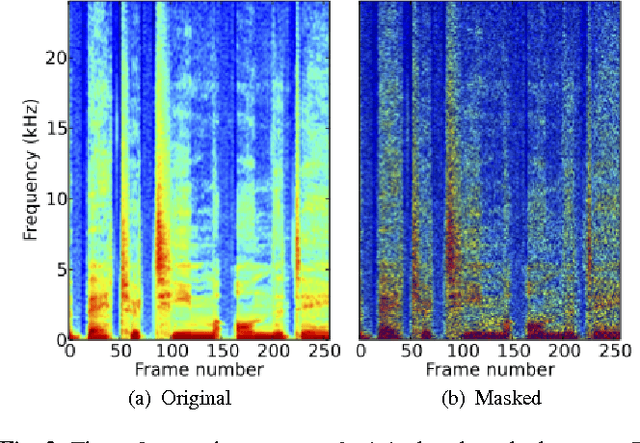
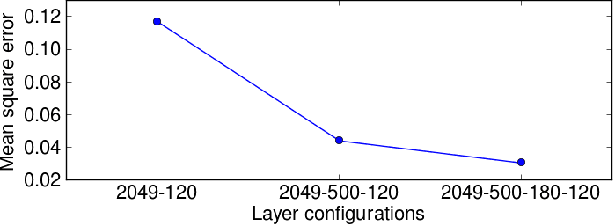
This paper proposes a deep denoising auto-encoder technique to extract better acoustic features for speech synthesis. The technique allows us to automatically extract low-dimensional features from high dimensional spectral features in a non-linear, data-driven, unsupervised way. We compared the new stochastic feature extractor with conventional mel-cepstral analysis in analysis-by-synthesis and text-to-speech experiments. Our results confirm that the proposed method increases the quality of synthetic speech in both experiments.