 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk, Evaluate, Diagnose: User-aware Agent Evaluation with Automated Error Analysis
Mar 16, 2026Agent applications are increasingly adopted to automate workflows across diverse tasks. However, due to the heterogeneous domains they operate in, it is challenging to create a scalable evaluation framework. Prior works each employ their own methods to determine task success, such as database lookups, regex match, etc., adding complexity to the development of a unified agent evaluation approach. Moreover, they do not systematically account for the user's role nor expertise in the interaction, providing incomplete insights into the agent's performance. We argue that effective agent evaluation goes beyond correctness alone, incorporating conversation quality, efficiency and systematic diagnosis of agent errors. To address this, we introduce the TED framework (Talk, Evaluate, Diagnose). (1) Talk: We leverage reusable, generic expert and non-expert user persona templates for user-agent interaction. (2) Evaluate: We adapt existing datasets by representing subgoals-such as tool signatures, and responses-as natural language grading notes, evaluated automatically with LLM-as-a-judge. We propose new metrics that capture both turn efficiency and intermediate progress of the agent complementing the user-aware setup. (3) Diagnose: We introduce an automated error analysis tool that analyzes the inconsistencies of the judge and agents, uncovering common errors, and providing actionable feedback for agent improvement. We show that our TED framework reveals new insights regarding agent performance across models and user expertise levels. We also demonstrate potential gains in agent performance with peaks of 8-10% on our proposed metrics after incorporating the identified error remedies into the agent's design.
OCR or Not? Rethinking Document Information Extraction in the MLLMs Era with Real-World Large-Scale Datasets
Mar 03, 2026Multimodal Large Language Models (MLLMs) enhance the potential of natural language processing. However, their actual impact on document information extraction remains unclear. In particular, it is unclear whether an MLLM-only pipeline--while simpler--can truly match the performance of traditional OCR+MLLM setups. In this paper, we conduct a large-scale benchmarking study that evaluates various out-of-the-box MLLMs on business-document information extraction. To examine and explore failure modes, we propose an automated hierarchical error analysis framework that leverages large language models (LLMs) to diagnose error patterns systematically. Our findings suggest that OCR may not be necessary for powerful MLLMs, as image-only input can achieve comparable performance to OCR-enhanced approaches. Moreover, we demonstrate that carefully designed schema, exemplars, and instructions can further enhance MLLMs performance. We hope this work can offer practical guidance and valuable insight for advancing document information extraction.
An Interactive Multi-Task Learning Network for End-to-End Aspect-Based Sentiment Analysis
Jun 17, 2019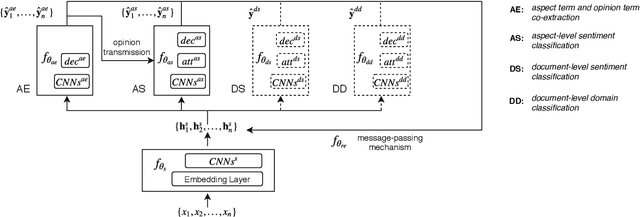

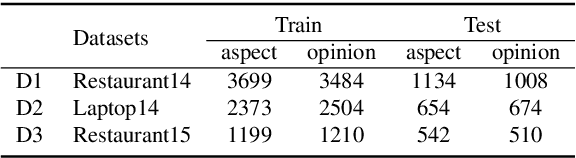
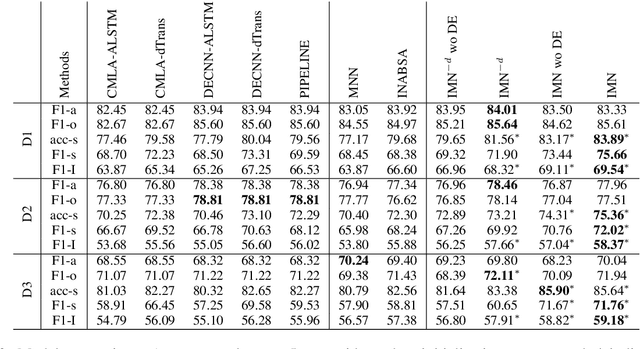
Aspect-based sentiment analysis produces a list of aspect terms and their corresponding sentiments for a natural language sentence. This task is usually done in a pipeline manner, with aspect term extraction performed first, followed by sentiment predictions toward the extracted aspect terms. While easier to develop, such an approach does not fully exploit joint information from the two subtasks and does not use all available sources of training information that might be helpful, such as document-level labeled sentiment corpus. In this paper, we propose an interactive multi-task learning network (IMN) which is able to jointly learn multiple related tasks simultaneously at both the token level as well as the document level. Unlike conventional multi-task learning methods that rely on learning common features for the different tasks, IMN introduces a message passing architecture where information is iteratively passed to different tasks through a shared set of latent variables. Experimental results demonstrate superior performance of the proposed method against multiple baselines on three benchmark datasets.
Adaptive Semi-supervised Learning for Cross-domain Sentiment Classification
Sep 03, 2018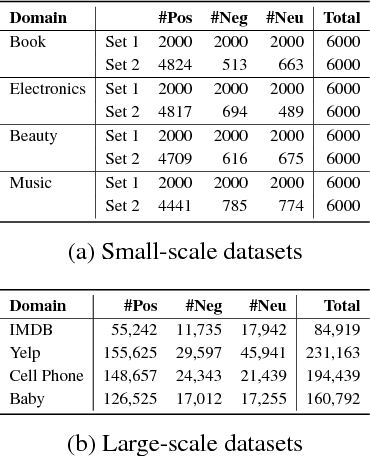
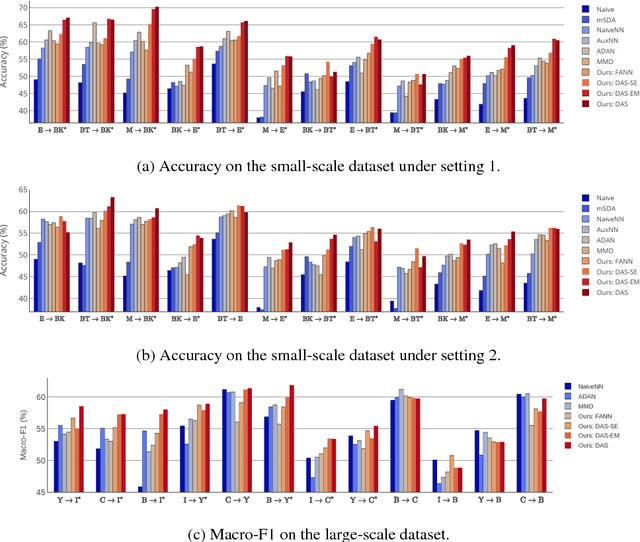
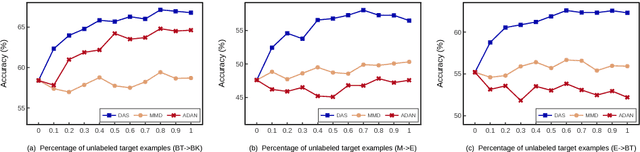
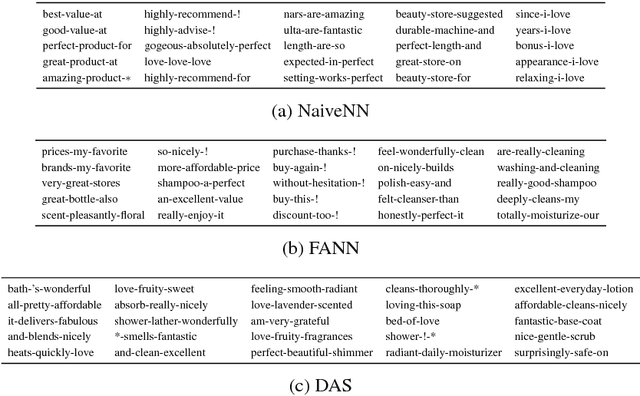
We consider the cross-domain sentiment classification problem, where a sentiment classifier is to be learned from a source domain and to be generalized to a target domain. Our approach explicitly minimizes the distance between the source and the target instances in an embedded feature space. With the difference between source and target minimized, we then exploit additional information from the target domain by consolidating the idea of semi-supervised learning, for which, we jointly employ two regularizations -- entropy minimization and self-ensemble bootstrapping -- to incorporate the unlabeled target data for classifier refinement. Our experimental results demonstrate that the proposed approach can better leverage unlabeled data from the target domain and achieve substantial improvements over baseline methods in various experimental settings.
Exploiting Document Knowledge for Aspect-level Sentiment Classification
Jun 12, 2018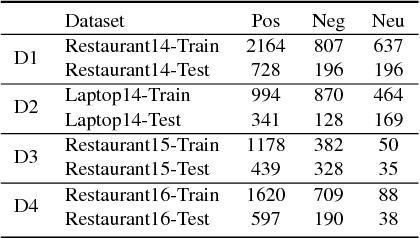
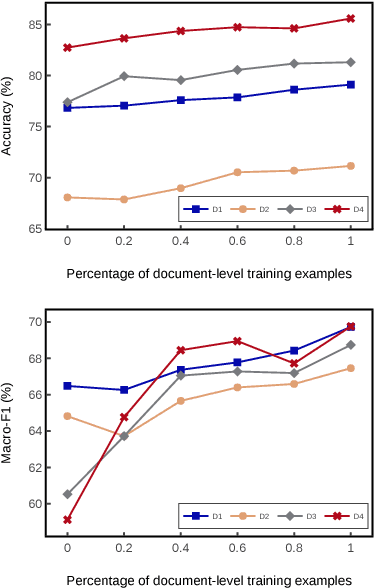
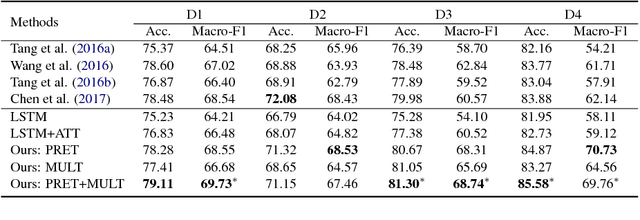
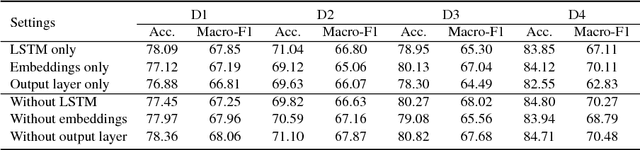
Attention-based long short-term memory (LSTM) networks have proven to be useful in aspect-level sentiment classification. However, due to the difficulties in annotating aspect-level data, existing public datasets for this task are all relatively small, which largely limits the effectiveness of those neural models. In this paper, we explore two approaches that transfer knowledge from document- level data, which is much less expensive to obtain, to improve the performance of aspect-level sentiment classification. We demonstrate the effectiveness of our approaches on 4 public datasets from SemEval 2014, 2015, and 2016, and we show that attention-based LSTM benefits from document-level knowledge in multiple ways.
Multi-task memory networks for category-specific aspect and opinion terms co-extraction
Jun 05, 2017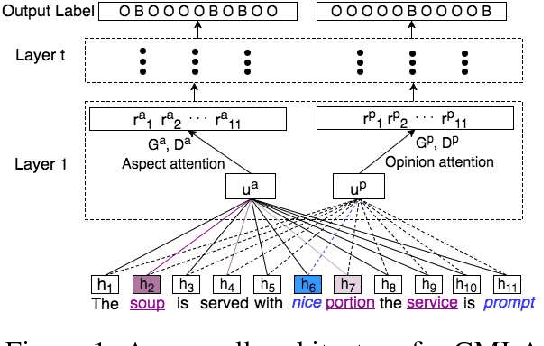
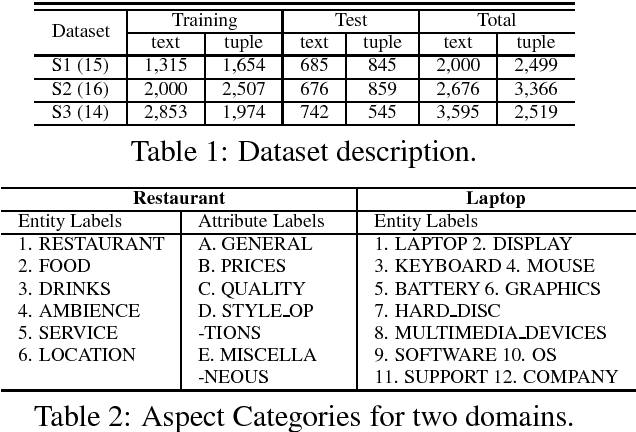
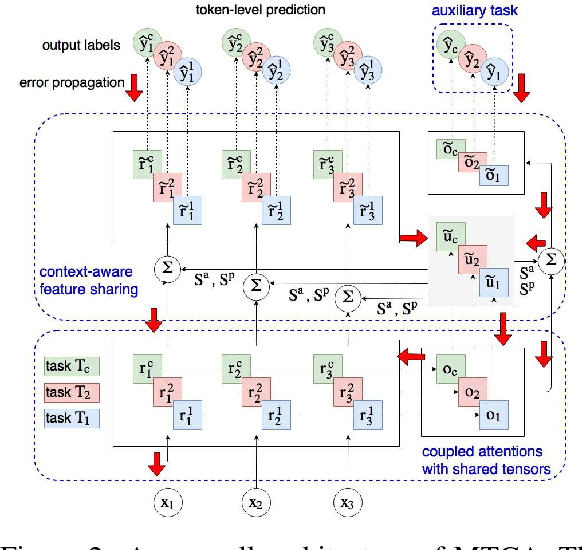
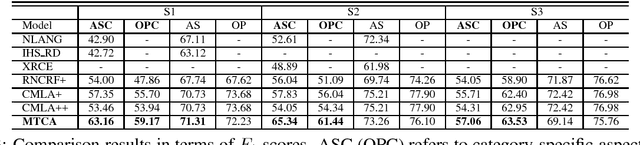
In aspect-based sentiment analysis, most existing methods either focus on aspect/opinion terms extraction or aspect terms categorization. However, each task by itself only provides partial information to end users. To generate more detailed and structured opinion analysis, we propose a finer-grained problem, which we call category-specific aspect and opinion terms extraction. This problem involves the identification of aspect and opinion terms within each sentence, as well as the categorization of the identified terms. To this end, we propose an end-to-end multi-task attention model, where each task corresponds to aspect/opinion terms extraction for a specific category. Our model benefits from exploring the commonalities and relationships among different tasks to address the data sparsity issue. We demonstrate its state-of-the-art performance on three benchmark datasets.
Character-Based Text Classification using Top Down Semantic Model for Sentence Representation
May 29, 2017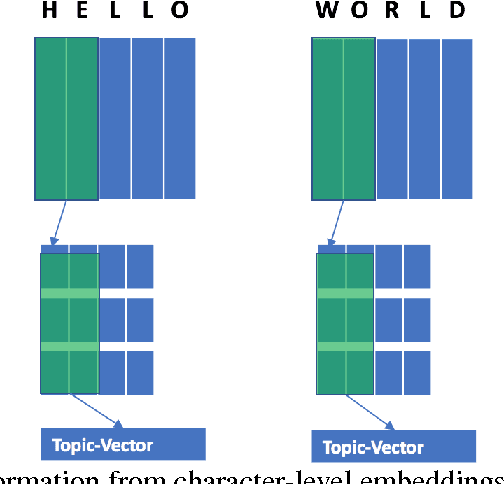
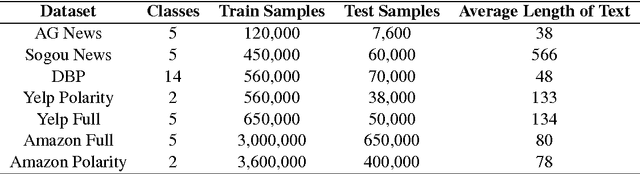
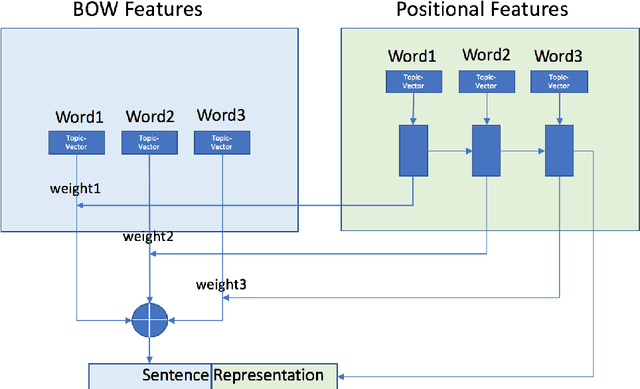

Despite the success of deep learning on many fronts especially image and speech, its application in text classification often is still not as good as a simple linear SVM on n-gram TF-IDF representation especially for smaller datasets. Deep learning tends to emphasize on sentence level semantics when learning a representation with models like recurrent neural network or recursive neural network, however from the success of TF-IDF representation, it seems a bag-of-words type of representation has its strength. Taking advantage of both representions, we present a model known as TDSM (Top Down Semantic Model) for extracting a sentence representation that considers both the word-level semantics by linearly combining the words with attention weights and the sentence-level semantics with BiLSTM and use it on text classification. We apply the model on characters and our results show that our model is better than all the other character-based and word-based convolutional neural network models by \cite{zhang15} across seven different datasets with only 1\% of their parameters. We also demonstrate that this model beats traditional linear models on TF-IDF vectors on small and polished datasets like news article in which typically deep learning models surrender.
Recursive Neural Conditional Random Fields for Aspect-based Sentiment Analysis
Sep 19, 2016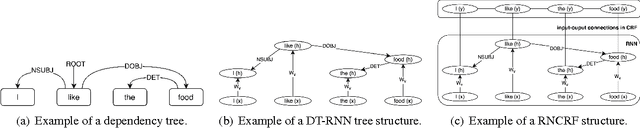
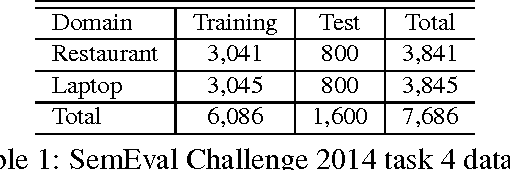
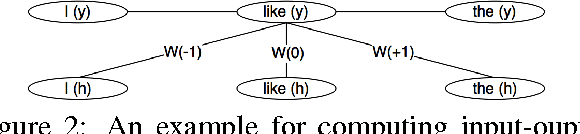
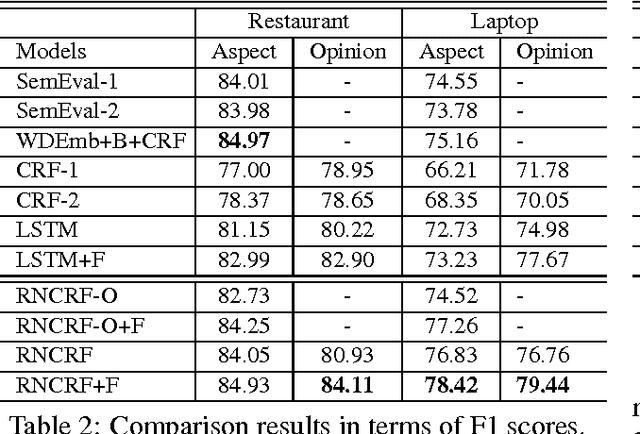
In aspect-based sentiment analysis, extracting aspect terms along with the opinions being expressed from user-generated content is one of the most important subtasks. Previous studies have shown that exploiting connections between aspect and opinion terms is promising for this task. In this paper, we propose a novel joint model that integrates recursive neural networks and conditional random fields into a unified framework for explicit aspect and opinion terms co-extraction. The proposed model learns high-level discriminative features and double propagate information between aspect and opinion terms, simultaneously. Moreover, it is flexible to incorporate hand-crafted features into the proposed model to further boost its information extraction performance. Experimental results on the SemEval Challenge 2014 dataset show the superiority of our proposed model over several baseline methods as well as the winning systems of the challenge.