Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Denoising Auto-encoder for Statistical Speech Synthesis
Paper and Code
Jun 17, 2015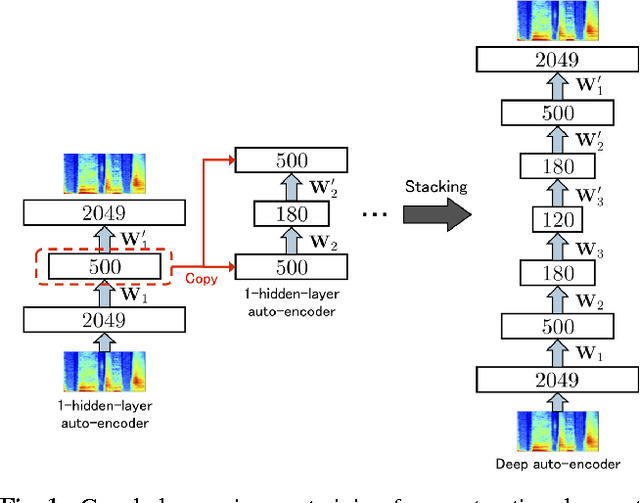
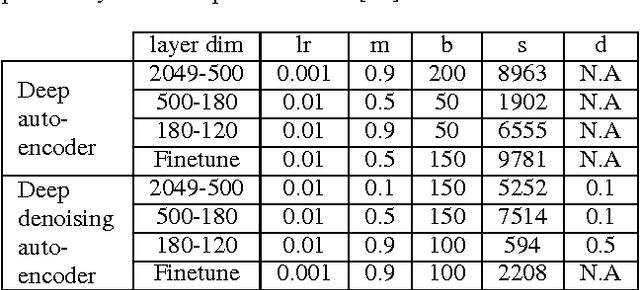
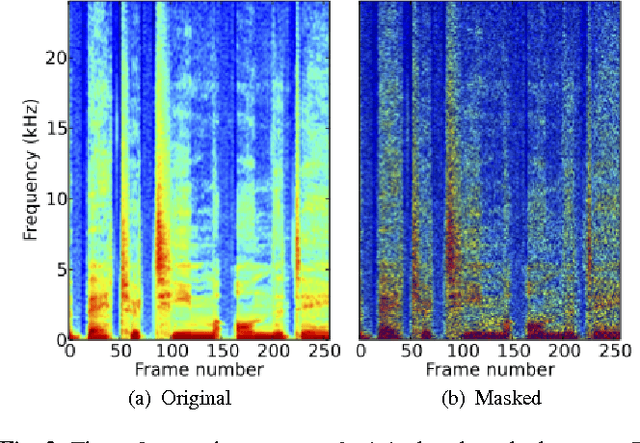
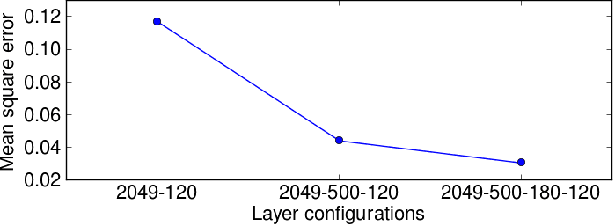
This paper proposes a deep denoising auto-encoder technique to extract better acoustic features for speech synthesis. The technique allows us to automatically extract low-dimensional features from high dimensional spectral features in a non-linear, data-driven, unsupervised way. We compared the new stochastic feature extractor with conventional mel-cepstral analysis in analysis-by-synthesis and text-to-speech experiments. Our results confirm that the proposed method increases the quality of synthetic speech in both experiments.
View paper on