 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LIME Robustness with Smarter Locality Sampling
Jun 22, 2020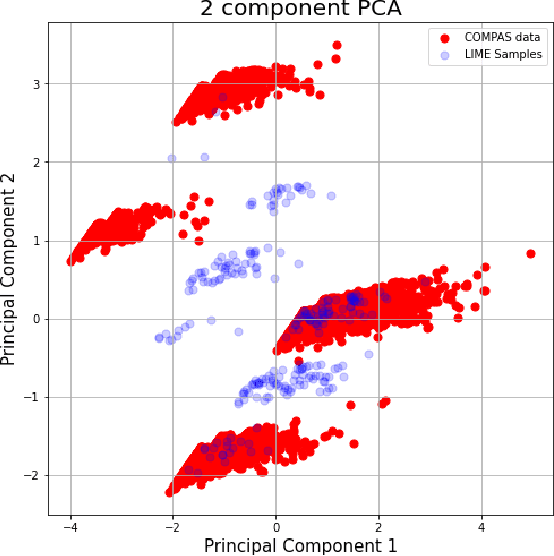
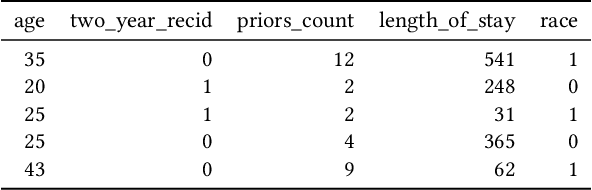

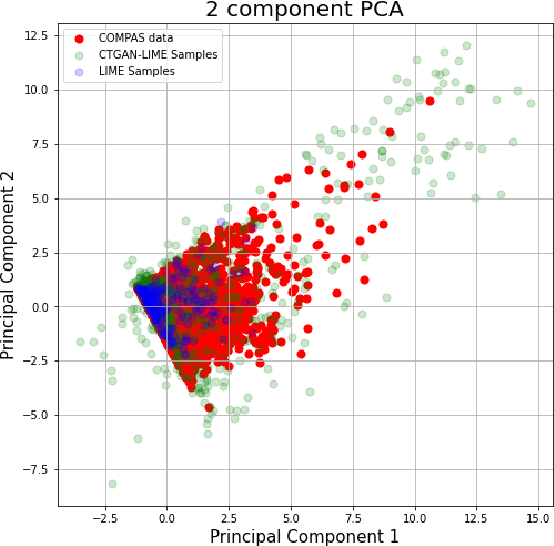
Explainability algorithms such as LIME have enabled machine learning systems to adopt transparency and fairness, which are important qualities in commercial use cases. However, recent work has shown that LIME's naive sampling strategy can be exploited by an adversary to conceal biased, harmful behavior. We propose to make LIME more robust by training a generative adversarial network to sample more realistic synthetic data which the explainer uses to generate explanations. Our experiments demonstrate that our proposed method demonstrates an increase in accuracy across three real-world datasets in detecting biased, adversarial behavior compared to vanilla LIME. This is achieved while maintaining comparable explanation quality, with up to 99.94\% in top-1 accuracy in some cases.
Explaining Away Attacks Against Neural Networks
Mar 06, 2020


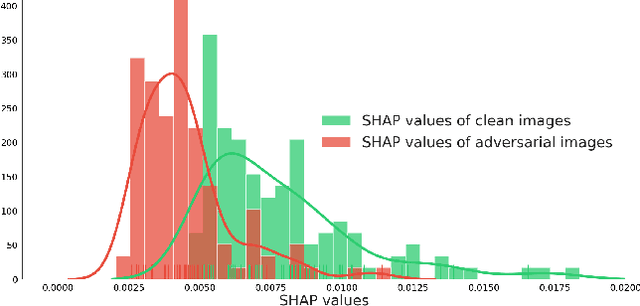
We investigate the problem of identifying adversarial attacks on image-based neural networks. We present intriguing experimental results showing significant discrepancies between the explanations generated for the predictions of a model on clean and adversarial data. Utilizing this intuition, we propose a framework which can identify whether a given input is adversarial based on the explanations given by the model. Code for our experiments can be found here: https://github.com/seansaito/Explaining-Away-Attacks-Against-Neural-Networks.
Effects of Loss Functions And Target Representations on Adversarial Robustness
Dec 01, 2018
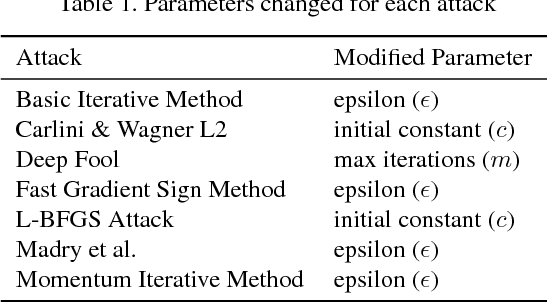
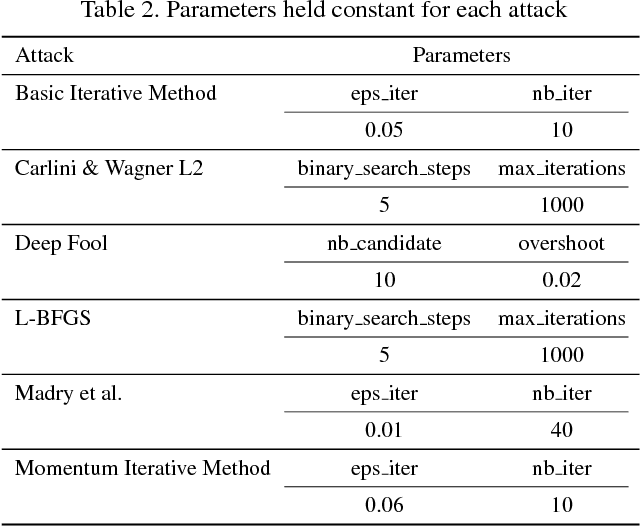

Understanding and evaluating the robustness of neural networks against adversarial attacks is a subject of growing interest. Attacks proposed in the literature usually work with models that are trained to minimize cross-entropy loss and have softmax activations. In this work, we present interesting experimental results that suggest the importance of considering other loss functions and target representations. Specifically, (1) training on mean-squared error and (2) representing targets as codewords generated from a random codebook show a marked increase in robustness against targeted and untargeted attacks under white-box and black-box settings. Our results show an increase in accuracy against untargeted attacks of up to 98.7\% and a decrease of targeted attack success rates of up to 99.8\%. For our experiments, we use the DenseNet architecture trained on three datasets (CIFAR-10, MNIST, and Fashion-MNIST).
HiNet: Hierarchical Classification with Neural Network
Jan 12, 2018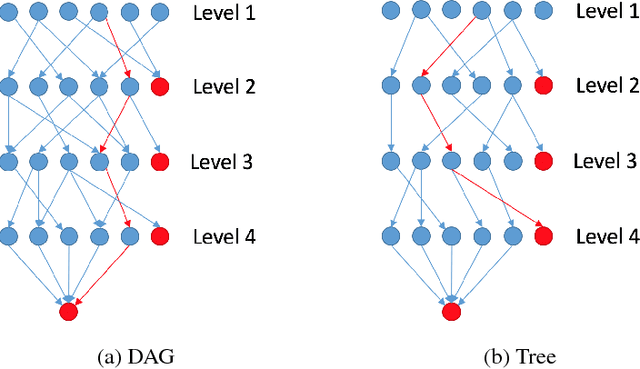

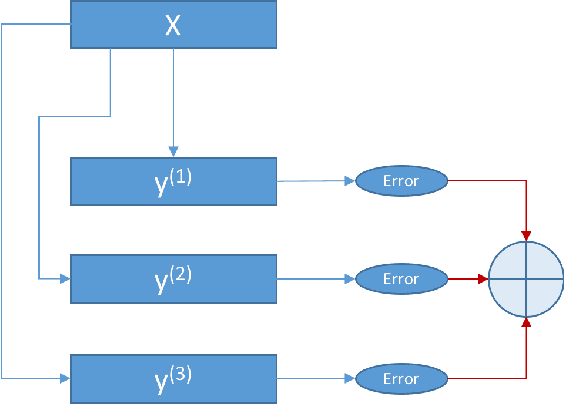
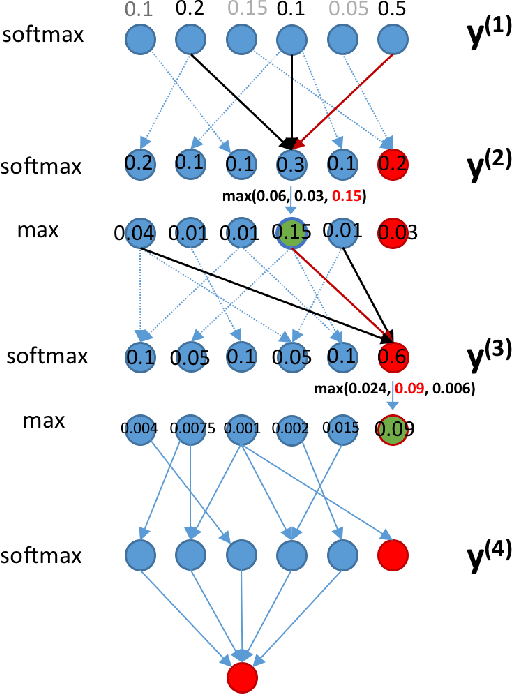
Traditionally, classifying large hierarchical labels with more than 10000 distinct traces can only be achieved with flatten labels. Although flatten labels is feasible, it misses the hierarchical information in the labels. Hierarchical models like HSVM by \cite{vural2004hierarchical} becomes impossible to train because of the sheer number of SVMs in the whole architecture. We developed a hierarchical architecture based on neural networks that is simple to train. Also, we derived an inference algorithm that can efficiently infer the MAP (maximum a posteriori) trace guaranteed by our theorems. Furthermore, the complexity of the model is only $O(n^2)$ compared to $O(n^h)$ in a flatten model, where $h$ is the height of the hierarchy.