 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LIME Robustness with Smarter Locality Sampling
Jun 22, 2020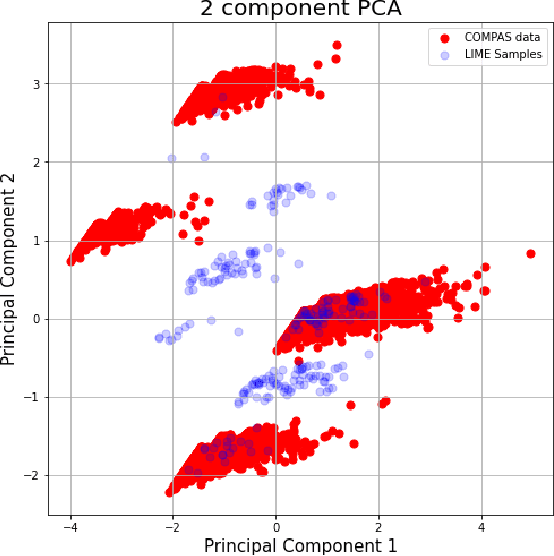
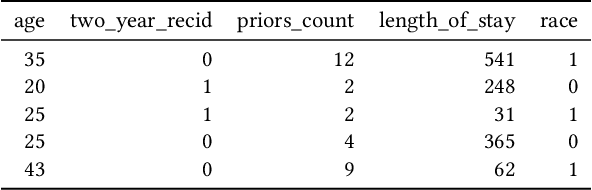

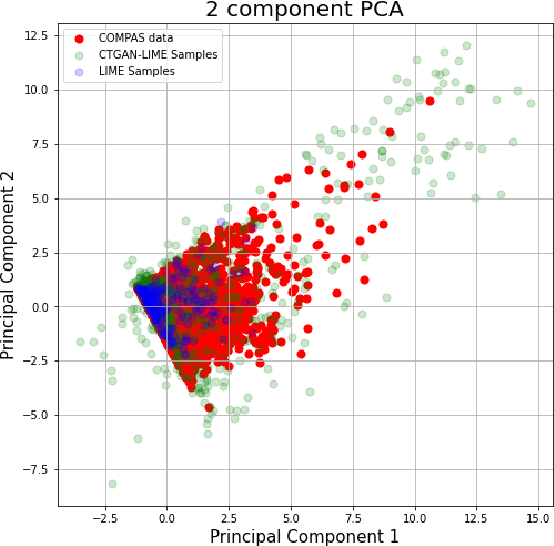
Explainability algorithms such as LIME have enabled machine learning systems to adopt transparency and fairness, which are important qualities in commercial use cases. However, recent work has shown that LIME's naive sampling strategy can be exploited by an adversary to conceal biased, harmful behavior. We propose to make LIME more robust by training a generative adversarial network to sample more realistic synthetic data which the explainer uses to generate explanations. Our experiments demonstrate that our proposed method demonstrates an increase in accuracy across three real-world datasets in detecting biased, adversarial behavior compared to vanilla LIME. This is achieved while maintaining comparable explanation quality, with up to 99.94\% in top-1 accuracy in some cases.