 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint Representation Using Continuous and Discrete Features for Cardiovascular Diseases Risk Prediction on Chest CT Scans
Oct 24, 2024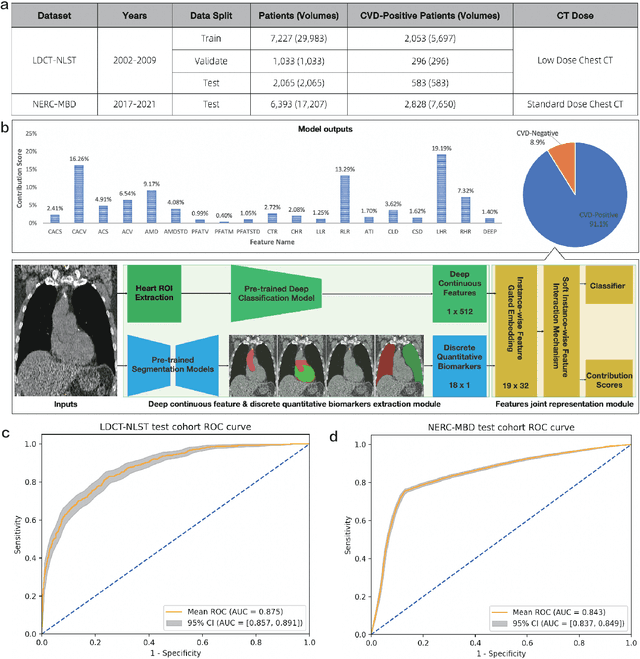
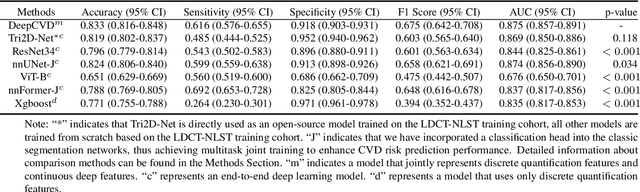


Cardiovascular diseases (CVD) remain a leading health concern and contribute significantly to global mortality rates. While clinical advancements have led to a decline in CVD mortality, accurately identifying individuals who could benefit from preventive interventions remains an unsolved challenge in preventive cardiology. Current CVD risk prediction models, recommended by guidelines, are based on limited traditional risk factors or use CT imaging to acquire quantitative biomarkers, and still have limitations in predictive accuracy and applicability. On the other hand, end-to-end trained CVD risk prediction methods leveraging deep learning on CT images often fail to provide transparent and explainable decision grounds for assisting physicians. In this work, we proposed a novel joint representation that integrates discrete quantitative biomarkers and continuous deep features extracted from chest CT scans. Our approach initiated with a deep CVD risk classification model by capturing comprehensive continuous deep learning features while jointly obtaining currently clinical-established quantitative biomarkers via segmentation models. In the feature joint representation stage, we use an instance-wise feature-gated mechanism to align the continuous and discrete features, followed by a soft instance-wise feature interaction mechanism fostering independent and effective feature interaction for the final CVD risk prediction. Our method substantially improves CVD risk predictive performance and offers individual contribution analysis of each biomarker, which is important in assisting physicians' decision-making processes. We validated our method on a public chest low-dose CT dataset and a private external chest standard-dose CT patient cohort of 17,207 CT volumes from 6,393 unique subjects, and demonstrated superior predictive performance, achieving AUCs of 0.875 and 0.843, respectively.
SGDM: Static-Guided Dynamic Module Make Stronger Visual Models
Mar 27, 2024



The spatial attention mechanism has been widely used to improve object detection performance. However, its operation is currently limited to static convolutions lacking content-adaptive features. This paper innovatively approaches from the perspective of dynamic convolution. We propose Razor Dynamic Convolution (RDConv) to address thetwo flaws in dynamic weight convolution, making it hard to implement in spatial mechanism: 1) it is computation-heavy; 2) when generating weights, spatial information is disregarded. Firstly, by using Razor Operation to generate certain features, we vastly reduce the parameters of the entire dynamic convolution operation. Secondly, we added a spatial branch inside RDConv to generate convolutional kernel parameters with richer spatial information. Embedding dynamic convolution will also bring the problem of sensitivity to high-frequency noise. We propose the Static-Guided Dynamic Module (SGDM) to address this limitation. By using SGDM, we utilize a set of asymmetric static convolution kernel parameters to guide the construction of dynamic convolution. We introduce the mechanism of shared weights in static convolution to solve the problem of dynamic convolution being sensitive to high-frequency noise. Extensive experiments illustrate that multiple different object detection backbones equipped with SGDM achieve a highly competitive boost in performance(e.g., +4% mAP with YOLOv5n on VOC and +1.7% mAP with YOLOv8n on COCO) with negligible parameter increase(i.e., +0.33M on YOLOv5n and +0.19M on YOLOv8n).
Adversarial Data Encryption
Feb 11, 2020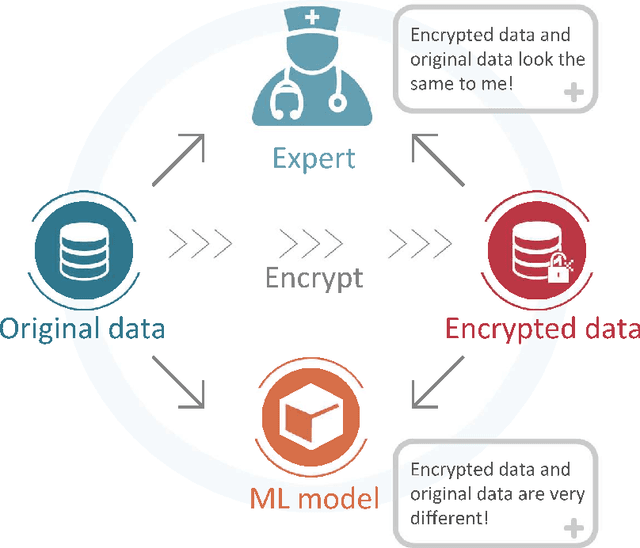

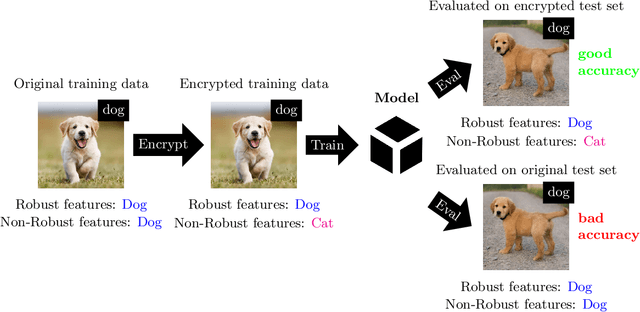

In the big data era, many organizations face the dilemma of data sharing. Regular data sharing is often necessary for human-centered discussion and communication, especially in medical scenarios. However, unprotected data sharing may also lead to data leakage. Inspired by adversarial attack, we propose a method for data encryption, so that for human beings the encrypted data look identical to the original version, but for machine learning methods they are misleading. To show the effectiveness of our method, we collaborate with the Beijing Tiantan Hospital, which has a world leading neurological center. We invite $3$ doctors to manually inspect our encryption method based on real world medical images. The results show that the encrypted images can be used for diagnosis by the doctors, but not by machine learning methods.