 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
Feb 13, 2026We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Adversarial Data Encryption
Feb 11, 2020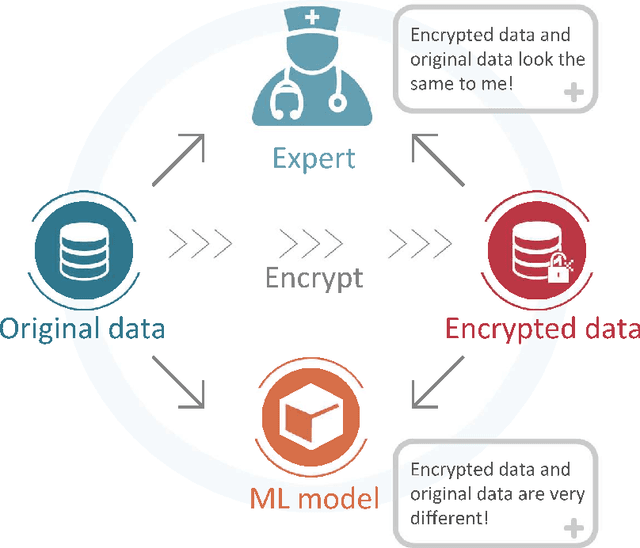

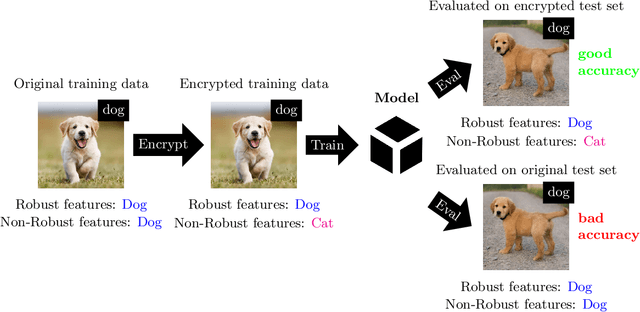

In the big data era, many organizations face the dilemma of data sharing. Regular data sharing is often necessary for human-centered discussion and communication, especially in medical scenarios. However, unprotected data sharing may also lead to data leakage. Inspired by adversarial attack, we propose a method for data encryption, so that for human beings the encrypted data look identical to the original version, but for machine learning methods they are misleading. To show the effectiveness of our method, we collaborate with the Beijing Tiantan Hospital, which has a world leading neurological center. We invite $3$ doctors to manually inspect our encryption method based on real world medical images. The results show that the encrypted images can be used for diagnosis by the doctors, but not by machine learning methods.