 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyTTS: LLM-based Spoken Chatbot With Voice Cloning
Jul 03, 2025JoyTTS is an end-to-end spoken chatbot that combines large language models (LLM) with text-to-speech (TTS) technology, featuring voice cloning capabilities. This project is built upon the open-source MiniCPM-o and CosyVoice2 models and trained on 2000 hours of conversational data. We have also provided the complete training code to facilitate further development and optimization by the community. On the testing machine seed-tts-zh, it achieves a SS (speaker similarity) score of 0.73 and a WER (Word Error Rate) of 5.09. The code and models, along with training and inference scripts, are available at https://github.com/jdh-algo/JoyTTS.git.
ARShoe: Real-Time Augmented Reality Shoe Try-on System on Smartphones
Aug 24, 2021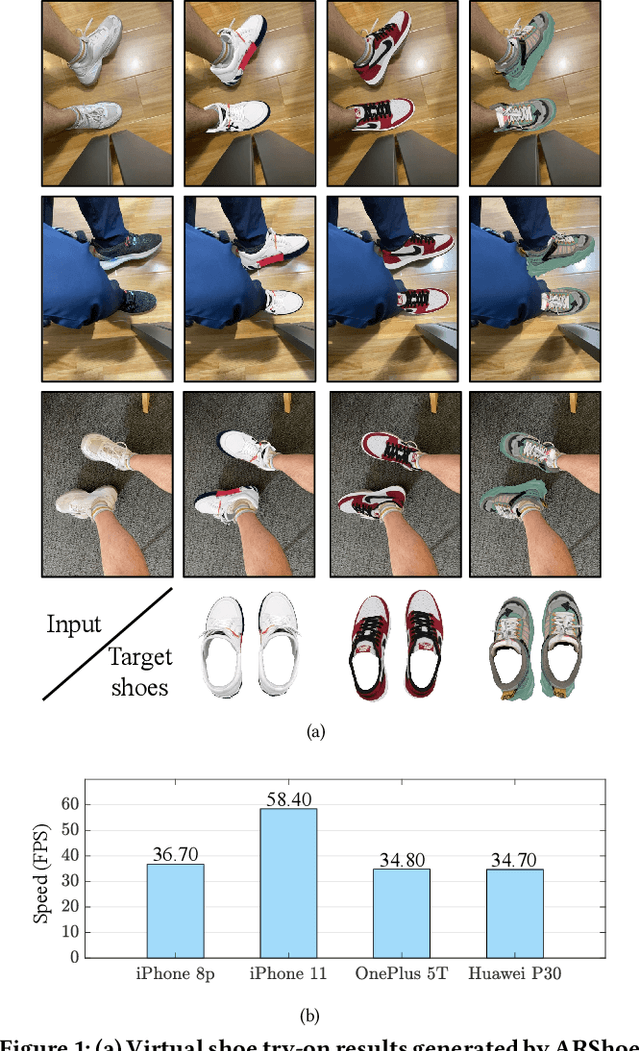
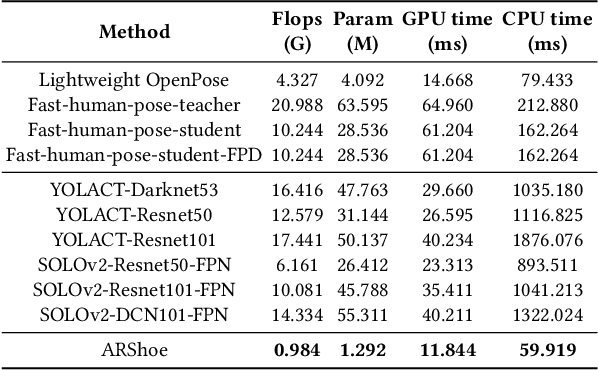
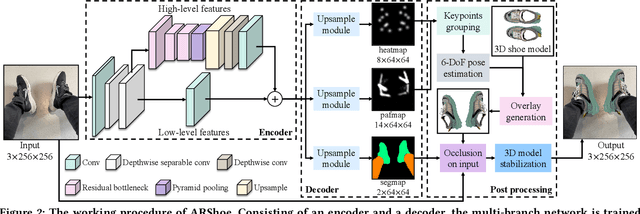
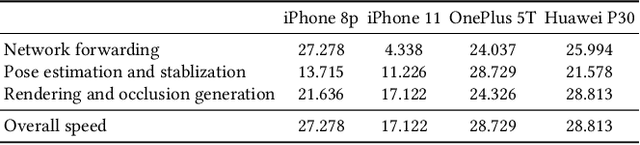
Virtual try-on technology enables users to try various fashion items using augmented reality and provides a convenient online shopping experience. However, most previous works focus on the virtual try-on for clothes while neglecting that for shoes, which is also a promising task. To this concern, this work proposes a real-time augmented reality virtual shoe try-on system for smartphones, namely ARShoe. Specifically, ARShoe adopts a novel multi-branch network to realize pose estimation and segmentation simultaneously. A solution to generate realistic 3D shoe model occlusion during the try-on process is presented. To achieve a smooth and stable try-on effect, this work further develop a novel stabilization method. Moreover, for training and evaluation, we construct the very first large-scale foot benchmark with multiple virtual shoe try-on task-related labels annotated. Exhaustive experiments on our newly constructed benchmark demonstrate the satisfying performance of ARShoe. Practical tests on common smartphones validate the real-time performance and stabilization of the proposed approach.
Real-Time Monocular Human Depth Estimation and Segmentation on Embedded Systems
Aug 24, 2021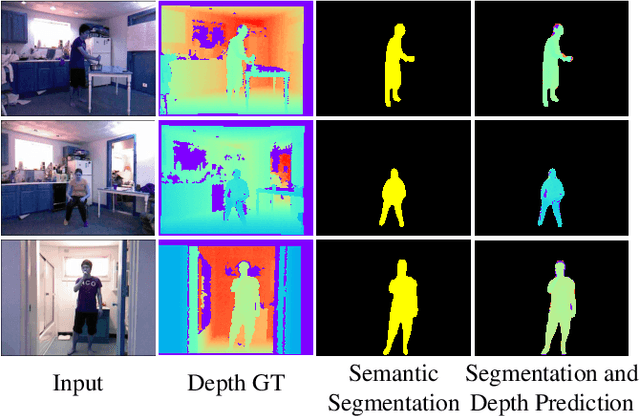
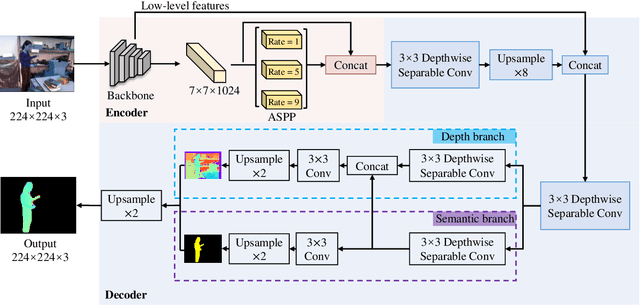
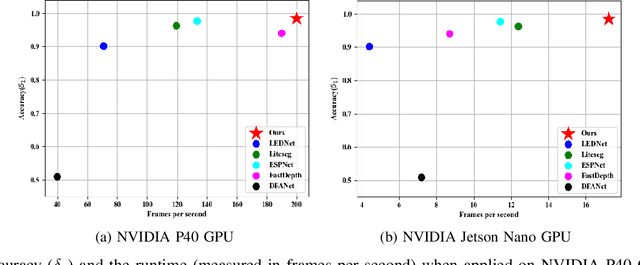
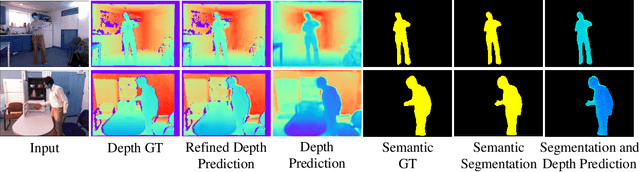
Estimating a scene's depth to achieve collision avoidance against moving pedestrians is a crucial and fundamental problem in the robotic field. This paper proposes a novel, low complexity network architecture for fast and accurate human depth estimation and segmentation in indoor environments, aiming to applications for resource-constrained platforms (including battery-powered aerial, micro-aerial, and ground vehicles) with a monocular camera being the primary perception module. Following the encoder-decoder structure, the proposed framework consists of two branches, one for depth prediction and another for semantic segmentation. Moreover, network structure optimization is employed to improve its forward inference speed. Exhaustive experiments on three self-generated datasets prove our pipeline's capability to execute in real-time, achieving higher frame rates than contemporary state-of-the-art frameworks (114.6 frames per second on an NVIDIA Jetson Nano GPU with TensorRT) while maintaining comparable accuracy.
Fast and Incremental Loop Closure Detection Using Proximity Graphs
Nov 25, 2019
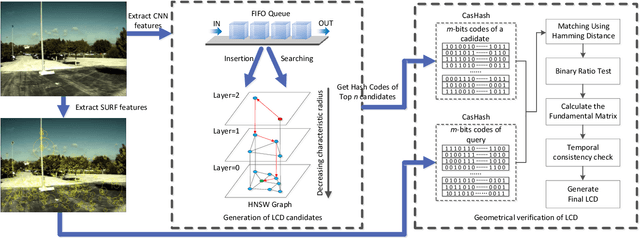
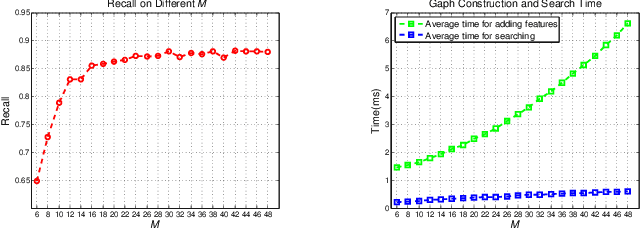
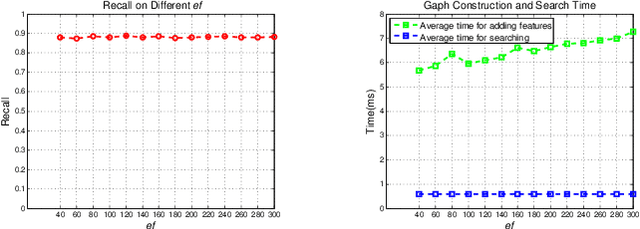
Visual loop closure detection, which can be considered as an image retrieval task, is an important problem in SLAM (Simultaneous Localization and Mapping) systems. The frequently used bag-of-words (BoW) models can achieve high precision and moderate recall. However, the requirement for lower time costs and fewer memory costs for mobile robot applications is not well satisfied. In this paper, we propose a novel loop closure detection framework titled `FILD' (Fast and Incremental Loop closure Detection), which focuses on an on-line and incremental graph vocabulary construction for fast loop closure detection. The global and local features of frames are extracted using the Convolutional Neural Networks (CNN) and SURF on the GPU, which guarantee extremely fast extraction speeds. The graph vocabulary construction is based on one type of proximity graph, named Hierarchical Navigable Small World (HNSW) graphs, which is modified to adapt to this specific application. In addition, this process is coupled with a novel strategy for real-time geometrical verification, which only keeps binary hash codes and significantly saves on memory usage. Extensive experiments on several publicly available datasets show that the proposed approach can achieve fairly good recall at 100\% precision compared to other state-of-the-art methods. The source code can be downloaded at https://github.com/AnshanTJU/FILD for further studies.