 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Image Aesthetics with Dual-Conditioned Diffusion Models Guided by Multimodal Perception
Mar 12, 2026Image aesthetic enhancement aims to perceive aesthetic deficiencies in images and perform corresponding editing operations, which is highly challenging and requires the model to possess creativity and aesthetic perception capabilities. Although recent advancements in image editing models have significantly enhanced their controllability and flexibility, they struggle with enhancing image aesthetic. The primary challenges are twofold: first, following editing instructions with aesthetic perception is difficult, and second, there is a scarcity of "perfectly-paired" images that have consistent content but distinct aesthetic qualities. In this paper, we propose Dual-supervised Image Aesthetic Enhancement (DIAE), a diffusion-based generative model with multimodal aesthetic perception. First, DIAE incorporates Multimodal Aesthetic Perception (MAP) to convert the ambiguous aesthetic instruction into explicit guidance by (i) employing detailed, standardized aesthetic instructions across multiple aesthetic attributes, and (ii) utilizing multimodal control signals derived from text-image pairs that maintain consistency within the same aesthetic attribute. Second, to mitigate the lack of "perfectly-paired" images, we collect "imperfectly-paired" dataset called IIAEData, consisting of images with varying aesthetic qualities while sharing identical semantics. To better leverage the weak matching characteristics of IIAEData during training, a dual-branch supervision framework is also introduced for weakly supervised image aesthetic enhancement. Experimental results demonstrate that DIAE outperforms the baselines and obtains superior image aesthetic scores and image content consistency scores.
CircuitSense: A Hierarchical Circuit System Benchmark Bridging Visual Comprehension and Symbolic Reasoning in Engineering Design Process
Sep 26, 2025Engineering design operates through hierarchical abstraction from system specifications to component implementations, requiring visual understanding coupled with mathematical reasoning at each level. While Multi-modal Large Language Models (MLLMs) excel at natural image tasks, their ability to extract mathematical models from technical diagrams remains unexplored. We present \textbf{CircuitSense}, a comprehensive benchmark evaluating circuit understanding across this hierarchy through 8,006+ problems spanning component-level schematics to system-level block diagrams. Our benchmark uniquely examines the complete engineering workflow: Perception, Analysis, and Design, with a particular emphasis on the critical but underexplored capability of deriving symbolic equations from visual inputs. We introduce a hierarchical synthetic generation pipeline consisting of a grid-based schematic generator and a block diagram generator with auto-derived symbolic equation labels. Comprehensive evaluation of six state-of-the-art MLLMs, including both closed-source and open-source models, reveals fundamental limitations in visual-to-mathematical reasoning. Closed-source models achieve over 85\% accuracy on perception tasks involving component recognition and topology identification, yet their performance on symbolic derivation and analytical reasoning falls below 19\%, exposing a critical gap between visual parsing and symbolic reasoning. Models with stronger symbolic reasoning capabilities consistently achieve higher design task accuracy, confirming the fundamental role of mathematical understanding in circuit synthesis and establishing symbolic reasoning as the key metric for engineering competence.
Revealing Microscopic Objects in Fluorescence Live Imaging by Video-to-video Translation Based on A Spatial-temporal Generative Adversarial Network
Feb 22, 2025


In spite of being a valuable tool to simultaneously visualize multiple types of subcellular structures using spectrally distinct fluorescent labels, a standard fluoresce microscope is only able to identify a few microscopic objects; such a limit is largely imposed by the number of fluorescent labels available to the sample. In order to simultaneously visualize more objects, in this paper, we propose to use video-to-video translation that mimics the development process of microscopic objects. In essence, we use a microscopy video-to-video translation framework namely Spatial-temporal Generative Adversarial Network (STGAN) to reveal the spatial and temporal relationships between the microscopic objects, after which a microscopy video of one object can be translated to another object in a different domain. The experimental results confirm that the proposed STGAN is effective in microscopy video-to-video translation that mitigates the spectral conflicts caused by the limited fluorescent labels, allowing multiple microscopic objects be simultaneously visualized.
Detecting Wildfire Flame and Smoke through Edge Computing using Transfer Learning Enhanced Deep Learning Models
Jan 15, 2025

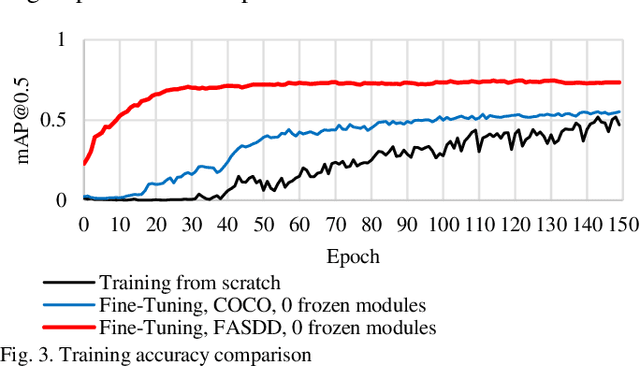

Autonomous unmanned aerial vehicles (UAVs) integrated with edge computing capabilities empower real-time data processing directly on the device, dramatically reducing latency in critical scenarios such as wildfire detection. This study underscores Transfer Learning's (TL) significance in boosting the performance of object detectors for identifying wildfire smoke and flames, especially when trained on limited datasets, and investigates the impact TL has on edge computing metrics. With the latter focusing how TL-enhanced You Only Look Once (YOLO) models perform in terms of inference time, power usage, and energy consumption when using edge computing devices. This study utilizes the Aerial Fire and Smoke Essential (AFSE) dataset as the target, with the Flame and Smoke Detection Dataset (FASDD) and the Microsoft Common Objects in Context (COCO) dataset serving as source datasets. We explore a two-stage cascaded TL method, utilizing D-Fire or FASDD as initial stage target datasets and AFSE as the subsequent stage. Through fine-tuning, TL significantly enhances detection precision, achieving up to 79.2% mean Average Precision (mAP@0.5), reduces training time, and increases model generalizability across the AFSE dataset. However, cascaded TL yielded no notable improvements and TL alone did not benefit the edge computing metrics evaluated. Lastly, this work found that YOLOv5n remains a powerful model when lacking hardware acceleration, finding that YOLOv5n can process images nearly twice as fast as its newer counterpart, YOLO11n. Overall, the results affirm TL's role in augmenting the accuracy of object detectors while also illustrating that additional enhancements are needed to improve edge computing performance.
Learning-to-solve unit commitment based on few-shot physics-guided spatial-temporal graph convolution network
May 02, 2024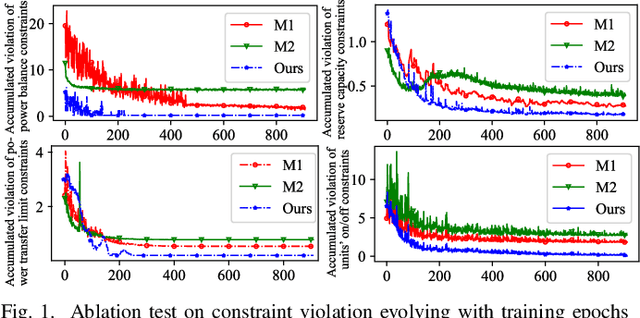
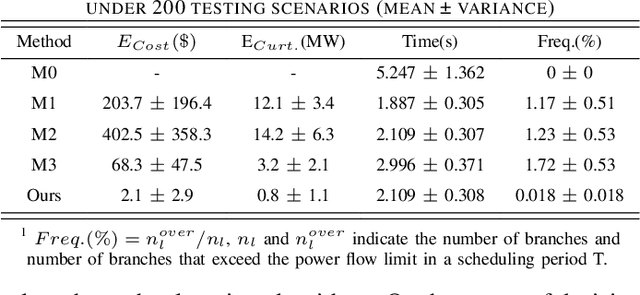
This letter proposes a few-shot physics-guided spatial temporal graph convolutional network (FPG-STGCN) to fast solve unit commitment (UC). Firstly, STGCN is tailored to parameterize UC. Then, few-shot physics-guided learning scheme is proposed. It exploits few typical UC solutions yielded via commercial optimizer to escape from local minimum, and leverages the augmented Lagrangian method for constraint satisfaction. To further enable both feasibility and continuous relaxation for integers in learning process, straight-through estimator for Tanh-Sign composition is proposed to fully differentiate the mixed integer solution space. Case study on the IEEE benchmark justifies that, our method bests mainstream learning ways on UC feasibility, and surpasses traditional solver on efficiency.
Detection of Problem Gambling with Less Features Using Machine Learning Methods
Mar 23, 2024Analytic features in gambling study are performed based on the amount of data monitoring on user daily actions. While performing the detection of problem gambling, existing datasets provide relatively rich analytic features for building machine learning based model. However, considering the complexity and cost of collecting the analytic features in real applications, conducting precise detection with less features will tremendously reduce the cost of data collection. In this study, we propose a deep neural networks PGN4 that performs well when using limited analytic features. Through the experiment on two datasets, we discover that PGN4 only experiences a mere performance drop when cutting 102 features to 5 features. Besides, we find the commonality within the top 5 features from two datasets.
Physics-Guided Graph Neural Networks for Real-time AC/DC Power Flow Analysis
Apr 29, 2023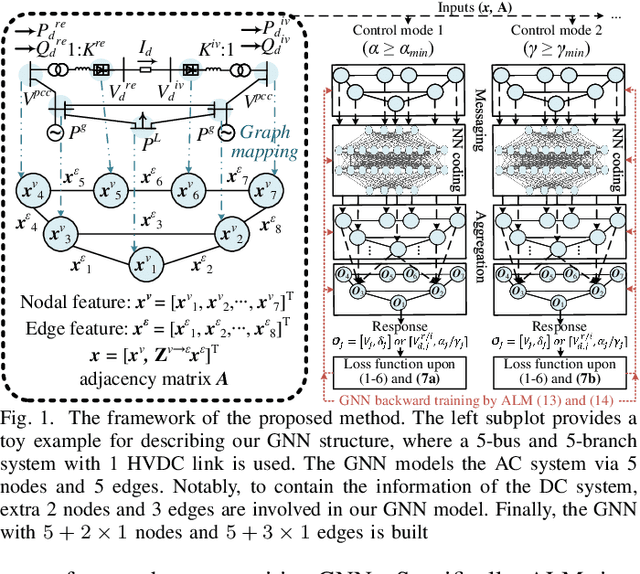
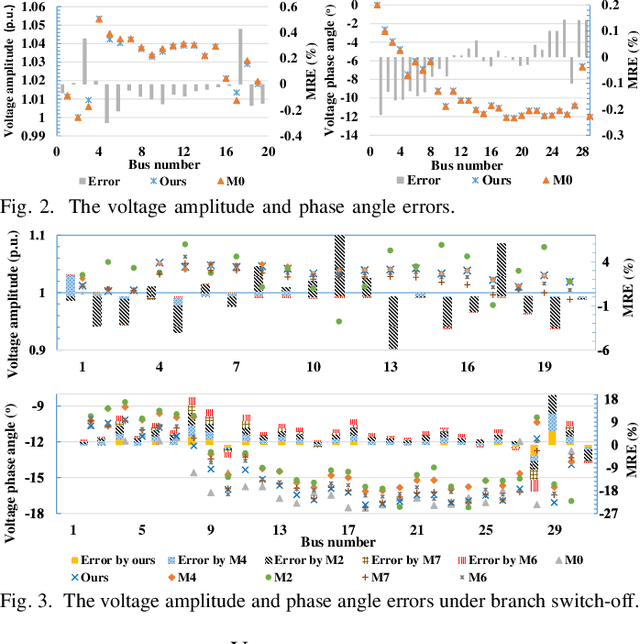
The increasing scale of alternating current and direct current (AC/DC) hybrid systems necessitates a faster power flow analysis tool than ever. This letter thus proposes a specific physics-guided graph neural network (PG-GNN). The tailored graph modelling of AC and DC grids is firstly advanced to enhance the topology adaptability of the PG-GNN. To eschew unreliable experience emulation from data, AC/DC physics are embedded in the PG-GNN using duality. Augmented Lagrangian method-based learning scheme is then presented to help the PG-GNN better learn nonconvex patterns in an unsupervised label-free manner. Multi-PG-GNN is finally conducted to master varied DC control modes. Case study shows that, relative to the other 7 data-driven rivals, only the proposed method matches the performance of the model-based benchmark, also beats it in computational efficiency beyond 10 times.
Towards Interpreting Vulnerability of Multi-Instance Learning via Customized and Universal Adversarial Perturbations
Nov 30, 2022



Multi-instance learning (MIL) is a great paradigm for dealing with complex data and has achieved impressive achievements in a number of fields, including image classification, video anomaly detection, and far more. Each data sample is referred to as a bag containing several unlabeled instances, and the supervised information is only provided at the bag-level. The safety of MIL learners is concerning, though, as we can greatly fool them by introducing a few adversarial perturbations. This can be fatal in some cases, such as when users are unable to access desired images and criminals are attempting to trick surveillance cameras. In this paper, we design two adversarial perturbations to interpret the vulnerability of MIL methods. The first method can efficiently generate the bag-specific perturbation (called customized) with the aim of outsiding it from its original classification region. The second method builds on the first one by investigating the image-agnostic perturbation (called universal) that aims to affect all bags in a given data set and obtains some generalizability. We conduct various experiments to verify the performance of these two perturbations, and the results show that both of them can effectively fool MIL learners. We additionally propose a simple strategy to lessen the effects of adversarial perturbations. Source codes are available at https://github.com/InkiInki/MI-UAP.
Fault-Aware Neural Code Rankers
Jun 04, 2022


Large language models (LLMs) have demonstrated an impressive ability to generate code for various programming tasks. In many instances, LLMs can generate a correct program for a task when given numerous trials. Consequently, a recent trend is to do large scale sampling of programs using a model and then filtering/ranking the programs based on the program execution on a small number of known unit tests to select one candidate solution. However, these approaches assume that the unit tests are given and assume the ability to safely execute the generated programs (which can do arbitrary dangerous operations such as file manipulations). Both of the above assumptions are impractical in real-world software development. In this paper, we propose fault-aware neural code rankers that can predict the correctness of a sampled program without executing it. The fault-aware rankers are trained to predict different kinds of execution information such as predicting the exact compile/runtime error type (e.g., an IndexError or a TypeError). We show that our fault-aware rankers can significantly increase the pass@1 accuracy of various code generation models (including Codex, GPT-Neo, GPT-J) on APPS, HumanEval and MBPP datasets.
Real-Time Monocular Human Depth Estimation and Segmentation on Embedded Systems
Aug 24, 2021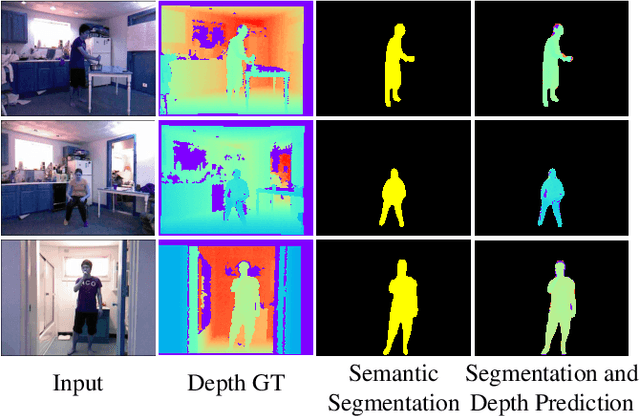
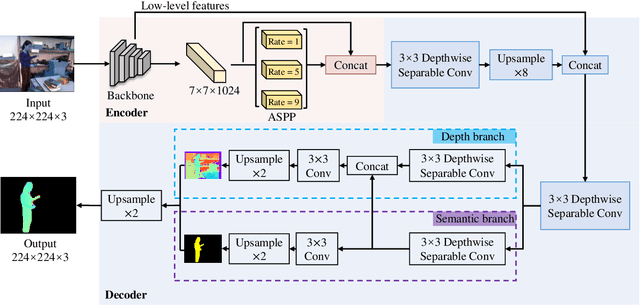
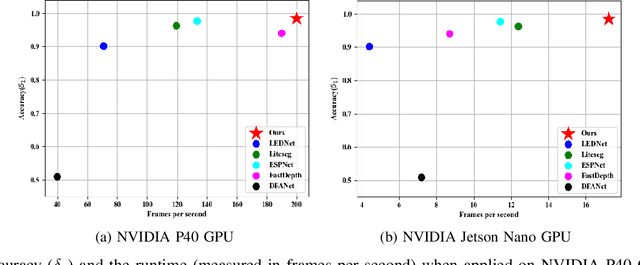
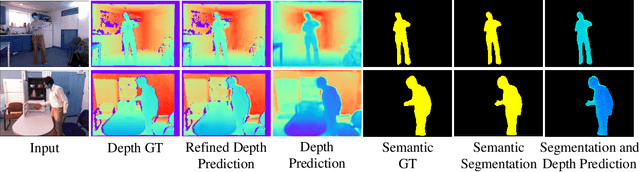
Estimating a scene's depth to achieve collision avoidance against moving pedestrians is a crucial and fundamental problem in the robotic field. This paper proposes a novel, low complexity network architecture for fast and accurate human depth estimation and segmentation in indoor environments, aiming to applications for resource-constrained platforms (including battery-powered aerial, micro-aerial, and ground vehicles) with a monocular camera being the primary perception module. Following the encoder-decoder structure, the proposed framework consists of two branches, one for depth prediction and another for semantic segmentation. Moreover, network structure optimization is employed to improve its forward inference speed. Exhaustive experiments on three self-generated datasets prove our pipeline's capability to execute in real-time, achieving higher frame rates than contemporary state-of-the-art frameworks (114.6 frames per second on an NVIDIA Jetson Nano GPU with TensorRT) while maintaining comparable accuracy.