 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Knowledge Fusion for Deep Multi-instance Learning
Apr 24, 2023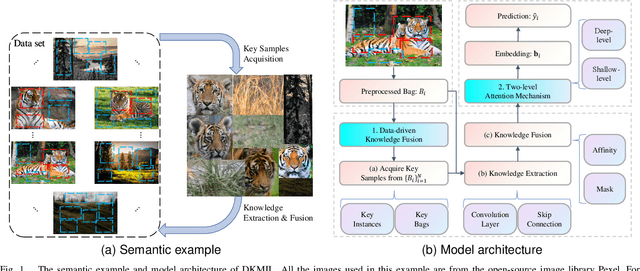
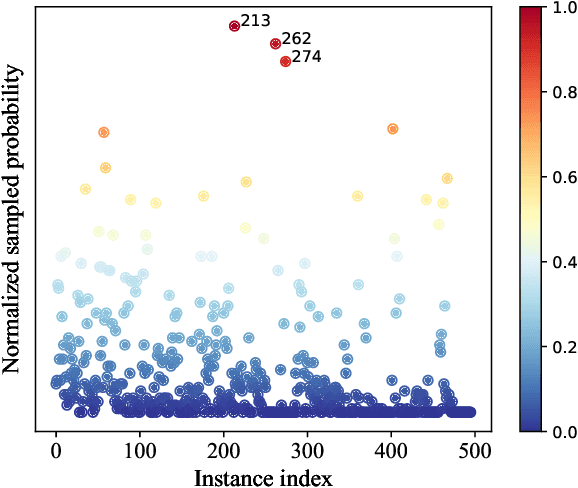
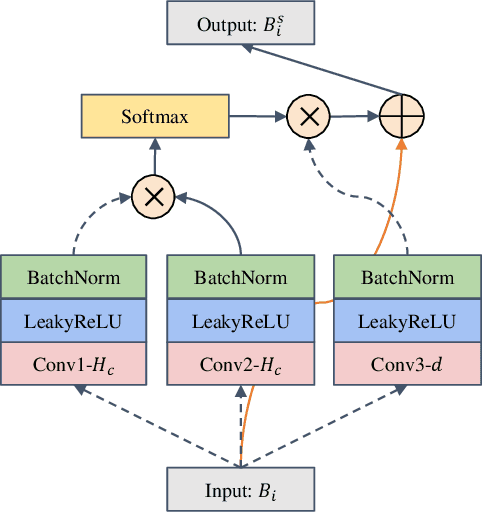
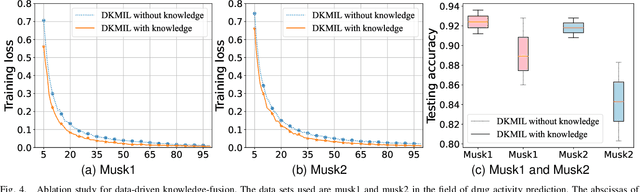
Multi-instance learning (MIL) is a widely-applied technique in practical applications that involve complex data structures. MIL can be broadly categorized into two types: traditional methods and those based on deep learning. These approaches have yielded significant results, especially with regards to their problem-solving strategies and experimental validation, providing valuable insights for researchers in the MIL field. However, a considerable amount of knowledge is often trapped within the algorithm, leading to subsequent MIL algorithms that solely rely on the model's data fitting to predict unlabeled samples. This results in a significant loss of knowledge and impedes the development of more intelligent models. In this paper, we propose a novel data-driven knowledge fusion for deep multi-instance learning (DKMIL) algorithm. DKMIL adopts a completely different idea from existing deep MIL methods by analyzing the decision-making of key samples in the data set (referred to as the data-driven) and using the knowledge fusion module designed to extract valuable information from these samples to assist the model's training. In other words, this module serves as a new interface between data and the model, providing strong scalability and enabling the use of prior knowledge from existing algorithms to enhance the learning ability of the model. Furthermore, to adapt the downstream modules of the model to more knowledge-enriched features extracted from the data-driven knowledge fusion module, we propose a two-level attention module that gradually learns shallow- and deep-level features of the samples to achieve more effective classification. We will prove the scalability of the knowledge fusion module while also verifying the efficacy of the proposed architecture by conducting experiments on 38 data sets across 6 categories.
Towards Interpreting Vulnerability of Multi-Instance Learning via Customized and Universal Adversarial Perturbations
Nov 30, 2022



Multi-instance learning (MIL) is a great paradigm for dealing with complex data and has achieved impressive achievements in a number of fields, including image classification, video anomaly detection, and far more. Each data sample is referred to as a bag containing several unlabeled instances, and the supervised information is only provided at the bag-level. The safety of MIL learners is concerning, though, as we can greatly fool them by introducing a few adversarial perturbations. This can be fatal in some cases, such as when users are unable to access desired images and criminals are attempting to trick surveillance cameras. In this paper, we design two adversarial perturbations to interpret the vulnerability of MIL methods. The first method can efficiently generate the bag-specific perturbation (called customized) with the aim of outsiding it from its original classification region. The second method builds on the first one by investigating the image-agnostic perturbation (called universal) that aims to affect all bags in a given data set and obtains some generalizability. We conduct various experiments to verify the performance of these two perturbations, and the results show that both of them can effectively fool MIL learners. We additionally propose a simple strategy to lessen the effects of adversarial perturbations. Source codes are available at https://github.com/InkiInki/MI-UAP.