 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Computation and Large Language Models: A Survey of Methods, Synergies, and Applications
May 21, 2025



Integrating Large Language Models (LLMs) and Evolutionary Computation (EC) represents a promising avenue for advancing artificial intelligence by combining powerful natural language understanding with optimization and search capabilities. This manuscript explores the synergistic potential of LLMs and EC, reviewing their intersections, complementary strengths, and emerging applications. We identify key opportunities where EC can enhance LLM training, fine-tuning, prompt engineering, and architecture search, while LLMs can, in turn, aid in automating the design, analysis, and interpretation of ECs. The manuscript explores the synergistic integration of EC and LLMs, highlighting their bidirectional contributions to advancing artificial intelligence. It first examines how EC techniques enhance LLMs by optimizing key components such as prompt engineering, hyperparameter tuning, and architecture search, demonstrating how evolutionary methods automate and refine these processes. Secondly, the survey investigates how LLMs improve EC by automating metaheuristic design, tuning evolutionary algorithms, and generating adaptive heuristics, thereby increasing efficiency and scalability. Emerging co-evolutionary frameworks are discussed, showcasing applications across diverse fields while acknowledging challenges like computational costs, interpretability, and algorithmic convergence. The survey concludes by identifying open research questions and advocating for hybrid approaches that combine the strengths of EC and LLMs.
Enhancing Explainability and Reliable Decision-Making in Particle Swarm Optimization through Communication Topologies
Apr 17, 2025

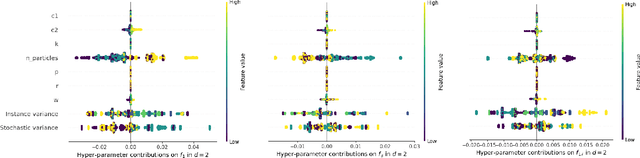

Swarm intelligence effectively optimizes complex systems across fields like engineering and healthcare, yet algorithm solutions often suffer from low reliability due to unclear configurations and hyperparameters. This study analyzes Particle Swarm Optimization (PSO), focusing on how different communication topologies Ring, Star, and Von Neumann affect convergence and search behaviors. Using an adapted IOHxplainer , an explainable benchmarking tool, we investigate how these topologies influence information flow, diversity, and convergence speed, clarifying the balance between exploration and exploitation. Through visualization and statistical analysis, the research enhances interpretability of PSO's decisions and provides practical guidelines for choosing suitable topologies for specific optimization tasks. Ultimately, this contributes to making swarm based optimization more transparent, robust, and trustworthy.
Building Interval Type-2 Fuzzy Membership Function: A Deck of Cards based Co-constructive Approach
Mar 03, 2025



Since its inception, Fuzzy Set has been widely used to handle uncertainty and imprecision in decision-making. However, conventional fuzzy sets, often referred to as type-1 fuzzy sets (T1FSs) have limitations in capturing higher levels of uncertainty, particularly when decision-makers (DMs) express hesitation or ambiguity in membership degree. To address this, Interval Type-2 Fuzzy Sets (IT2FSs) have been introduced by incorporating uncertainty in membership degree allocation, which enhanced flexibility in modelling subjective judgments. Despite their advantages, existing IT2FS construction methods often lack active involvement from DMs and that limits the interpretability and effectiveness of decision models. This study proposes a socio-technical co-constructive approach for developing IT2FS models of linguistic terms by facilitating the active involvement of DMs in preference elicitation and its application in multicriteria decision-making (MCDM) problems. Our methodology is structured in two phases. The first phase involves an interactive process between the DM and the decision analyst, in which a modified version of Deck-of-Cards (DoC) method is proposed to construct T1FS membership functions on a ratio scale. We then extend this method to incorporate ambiguity in subjective judgment and that resulted in an IT2FS model that better captures uncertainty in DM's linguistic assessments. The second phase formalizes the constructed IT2FS model for application in MCDM by defining an appropriate mathematical representation of such information, aggregation rules, and an admissible ordering principle. The proposed framework enhances the reliability and effectiveness of fuzzy decision-making not only by accurately representing DM's personalized semantics of linguistic information.
Machine learning for prediction of dose-volume histograms of organs-at-risk in prostate cancer from simple structure volume parameters
Nov 08, 2024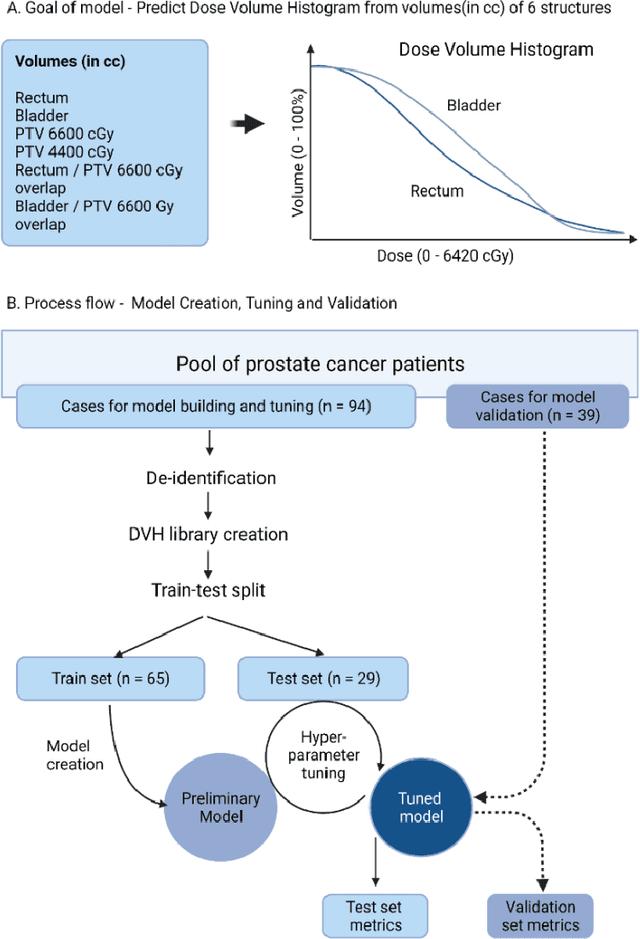


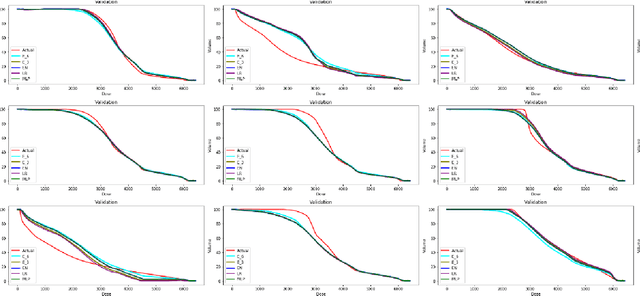
Dose prediction is an area of ongoing research that facilitates radiotherapy planning. Most commercial models utilise imaging data and intense computing resources. This study aimed to predict the dose-volume of rectum and bladder from volumes of target, at-risk structure organs and their overlap regions using machine learning. Dose-volume information of 94 patients with prostate cancer planned for 6000cGy in 20 fractions was exported from the treatment planning system as text files and mined to create a training dataset. Several statistical modelling, machine learning methods, and a new fuzzy rule-based prediction (FRBP) model were explored and validated on an independent dataset of 39 patients. The median absolute error was 2.0%-3.7% for bladder and 1.7-2.4% for rectum in the 4000-6420cGy range. For 5300cGy, 5600cGy and 6000cGy, the median difference was less than 2.5% for rectum and 3.8% for bladder. The FRBP model produced errors of 1.2%, 1.3%, 0.9% and 1.6%, 1.2%, 0.1% for the rectum and bladder respectively at these dose levels. These findings indicate feasibility of obtaining accurate predictions of the clinically important dose-volume parameters for rectum and bladder using just the volumes of these structures.
Data-driven Knowledge Fusion for Deep Multi-instance Learning
Apr 24, 2023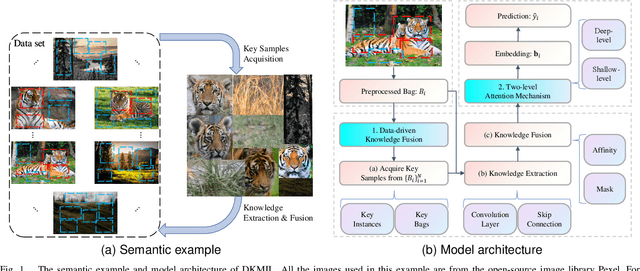
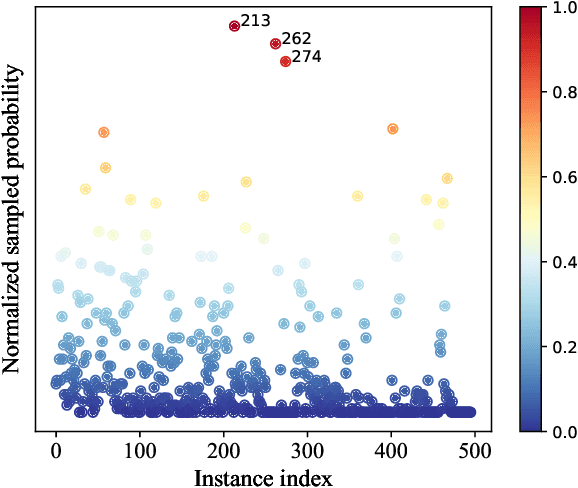
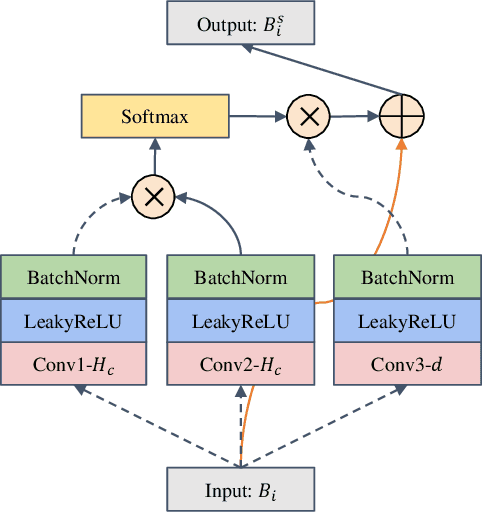
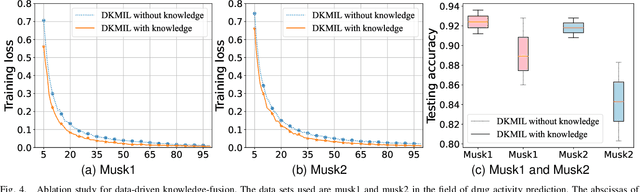
Multi-instance learning (MIL) is a widely-applied technique in practical applications that involve complex data structures. MIL can be broadly categorized into two types: traditional methods and those based on deep learning. These approaches have yielded significant results, especially with regards to their problem-solving strategies and experimental validation, providing valuable insights for researchers in the MIL field. However, a considerable amount of knowledge is often trapped within the algorithm, leading to subsequent MIL algorithms that solely rely on the model's data fitting to predict unlabeled samples. This results in a significant loss of knowledge and impedes the development of more intelligent models. In this paper, we propose a novel data-driven knowledge fusion for deep multi-instance learning (DKMIL) algorithm. DKMIL adopts a completely different idea from existing deep MIL methods by analyzing the decision-making of key samples in the data set (referred to as the data-driven) and using the knowledge fusion module designed to extract valuable information from these samples to assist the model's training. In other words, this module serves as a new interface between data and the model, providing strong scalability and enabling the use of prior knowledge from existing algorithms to enhance the learning ability of the model. Furthermore, to adapt the downstream modules of the model to more knowledge-enriched features extracted from the data-driven knowledge fusion module, we propose a two-level attention module that gradually learns shallow- and deep-level features of the samples to achieve more effective classification. We will prove the scalability of the knowledge fusion module while also verifying the efficacy of the proposed architecture by conducting experiments on 38 data sets across 6 categories.