 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOversampled Low Ambiguity Zone Sequences for Channel Estimation over Doubly Selective Channels
Sep 26, 2024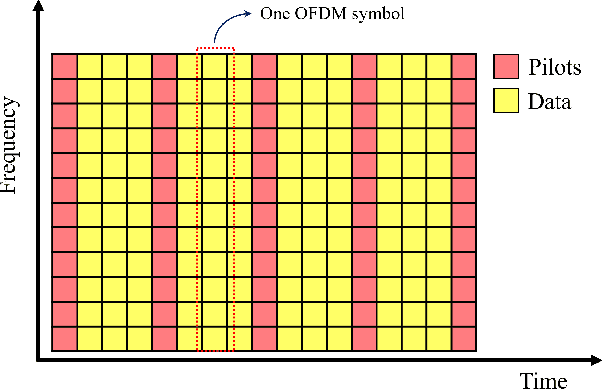
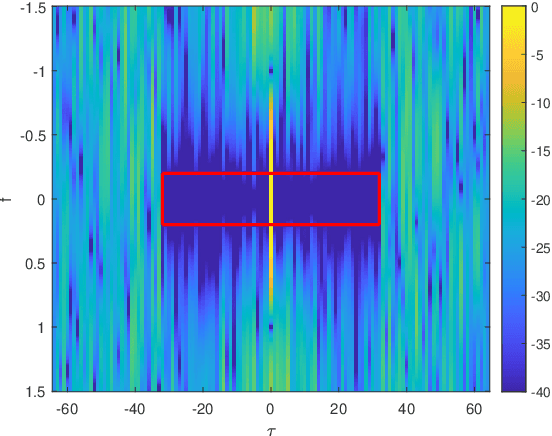
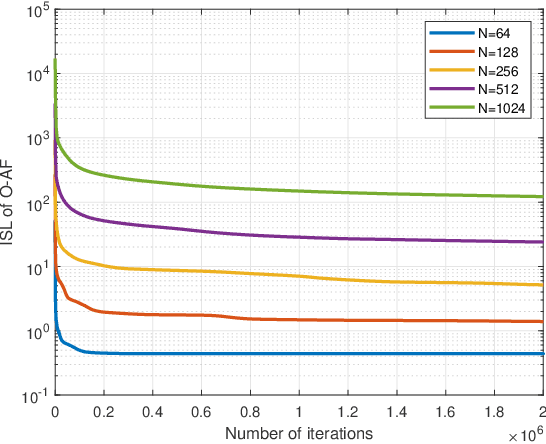
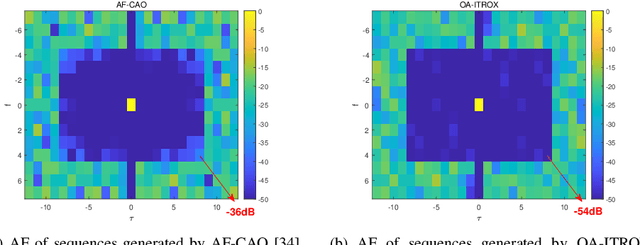
Pilot sequence design over doubly selective channels (DSC) is challenging due to the variations in both the time- and frequency-domains. Against this background, the contribution of this paper is twofold: Firstly, we investigate the optimal sequence design criteria for efficient channel estimation in orthogonal frequency division multiplexing systems under DSC. Secondly, to design pilot sequences that can satisfy the derived criteria, we propose a new metric called oversampled ambiguity function (O-AF), which considers both fractional and integer Doppler frequency shifts. Optimizing the sidelobes of O-AF through a modified iterative twisted approximation (ITROX) algorithm, we develop a new class of pilot sequences called ``oversampled low ambiguity zone (O-LAZ) sequences". Through numerical experiments, we evaluate the efficiency of the proposed O-LAZ sequences over the traditional low ambiguity zone (LAZ) sequences, Zadoff-Chu (ZC) sequences and m-sequences, by comparing their channel estimation performances over DSC.
Data-driven Knowledge Fusion for Deep Multi-instance Learning
Apr 24, 2023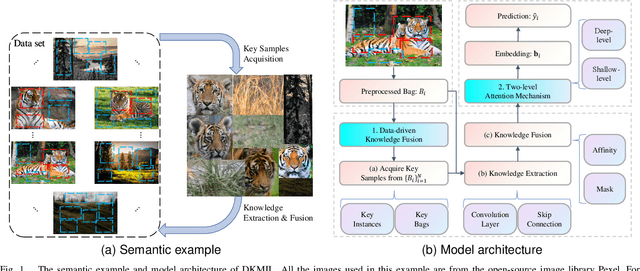
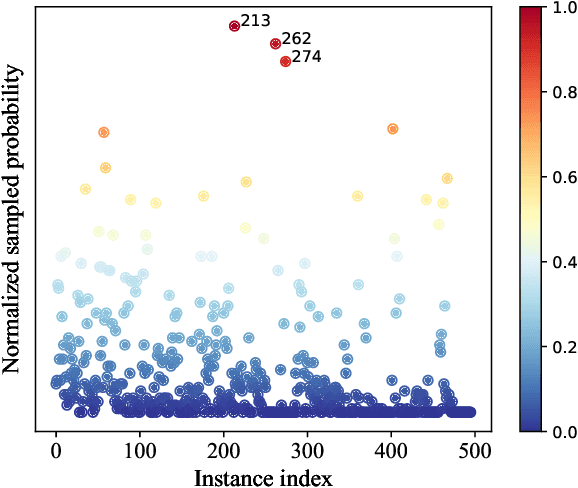
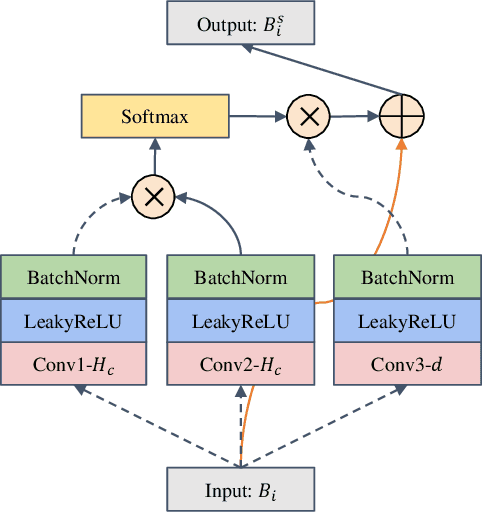
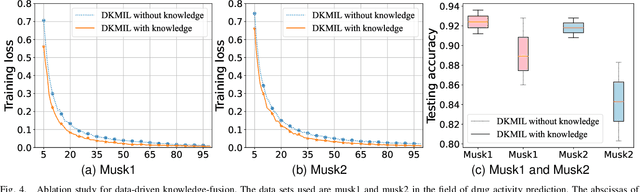
Multi-instance learning (MIL) is a widely-applied technique in practical applications that involve complex data structures. MIL can be broadly categorized into two types: traditional methods and those based on deep learning. These approaches have yielded significant results, especially with regards to their problem-solving strategies and experimental validation, providing valuable insights for researchers in the MIL field. However, a considerable amount of knowledge is often trapped within the algorithm, leading to subsequent MIL algorithms that solely rely on the model's data fitting to predict unlabeled samples. This results in a significant loss of knowledge and impedes the development of more intelligent models. In this paper, we propose a novel data-driven knowledge fusion for deep multi-instance learning (DKMIL) algorithm. DKMIL adopts a completely different idea from existing deep MIL methods by analyzing the decision-making of key samples in the data set (referred to as the data-driven) and using the knowledge fusion module designed to extract valuable information from these samples to assist the model's training. In other words, this module serves as a new interface between data and the model, providing strong scalability and enabling the use of prior knowledge from existing algorithms to enhance the learning ability of the model. Furthermore, to adapt the downstream modules of the model to more knowledge-enriched features extracted from the data-driven knowledge fusion module, we propose a two-level attention module that gradually learns shallow- and deep-level features of the samples to achieve more effective classification. We will prove the scalability of the knowledge fusion module while also verifying the efficacy of the proposed architecture by conducting experiments on 38 data sets across 6 categories.