 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Definite Iterated Belief Revision with Belief Algebras
May 10, 2025

Traditional logic-based belief revision research focuses on designing rules to constrain the behavior of revision operators. Frameworks have been proposed to characterize iterated revision rules, but they are often too loose, leading to multiple revision operators that all satisfy the rules under the same belief condition. In many practical applications, such as safety critical ones, it is important to specify a definite revision operator to enable agents to iteratively revise their beliefs in a deterministic way. In this paper, we propose a novel framework for iterated belief revision by characterizing belief information through preference relations. Semantically, both beliefs and new evidence are represented as belief algebras, which provide a rich and expressive foundation for belief revision. Building on traditional revision rules, we introduce additional postulates for revision with belief algebra, including an upper-bound constraint on the outcomes of revision. We prove that the revision result is uniquely determined given the current belief state and new evidence. Furthermore, to make the framework more useful in practice, we develop a particular algorithm for performing the proposed revision process. We argue that this approach may offer a more predictable and principled method for belief revision, making it suitable for real-world applications.
Waveform and Filter Design for Integrated Sensing and Communication Against Signal-dependent Modulated Jamming
Mar 19, 2025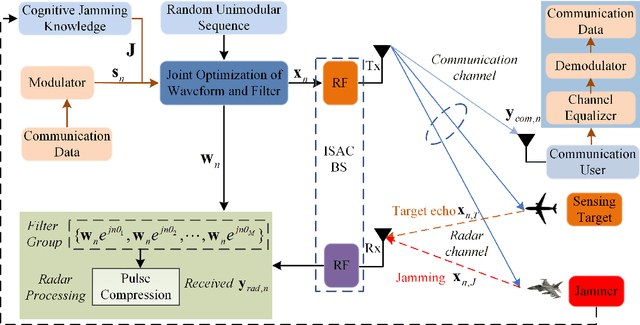


This paper focuses on an integrated sensing and communication (ISAC) system in the presence of signal-dependent modulated jamming (SDMJ). Our goal is to suppress jamming while carrying out simultaneous communications and sensing. We minimize the integrated sidelobe level (ISL) of the mismatch filter output for the transmitted waveform and the integrated level (IL) of the mismatch filter output for the jamming, under the constraints of the loss in-processing gain (LPG) and the peak-to-average power ratio (PAPR) of the transmitted waveform. Meanwhile, the similarity constraint is introduced for information-bearing transmit waveform. We develop a decoupled majorization minimization (DMM) algorithm to solve the proposed multi-constrained optimization problem. In contrast to the existing approaches, the proposed algorithm transforms the difficult optimization problem involving two variables into two parallel sub-problems with one variable, thus significantly speeding up the convergence rate. Furthermore, fast Fourier transform (FFT) is introduced to compute the closed-form solution of each sub-problem, giving rise to a greatly reduced computation complexity. Simulation results demonstrate the capabilities of the proposed ISAC system which strikes a proper trade-off among sensing and jamming suppression.
Oversampled Low Ambiguity Zone Sequences for Channel Estimation over Doubly Selective Channels
Sep 26, 2024
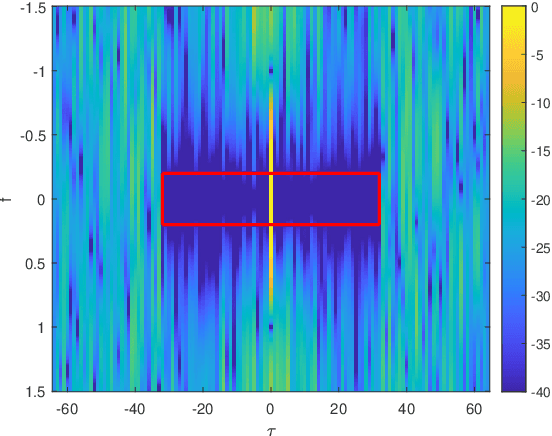
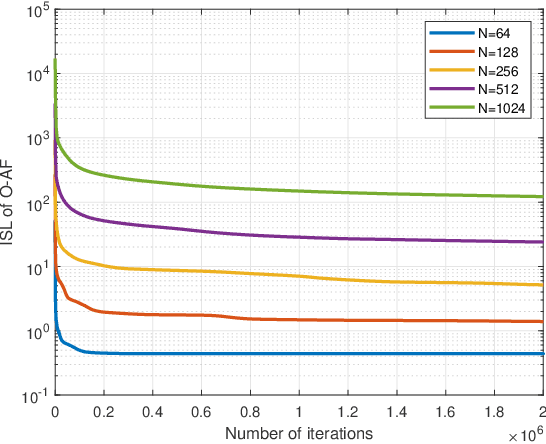
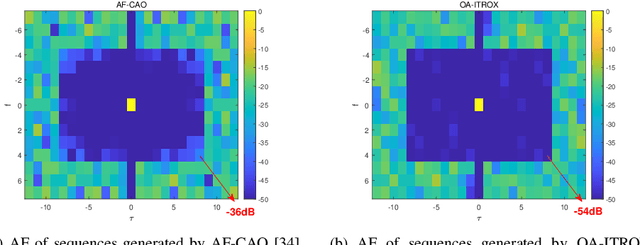
Pilot sequence design over doubly selective channels (DSC) is challenging due to the variations in both the time- and frequency-domains. Against this background, the contribution of this paper is twofold: Firstly, we investigate the optimal sequence design criteria for efficient channel estimation in orthogonal frequency division multiplexing systems under DSC. Secondly, to design pilot sequences that can satisfy the derived criteria, we propose a new metric called oversampled ambiguity function (O-AF), which considers both fractional and integer Doppler frequency shifts. Optimizing the sidelobes of O-AF through a modified iterative twisted approximation (ITROX) algorithm, we develop a new class of pilot sequences called ``oversampled low ambiguity zone (O-LAZ) sequences". Through numerical experiments, we evaluate the efficiency of the proposed O-LAZ sequences over the traditional low ambiguity zone (LAZ) sequences, Zadoff-Chu (ZC) sequences and m-sequences, by comparing their channel estimation performances over DSC.
Data-driven Knowledge Fusion for Deep Multi-instance Learning
Apr 24, 2023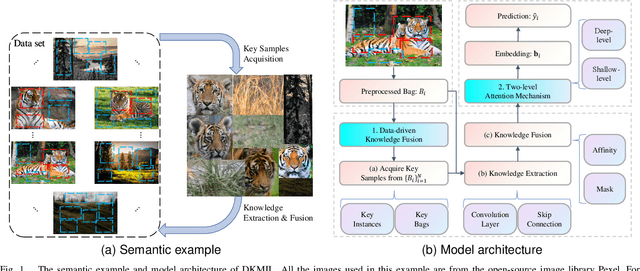
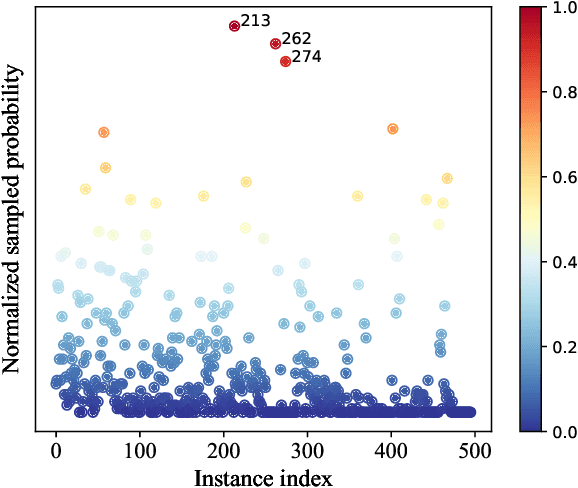
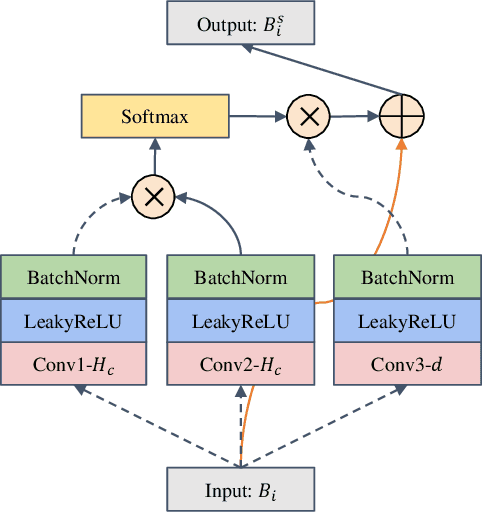
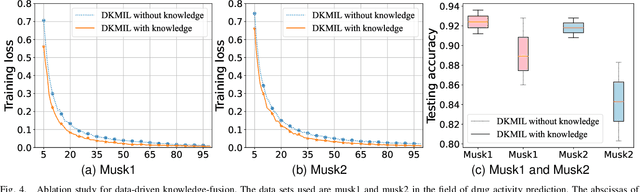
Multi-instance learning (MIL) is a widely-applied technique in practical applications that involve complex data structures. MIL can be broadly categorized into two types: traditional methods and those based on deep learning. These approaches have yielded significant results, especially with regards to their problem-solving strategies and experimental validation, providing valuable insights for researchers in the MIL field. However, a considerable amount of knowledge is often trapped within the algorithm, leading to subsequent MIL algorithms that solely rely on the model's data fitting to predict unlabeled samples. This results in a significant loss of knowledge and impedes the development of more intelligent models. In this paper, we propose a novel data-driven knowledge fusion for deep multi-instance learning (DKMIL) algorithm. DKMIL adopts a completely different idea from existing deep MIL methods by analyzing the decision-making of key samples in the data set (referred to as the data-driven) and using the knowledge fusion module designed to extract valuable information from these samples to assist the model's training. In other words, this module serves as a new interface between data and the model, providing strong scalability and enabling the use of prior knowledge from existing algorithms to enhance the learning ability of the model. Furthermore, to adapt the downstream modules of the model to more knowledge-enriched features extracted from the data-driven knowledge fusion module, we propose a two-level attention module that gradually learns shallow- and deep-level features of the samples to achieve more effective classification. We will prove the scalability of the knowledge fusion module while also verifying the efficacy of the proposed architecture by conducting experiments on 38 data sets across 6 categories.
Towards Interpreting Vulnerability of Multi-Instance Learning via Customized and Universal Adversarial Perturbations
Nov 30, 2022



Multi-instance learning (MIL) is a great paradigm for dealing with complex data and has achieved impressive achievements in a number of fields, including image classification, video anomaly detection, and far more. Each data sample is referred to as a bag containing several unlabeled instances, and the supervised information is only provided at the bag-level. The safety of MIL learners is concerning, though, as we can greatly fool them by introducing a few adversarial perturbations. This can be fatal in some cases, such as when users are unable to access desired images and criminals are attempting to trick surveillance cameras. In this paper, we design two adversarial perturbations to interpret the vulnerability of MIL methods. The first method can efficiently generate the bag-specific perturbation (called customized) with the aim of outsiding it from its original classification region. The second method builds on the first one by investigating the image-agnostic perturbation (called universal) that aims to affect all bags in a given data set and obtains some generalizability. We conduct various experiments to verify the performance of these two perturbations, and the results show that both of them can effectively fool MIL learners. We additionally propose a simple strategy to lessen the effects of adversarial perturbations. Source codes are available at https://github.com/InkiInki/MI-UAP.
HpGAN: Sequence Search with Generative Adversarial Networks
Dec 10, 2020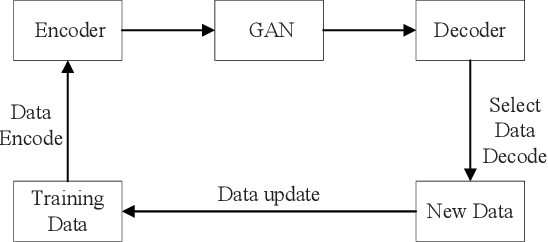
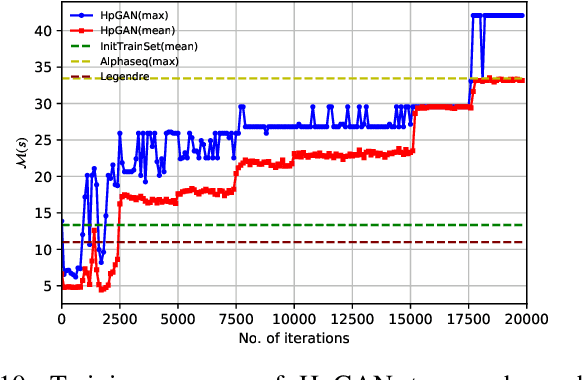
Sequences play an important role in many engineering applications and systems. Searching sequences with desired properties has long been an interesting but also challenging research topic. This article proposes a novel method, called HpGAN, to search desired sequences algorithmically using generative adversarial networks (GAN). HpGAN is based on the idea of zero-sum game to train a generative model, which can generate sequences with characteristics similar to the training sequences. In HpGAN, we design the Hopfield network as an encoder to avoid the limitations of GAN in generating discrete data. Compared with traditional sequence construction by algebraic tools, HpGAN is particularly suitable for intractable problems with complex objectives which prevent mathematical analysis. We demonstrate the search capabilities of HpGAN in two applications: 1) HpGAN successfully found many different mutually orthogonal complementary code sets (MOCCS) and optimal odd-length Z-complementary pairs (OB-ZCPs) which are not part of the training set. In the literature, both MOCSSs and OB-ZCPs have found wide applications in wireless communications. 2) HpGAN found new sequences which achieve four-times increase of signal-to-interference ratio--benchmarked against the well-known Legendre sequence--of a mismatched filter (MMF) estimator in pulse compression radar systems. These sequences outperform those found by AlphaSeq.