 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoIFNet: A Unified Framework for Multivariate Time Series Forecasting with Missing Values
Jun 16, 2025Multivariate time series forecasting (MTSF) is a critical task with broad applications in domains such as meteorology, transportation, and economics. Nevertheless, pervasive missing values caused by sensor failures or human errors significantly degrade forecasting accuracy. Prior efforts usually employ an impute-then-forecast paradigm, leading to suboptimal predictions due to error accumulation and misaligned objectives between the two stages. To address this challenge, we propose the Collaborative Imputation-Forecasting Network (CoIFNet), a novel framework that unifies imputation and forecasting to achieve robust MTSF in the presence of missing values. Specifically, CoIFNet takes the observed values, mask matrix and timestamp embeddings as input, processing them sequentially through the Cross-Timestep Fusion (CTF) and Cross-Variate Fusion (CVF) modules to capture temporal dependencies that are robust to missing values. We provide theoretical justifications on how our CoIFNet learning objective improves the performance bound of MTSF with missing values. Through extensive experiments on challenging MSTF benchmarks, we demonstrate the effectiveness and computational efficiency of our proposed approach across diverse missing-data scenarios, e.g., CoIFNet outperforms the state-of-the-art method by $\underline{\textbf{24.40}}$% ($\underline{\textbf{23.81}}$%) at a point (block) missing rate of 0.6, while improving memory and time efficiency by $\underline{\boldsymbol{4.3\times}}$ and $\underline{\boldsymbol{2.1\times}}$, respectively.
Computation Capacity Maximization for Pinching Antennas-Assisted Wireless Powered MEC Systems
Jun 09, 2025In this paper,we investigate a novel wireless powered mobile edge computing (MEC) system assisted by pinching antennas (PAs), where devices first harvest energy from a base station and then offload computation-intensive tasks to an MEC server. As an emerging technology, PAs utilize long dielectric waveguides embedded with multiple localized dielectric particles, which can be spatially configured through a pinching mechanism to effectively reduce large-scale propagation loss. This capability facilitates both efficient downlink energy transfer and uplink task offloading. To fully exploit these advantages, we adopt a non-orthogonal multiple access (NOMA) framework and formulate a joint optimization problem to maximize the system's computational capacity by jointly optimizing device transmit power, time allocation, PA positions in both uplink and downlink, and radiation control. To address the resulting non-convexity caused by variable coupling, we develop an alternating optimization algorithm that integrates particle swarm optimization (PSO) with successive convex approximation. Simulation results demonstrate that the proposed PA-assisted design substantially improves both energy harvesting efficiency and computational performance compared to conventional antenna systems.
On Definite Iterated Belief Revision with Belief Algebras
May 10, 2025

Traditional logic-based belief revision research focuses on designing rules to constrain the behavior of revision operators. Frameworks have been proposed to characterize iterated revision rules, but they are often too loose, leading to multiple revision operators that all satisfy the rules under the same belief condition. In many practical applications, such as safety critical ones, it is important to specify a definite revision operator to enable agents to iteratively revise their beliefs in a deterministic way. In this paper, we propose a novel framework for iterated belief revision by characterizing belief information through preference relations. Semantically, both beliefs and new evidence are represented as belief algebras, which provide a rich and expressive foundation for belief revision. Building on traditional revision rules, we introduce additional postulates for revision with belief algebra, including an upper-bound constraint on the outcomes of revision. We prove that the revision result is uniquely determined given the current belief state and new evidence. Furthermore, to make the framework more useful in practice, we develop a particular algorithm for performing the proposed revision process. We argue that this approach may offer a more predictable and principled method for belief revision, making it suitable for real-world applications.
Clustering by Mining Density Distributions and Splitting Manifold Structure
Aug 20, 2024

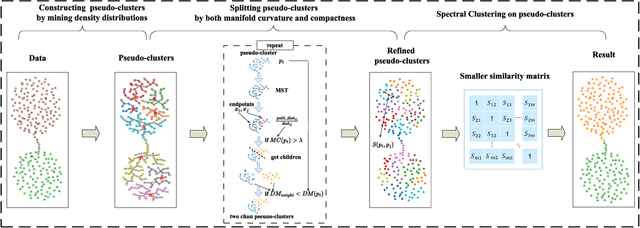

Spectral clustering requires the time-consuming decomposition of the Laplacian matrix of the similarity graph, thus limiting its applicability to large datasets. To improve the efficiency of spectral clustering, a top-down approach was recently proposed, which first divides the data into several micro-clusters (granular-balls), then splits these micro-clusters when they are not "compact'', and finally uses these micro-clusters as nodes to construct a similarity graph for more efficient spectral clustering. However, this top-down approach is challenging to adapt to unevenly distributed or structurally complex data. This is because constructing micro-clusters as a rough ball struggles to capture the shape and structure of data in a local range, and the simplistic splitting rule that solely targets ``compactness'' is susceptible to noise and variations in data density and leads to micro-clusters with varying shapes, making it challenging to accurately measure the similarity between them. To resolve these issues, this paper first proposes to start from local structures to obtain micro-clusters, such that the complex structural information inside local neighborhoods is well captured by them. Moreover, by noting that Euclidean distance is more suitable for convex sets, this paper further proposes a data splitting rule that couples local density and data manifold structures, so that the similarities of the obtained micro-clusters can be easily characterized. A novel similarity measure between micro-clusters is then proposed for the final spectral clustering. A series of experiments based on synthetic and real-world datasets demonstrate that the proposed method has better adaptability to structurally complex data than granular-ball based methods.
TANGO: Clustering with Typicality-Aware Nonlocal Mode-Seeking and Graph-Cut Optimization
Aug 19, 2024



Density-based clustering methods by mode-seeking usually achieve clustering by using local density estimation to mine structural information, such as local dependencies from lower density points to higher neighbors. However, they often rely too heavily on \emph{local} structures and neglect \emph{global} characteristics, which can lead to significant errors in peak selection and dependency establishment. Although introducing more hyperparameters that revise dependencies can help mitigate this issue, tuning them is challenging and even impossible on real-world datasets. In this paper, we propose a new algorithm (TANGO) to establish local dependencies by exploiting a global-view \emph{typicality} of points, which is obtained by mining further the density distributions and initial dependencies. TANGO then obtains sub-clusters with the help of the adjusted dependencies, and characterizes the similarity between sub-clusters by incorporating path-based connectivity. It achieves final clustering by employing graph-cut on sub-clusters, thus avoiding the challenging selection of cluster centers. Moreover, this paper provides theoretical analysis and an efficient method for the calculation of typicality. Experimental results on several synthetic and $16$ real-world datasets demonstrate the effectiveness and superiority of TANGO.
Towards Interpreting Vulnerability of Multi-Instance Learning via Customized and Universal Adversarial Perturbations
Nov 30, 2022



Multi-instance learning (MIL) is a great paradigm for dealing with complex data and has achieved impressive achievements in a number of fields, including image classification, video anomaly detection, and far more. Each data sample is referred to as a bag containing several unlabeled instances, and the supervised information is only provided at the bag-level. The safety of MIL learners is concerning, though, as we can greatly fool them by introducing a few adversarial perturbations. This can be fatal in some cases, such as when users are unable to access desired images and criminals are attempting to trick surveillance cameras. In this paper, we design two adversarial perturbations to interpret the vulnerability of MIL methods. The first method can efficiently generate the bag-specific perturbation (called customized) with the aim of outsiding it from its original classification region. The second method builds on the first one by investigating the image-agnostic perturbation (called universal) that aims to affect all bags in a given data set and obtains some generalizability. We conduct various experiments to verify the performance of these two perturbations, and the results show that both of them can effectively fool MIL learners. We additionally propose a simple strategy to lessen the effects of adversarial perturbations. Source codes are available at https://github.com/InkiInki/MI-UAP.
Restricted Boltzmann Machines with Gaussian Visible Units Guided by Pairwise Constraints
Jan 13, 2017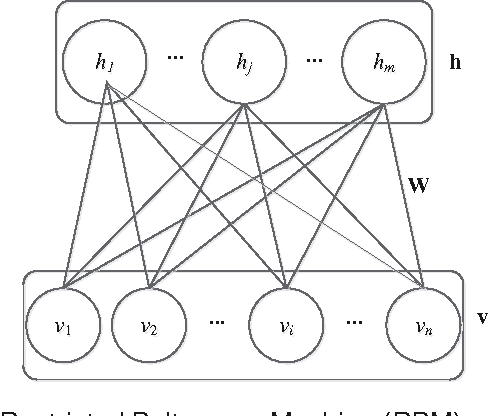
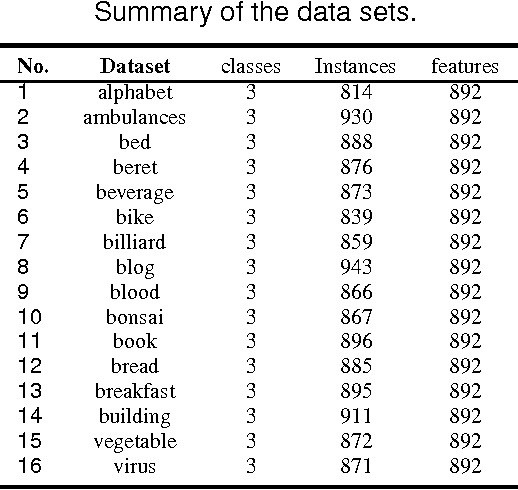
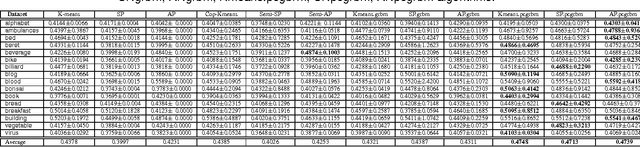
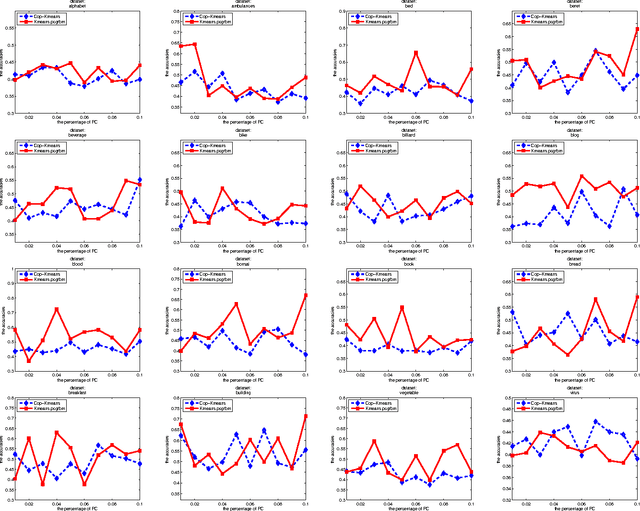
Restricted Boltzmann machines (RBMs) and their variants are usually trained by contrastive divergence (CD) learning, but the training procedure is an unsupervised learning approach, without any guidances of the background knowledge. To enhance the expression ability of traditional RBMs, in this paper, we propose pairwise constraints restricted Boltzmann machine with Gaussian visible units (pcGRBM) model, in which the learning procedure is guided by pairwise constraints and the process of encoding is conducted under these guidances. The pairwise constraints are encoded in hidden layer features of pcGRBM. Then, some pairwise hidden features of pcGRBM flock together and another part of them are separated by the guidances. In order to deal with real-valued data, the binary visible units are replaced by linear units with Gausian noise in the pcGRBM model. In the learning process of pcGRBM, the pairwise constraints are iterated transitions between visible and hidden units during CD learning procedure. Then, the proposed model is inferred by approximative gradient descent method and the corresponding learning algorithm is designed in this paper. In order to compare the availability of pcGRBM and traditional RBMs with Gaussian visible units, the features of the pcGRBM and RBMs hidden layer are used as input 'data' for K-means, spectral clustering (SP) and affinity propagation (AP) algorithms, respectively. A thorough experimental evaluation is performed with sixteen image datasets of Microsoft Research Asia Multimedia (MSRA-MM). The experimental results show that the clustering performance of K-means, SP and AP algorithms based on pcGRBM model are significantly better than traditional RBMs. In addition, the pcGRBM model for clustering task shows better performance than some semi-supervised clustering algorithms.