 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Disentanglement for Full-Reference Image Quality Assessment
Apr 23, 2026Existing deep network-based full-reference image quality assessment (FR-IQA) models typically work by performing pairwise comparisons of deep features from the reference and distorted images. In this paper, we approach this problem from a different perspective and propose a novel FR-IQA paradigm based on causal inference and decoupled representation learning. Unlike typical feature comparison-based FR-IQA models, our approach formulates degradation estimation as a causal disentanglement process guided by intervention on latent representations. We first decouple degradation and content representations by exploiting the content invariance between the reference and distorted images. Second, inspired by the human visual masking effect, we design a masking module to model the causal relationship between image content and degradation features, thereby extracting content-influenced degradation features from distorted images. Finally, quality scores are predicted from these degradation features using either supervised regression or label-free dimensionality reduction. Extensive experiments demonstrate that our method achieves highly competitive performance on standard IQA benchmarks across fully supervised, few-label, and label-free settings. Furthermore, we evaluate the approach on diverse non-standard natural image domains with scarce data, including underwater, radiographic, medical, neutron, and screen-content images. Benefiting from its ability to perform scenario-specific training and prediction without labeled IQA data, our method exhibits superior cross-domain generalization compared to existing training-free FR-IQA models.
Causally Sufficient and Necessary Feature Expansion for Class-Incremental Learning
Mar 10, 2026Current expansion-based methods for Class Incremental Learning (CIL) effectively mitigate catastrophic forgetting by freezing old features. However, such task-specific features learned from the new task may collide with the old features. From a causal perspective, spurious feature correlations are the main cause of this collision, manifesting in two scopes: (i) guided by empirical risk minimization (ERM), intra-task spurious correlations cause task-specific features to rely on shortcut features. These non-robust features are vulnerable to interference, inevitably drifting into the feature space of other tasks; (ii) inter-task spurious correlations induce semantic confusion between visually similar classes across tasks. To address this, we propose a Probability of Necessity and Sufficiency (PNS)-based regularization method to guide feature expansion in CIL. Specifically, we first extend the definition of PNS to expansion-based CIL, termed CPNS, which quantifies both the causal completeness of intra-task representations and the separability of inter-task representations. We then introduce a dual-scope counterfactual generator based on twin networks to ensure the measurement of CPNS, which simultaneously generates: (i) intra-task counterfactual features to minimize intra-task PNS risk and ensure causal completeness of task-specific features, and (ii) inter-task interfering features to minimize inter-task PNS risk, ensuring the separability of inter-task representations. Theoretical analyses confirm its reliability. The regularization is a plug-and-play method for expansion-based CIL to mitigate feature collision. Extensive experiments demonstrate the effectiveness of the proposed method.
Variational Bayesian Personalized Ranking
Mar 14, 2025Recommendation systems have found extensive applications across diverse domains. However, the training data available typically comprises implicit feedback, manifested as user clicks and purchase behaviors, rather than explicit declarations of user preferences. This type of training data presents three main challenges for accurate ranking prediction: First, the unobservable nature of user preferences makes likelihood function modeling inherently difficult. Second, the resulting false positives (FP) and false negatives (FN) introduce noise into the learning process, disrupting parameter learning. Third, data bias arises as observed interactions tend to concentrate on a few popular items, exacerbating the feedback loop of popularity bias. To address these issues, we propose Variational BPR, a novel and easily implementable learning objective that integrates key components for enhancing collaborative filtering: likelihood optimization, noise reduction, and popularity debiasing. Our approach involves decomposing the pairwise loss under the ELBO-KL framework and deriving its variational lower bound to establish a manageable learning objective for approximate inference. Within this bound, we introduce an attention-based latent interest prototype contrastive mechanism, replacing instance-level contrastive learning, to effectively reduce noise from problematic samples. The process of deriving interest prototypes implicitly incorporates a flexible hard sample mining strategy, capable of simultaneously identifying hard positive and hard negative samples. Furthermore, we demonstrate that this hard sample mining strategy promotes feature distribution uniformity, thereby alleviating popularity bias. Empirically, we demonstrate the effectiveness of Variational BPR on popular backbone recommendation models. The code and data are available at: https://github.com/liubin06/VariationalBPR
Adaptive Paradigm Synergy: Can a Cross-Paradigm Objective Enhance Long-Tailed Learning?
Oct 30, 2024Self-supervised learning (SSL) has achieved impressive results across several computer vision tasks, even rivaling supervised methods. However, its performance degrades on real-world datasets with long-tailed distributions due to difficulties in capturing inherent class imbalances. Although supervised long-tailed learning offers significant insights, the absence of labels in SSL prevents direct transfer of these strategies.To bridge this gap, we introduce Adaptive Paradigm Synergy (APS), a cross-paradigm objective that seeks to unify the strengths of both paradigms. Our approach reexamines contrastive learning from a spatial structure perspective, dynamically adjusting the uniformity of latent space structure through adaptive temperature tuning. Furthermore, we draw on a re-weighting strategy from supervised learning to compensate for the shortcomings of temperature adjustment in explicit quantity perception.Extensive experiments on commonly used long-tailed datasets demonstrate that APS improves performance effectively and efficiently. Our findings reveal the potential for deeper integration between supervised and self-supervised learning, paving the way for robust models that handle real-world class imbalance.
Dynamic Backtracking in GFlowNets: Enhancing Decision Steps with Reward-Dependent Adjustment Mechanisms
Apr 09, 2024Generative Flow Networks (GFlowNets) are probabilistic models predicated on Markov flows, employing specific amortization algorithms to learn stochastic policies that generate compositional substances including biomolecules, chemical materials, and more. Demonstrating formidable prowess in generating high-performance biochemical molecules, GFlowNets accelerate the discovery of scientific substances, effectively circumventing the time-consuming, labor-intensive, and costly shortcomings intrinsic to conventional material discovery. However, previous work often struggles to accumulate exploratory experience and is prone to becoming disoriented within expansive sampling spaces. Attempts to address this issue, such as LS-GFN, are limited to local greedy searches and lack broader global adjustments. This paper introduces a novel GFlowNets variant, the Dynamic Backtracking GFN (DB-GFN), which enhances the adaptability of decision-making steps through a reward-based dynamic backtracking mechanism. DB-GFN permits backtracking during the network construction process according to the current state's reward value, thus correcting disadvantageous decisions and exploring alternative pathways during the exploration process. Applied to generative tasks of biochemical molecules and genetic material sequences, DB-GFN surpasses existing GFlowNets models and traditional reinforcement learning methods in terms of sample quality, exploration sample quantity, and training convergence speed. Furthermore, the orthogonal nature of DB-GFN suggests its potential as a powerful tool for future improvements in GFlowNets, with the promise of integrating with other strategies to achieve more efficient search performance.
Learning Spiking Neural Network from Easy to Hard task
Sep 26, 2023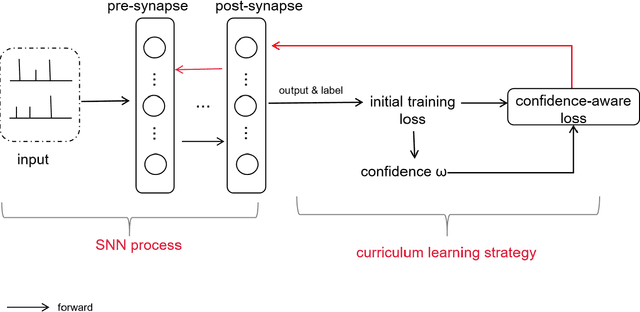
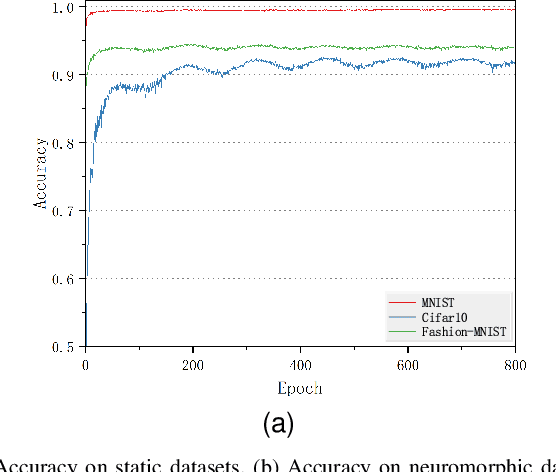
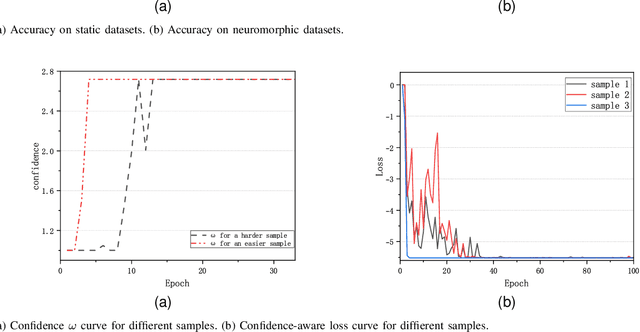
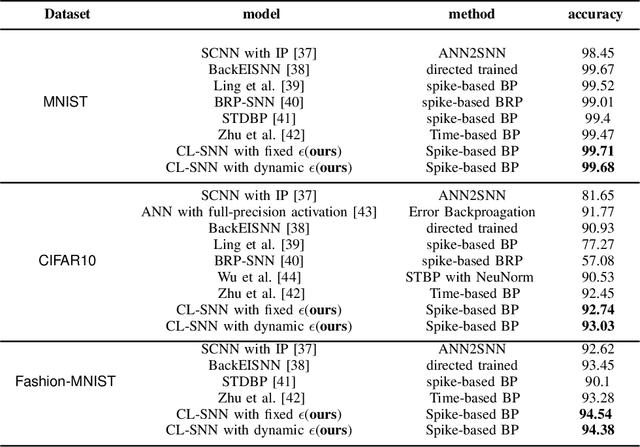
Starting with small and simple concepts, and gradually introducing complex and difficult concepts is the natural process of human learning. Spiking Neural Networks (SNNs) aim to mimic the way humans process information, but current SNNs models treat all samples equally, which does not align with the principles of human learning and overlooks the biological plausibility of SNNs. To address this, we propose a CL-SNN model that introduces Curriculum Learning(CL) into SNNs, making SNNs learn more like humans and providing higher biological interpretability. CL is a training strategy that advocates presenting easier data to models before gradually introducing more challenging data, mimicking the human learning process. We use a confidence-aware loss to measure and process the samples with different difficulty levels. By learning the confidence of different samples, the model reduces the contribution of difficult samples to parameter optimization automatically. We conducted experiments on static image datasets MNIST, Fashion-MNIST, CIFAR10, and neuromorphic datasets N-MNIST, CIFAR10-DVS, DVS-Gesture. The results are promising. To our best knowledge, this is the first proposal to enhance the biologically plausibility of SNNs by introducing CL.
Minor Constraint Disturbances for Deep Semi-supervised Learning
Mar 13, 2020
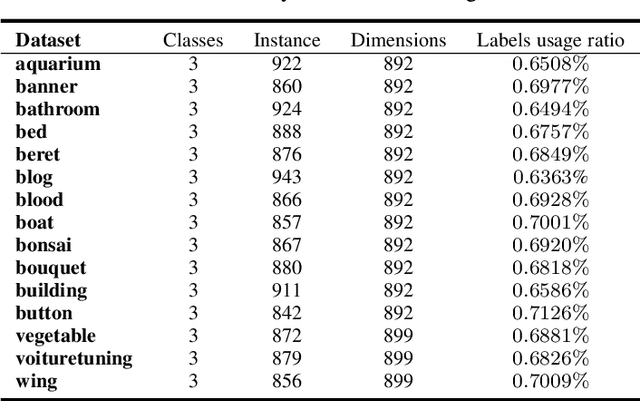

In high-dimensional data space, semi-supervised feature learning based on Euclidean distance shows instability under a broad set of conditions. Furthermore, the scarcity and high cost of labels prompt us to explore new semi-supervised learning methods with the fewest labels. In this paper, we develop a novel Minor Constraint Disturbances-based Deep Semi-supervised Feature Learning framework (MCD-DSFL) from the perspective of probability distribution for feature representation. There are two fundamental modules in the proposed framework: one is a Minor Constraint Disturbances-based restricted Boltzmann machine with Gaussian visible units (MCDGRBM) for modelling continuous data and the other is a Minor Constraint Disturbances-based restricted Boltzmann machine (MCDRBM) for modelling binary data. The Minor Constraint Disturbances (MCD) consist of less instance-level constraints which are produced by only two randomly selected labels from each class. The Kullback-Leibler (KL) divergences of the MCD are fused into the Contrastive Divergence (CD) learning for training the proposed MCDGRBM and MCDRBM models. Then, the probability distributions of hidden layer features are as similar as possible in the same class and they are as dissimilar as possible in the different classes simultaneously. Despite the weak influence of the MCD for our shallow models (MCDGRBM and MCDRBM), the proposed deep MCD-DSFL framework improves the representation capability significantly under its leverage effect. The semi-supervised strategy based on the KL divergence of the MCD significantly reduces the reliance on the labels and improves the stability of the semi-supervised feature learning in high-dimensional space simultaneously.
DCEF: Deep Collaborative Encoder Framework for Unsupervised Clustering
Jun 12, 2019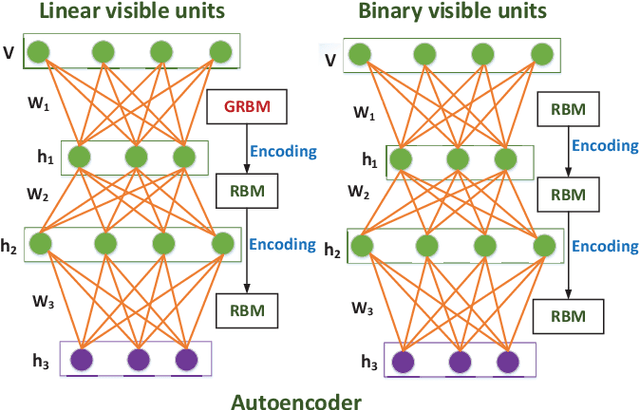

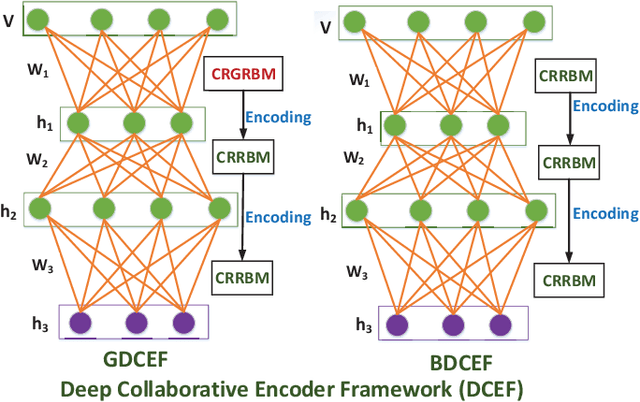
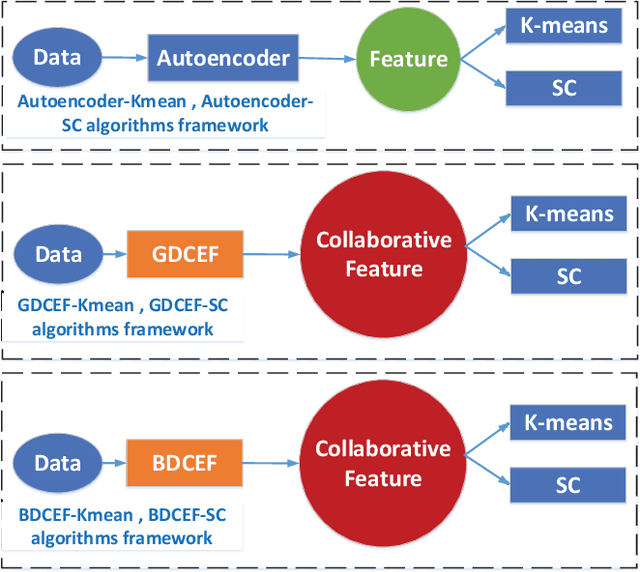
Collaborative representation is a popular feature learning approach, which encoding process is assisted by variety types of information. In this paper, we propose a collaborative representation restricted Boltzmann Machine (CRRBM) for modeling binary data and a collaborative representation Gaussian restricted Boltzmann Machine (CRGRBM) for modeling realvalued data by applying a collaborative representation strategy in the encoding procedure. We utilize Locality Sensitive Hashing (LSH) to generate similar sample subsets of the instance and observed feature set simultaneously from input data. Hence, we can obtain some mini blocks, which come from the intersection of instance and observed feature subsets. Then we integrate Contrastive Divergence and Bregman Divergence methods with mini blocks to optimize our CRRBM and CRGRBM models. In their training process, the complex collaborative relationships between multiple instances and features are fused into the hidden layer encoding. Hence, these encodings have dual characteristics of concealment and cooperation. Here, we develop two deep collaborative encoder frameworks (DCEF) based on the CRRBM and CRGRBM models: one is a DCEF with Gaussian linear visible units (GDCEF) for modeling real-valued data, and the other is a DCEF with binary visible units (BDCEF) for modeling binary data. We explore the collaborative representation capability of the hidden features in every layer of the GDCEF and BDCEF framework, especially in the deepest hidden layer. The experimental results show that the GDCEF and BDCEF frameworks have more outstanding performances than the classic Autoencoder framework for unsupervised clustering task on the MSRA-MM2.0 and UCI datasets, respectively.
Self-learning Local Supervision Encoding Framework to Constrict and Disperse Feature Distribution for Clustering
Dec 05, 2018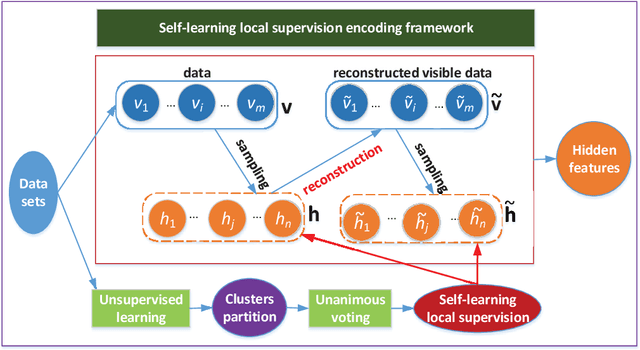


To obtain suitable feature distribution is a difficult task in machine learning, especially for unsupervised learning. In this paper, we propose a novel self-learning local supervision encoding framework based on RBMs, in which the self-learning local supervisions from visible layer are integrated into the contrastive divergence (CD) learning of RBMs to constrict and disperse the distribution of the hidden layer features for clustering tasks. In the framework, we use sigmoid transformation to obtain hidden layer and reconstructed hidden layer features from visible layer and reconstructed visible layer units during sampling procedure. The self-learning local supervisions contain local credible clusters which stem from different unsupervised learning and unanimous voting strategy. They are fused into hidden layer features and reconstructed hidden layer features. For the same local clusters, the hidden features and reconstructed hidden layer features of the framework tend to constrict together. Furthermore, the hidden layer features of different local clusters tend to disperse in the encoding process. Under such framework, we present two instantiation models with the reconstruction of two different visible layers. One is self-learning local supervision GRBM (slsGRBM) model with Gaussian linear visible units and binary hidden units using linear transformation for visible layer reconstruction. The other is self-learning local supervision RBM (slsRBM) model with binary visible and hidden units using sigmoid transformation for visible layer reconstruction.
Restricted Boltzmann Machines with Gaussian Visible Units Guided by Pairwise Constraints
Jan 13, 2017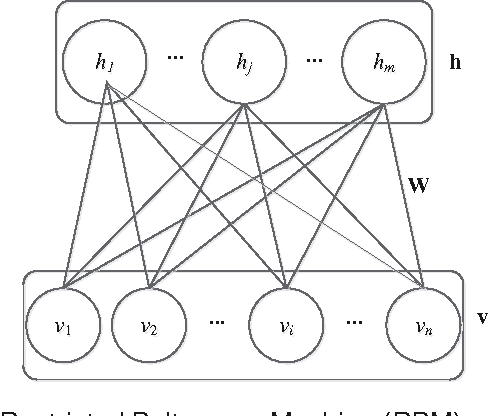
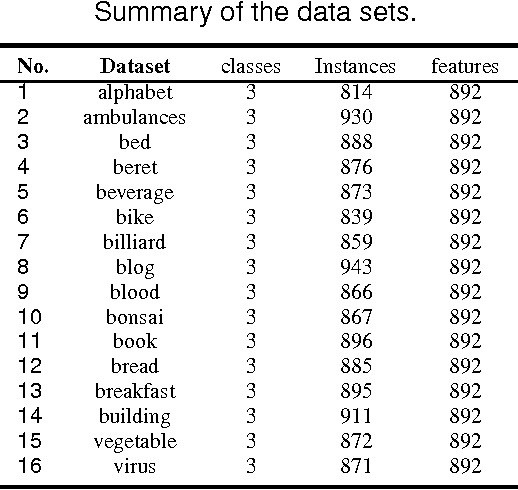
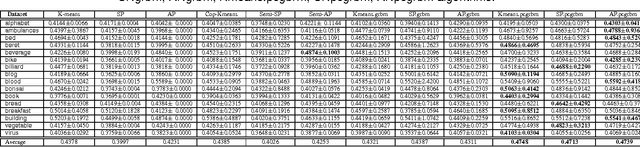
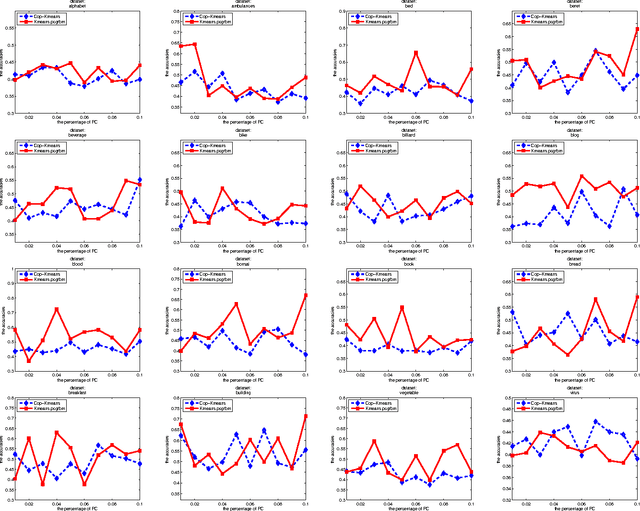
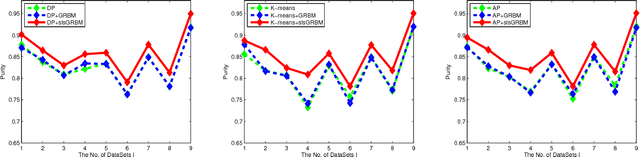
Restricted Boltzmann machines (RBMs) and their variants are usually trained by contrastive divergence (CD) learning, but the training procedure is an unsupervised learning approach, without any guidances of the background knowledge. To enhance the expression ability of traditional RBMs, in this paper, we propose pairwise constraints restricted Boltzmann machine with Gaussian visible units (pcGRBM) model, in which the learning procedure is guided by pairwise constraints and the process of encoding is conducted under these guidances. The pairwise constraints are encoded in hidden layer features of pcGRBM. Then, some pairwise hidden features of pcGRBM flock together and another part of them are separated by the guidances. In order to deal with real-valued data, the binary visible units are replaced by linear units with Gausian noise in the pcGRBM model. In the learning process of pcGRBM, the pairwise constraints are iterated transitions between visible and hidden units during CD learning procedure. Then, the proposed model is inferred by approximative gradient descent method and the corresponding learning algorithm is designed in this paper. In order to compare the availability of pcGRBM and traditional RBMs with Gaussian visible units, the features of the pcGRBM and RBMs hidden layer are used as input 'data' for K-means, spectral clustering (SP) and affinity propagation (AP) algorithms, respectively. A thorough experimental evaluation is performed with sixteen image datasets of Microsoft Research Asia Multimedia (MSRA-MM). The experimental results show that the clustering performance of K-means, SP and AP algorithms based on pcGRBM model are significantly better than traditional RBMs. In addition, the pcGRBM model for clustering task shows better performance than some semi-supervised clustering algorithms.