 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradual Domain Adaptation for Graph Learning
Jan 29, 2025



Existing literature lacks a graph domain adaptation technique for handling large distribution shifts, primarily due to the difficulty in simulating an evolving path from source to target graph. To make a breakthrough, we present a graph gradual domain adaptation (GGDA) framework with the construction of a compact domain sequence that minimizes information loss in adaptations. Our approach starts with an efficient generation of knowledge-preserving intermediate graphs over the Fused Gromov-Wasserstein (FGW) metric. With the bridging data pool, GGDA domains are then constructed via a novel vertex-based domain progression, which comprises "close" vertex selections and adaptive domain advancement to enhance inter-domain information transferability. Theoretically, our framework concretizes the intractable inter-domain distance $W_p(\mu_t,\mu_{t+1})$ via implementable upper and lower bounds, enabling flexible adjustments of this metric for optimizing domain formation. Extensive experiments under various transfer scenarios validate the superior performance of our GGDA framework.
Augmenting Document-level Relation Extraction with Efficient Multi-Supervision
Jul 01, 2024Despite its popularity in sentence-level relation extraction, distantly supervised data is rarely utilized by existing work in document-level relation extraction due to its noisy nature and low information density. Among its current applications, distantly supervised data is mostly used as a whole for pertaining, which is of low time efficiency. To fill in the gap of efficient and robust utilization of distantly supervised training data, we propose Efficient Multi-Supervision for document-level relation extraction, in which we first select a subset of informative documents from the massive dataset by combining distant supervision with expert supervision, then train the model with Multi-Supervision Ranking Loss that integrates the knowledge from multiple sources of supervision to alleviate the effects of noise. The experiments demonstrate the effectiveness of our method in improving the model performance with higher time efficiency than existing baselines.
Style Generation in Robot Calligraphy with Deep Generative Adversarial Networks
Dec 15, 2023



Robot calligraphy is an emerging exploration of artificial intelligence in the fields of art and education. Traditional calligraphy generation researches mainly focus on methods such as tool-based image processing, generative models, and style transfer. Unlike the English alphabet, the number of Chinese characters is tens of thousands, which leads to difficulties in the generation of a style consistent Chinese calligraphic font with over 6000 characters. Due to the lack of high-quality data sets, formal definitions of calligraphy knowledge, and scientific art evaluation methods, The results generated are frequently of low quality and falls short of professional-level requirements. To address the above problem, this paper proposes an automatic calligraphy generation model based on deep generative adversarial networks (deepGAN) that can generate style calligraphy fonts with professional standards. The key highlights of the proposed method include: (1) The datasets use a high-precision calligraphy synthesis method to ensure its high quality and sufficient quantity; (2) Professional calligraphers are invited to conduct a series of Turing tests to evaluate the gap between model generation results and human artistic level; (3) Experimental results indicate that the proposed model is the state-of-the-art among current calligraphy generation methods. The Turing tests and similarity evaluations validate the effectiveness of the proposed method.
From Cluster Assumption to Graph Convolution: Graph-based Semi-Supervised Learning Revisited
Sep 24, 2023
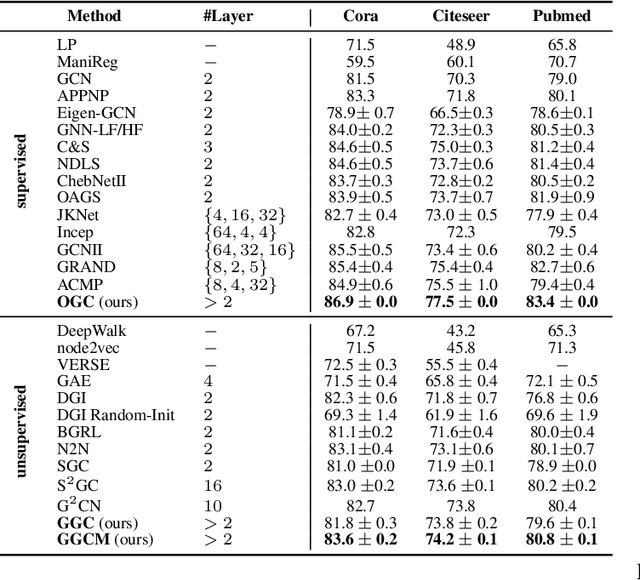


Graph-based semi-supervised learning (GSSL) has long been a hot research topic. Traditional methods are generally shallow learners, based on the cluster assumption. Recently, graph convolutional networks (GCNs) have become the predominant techniques for their promising performance. In this paper, we theoretically discuss the relationship between these two types of methods in a unified optimization framework. One of the most intriguing findings is that, unlike traditional ones, typical GCNs may not jointly consider the graph structure and label information at each layer. Motivated by this, we further propose three simple but powerful graph convolution methods. The first is a supervised method OGC which guides the graph convolution process with labels. The others are two unsupervised methods: GGC and its multi-scale version GGCM, both aiming to preserve the graph structure information during the convolution process. Finally, we conduct extensive experiments to show the effectiveness of our methods.
GraphSR: A Data Augmentation Algorithm for Imbalanced Node Classification
Feb 24, 2023



Graph neural networks (GNNs) have achieved great success in node classification tasks. However, existing GNNs naturally bias towards the majority classes with more labelled data and ignore those minority classes with relatively few labelled ones. The traditional techniques often resort over-sampling methods, but they may cause overfitting problem. More recently, some works propose to synthesize additional nodes for minority classes from the labelled nodes, however, there is no any guarantee if those generated nodes really stand for the corresponding minority classes. In fact, improperly synthesized nodes may result in insufficient generalization of the algorithm. To resolve the problem, in this paper we seek to automatically augment the minority classes from the massive unlabelled nodes of the graph. Specifically, we propose \textit{GraphSR}, a novel self-training strategy to augment the minority classes with significant diversity of unlabelled nodes, which is based on a Similarity-based selection module and a Reinforcement Learning(RL) selection module. The first module finds a subset of unlabelled nodes which are most similar to those labelled minority nodes, and the second one further determines the representative and reliable nodes from the subset via RL technique. Furthermore, the RL-based module can adaptively determine the sampling scale according to current training data. This strategy is general and can be easily combined with different GNNs models. Our experiments demonstrate the proposed approach outperforms the state-of-the-art baselines on various class-imbalanced datasets.
AIDA: Legal Judgment Predictions for Non-Professional Fact Descriptions via Partial-and-Imbalanced Domain Adaptation
Feb 12, 2023In this paper, we study the problem of legal domain adaptation problem from an imbalanced source domain to a partial target domain. The task aims to improve legal judgment predictions for non-professional fact descriptions. We formulate this task as a partial-and-imbalanced domain adaptation problem. Though deep domain adaptation has achieved cutting-edge performance in many unsupervised domain adaptation tasks. However, due to the negative transfer of samples in non-shared classes, it is hard for current domain adaptation model to solve the partial-and-imbalanced transfer problem. In this work, we explore large-scale non-shared but related classes data in the source domain with a hierarchy weighting adaptation to tackle this limitation. We propose to embed a novel pArtial Imbalanced Domain Adaptation technique (AIDA) in the deep learning model, which can jointly borrow sibling knowledge from non-shared classes to shared classes in the source domain and further transfer the shared classes knowledge from the source domain to the target domain. Experimental results show that our model outperforms the state-of-the-art algorithms.
NI-UDA: Graph Adversarial Domain Adaptation from Non-shared-and-Imbalanced Big Data to Small Imbalanced Applications
Aug 12, 2021

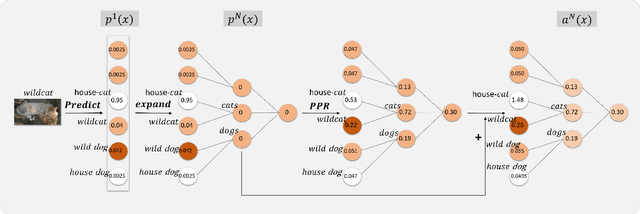

We propose a new general Graph Adversarial Domain Adaptation (GADA) based on semantic knowledge reasoning of class structure for solving the problem of unsupervised domain adaptation (UDA) from the big data with non-shared and imbalanced classes to specified small and imbalanced applications (NI-UDA), where non-shared classes mean the label space out of the target domain. Our goal is to leverage priori hierarchy knowledge to enhance domain adversarial aligned feature representation with graph reasoning. In this paper, to address two challenges in NI-UDA, we equip adversarial domain adaptation with Hierarchy Graph Reasoning (HGR) layer and the Source Classifier Filter (SCF). For sparse classes transfer challenge, our HGR layer can aggregate local feature to hierarchy graph nodes by node prediction and enhance domain adversarial aligned feature with hierarchy graph reasoning for sparse classes. Our HGR contributes to learn direct semantic patterns for sparse classes by hierarchy attention in self-attention, non-linear mapping and graph normalization. our SCF is proposed for the challenge of knowledge sharing from non-shared data without negative transfer effect by filtering low-confidence non-shared data in HGR layer. Experiments on two benchmark datasets show our GADA methods consistently improve the state-of-the-art adversarial UDA algorithms, e.g. GADA(HGR) can greatly improve f1 of the MDD by \textbf{7.19\%} and GVB-GD by \textbf{7.89\%} respectively on imbalanced source task in Meal300 dataset. The code is available at https://gadatransfer.wixsite.com/gada.
Recurrent Coupled Topic Modeling over Sequential Documents
Jun 23, 2021
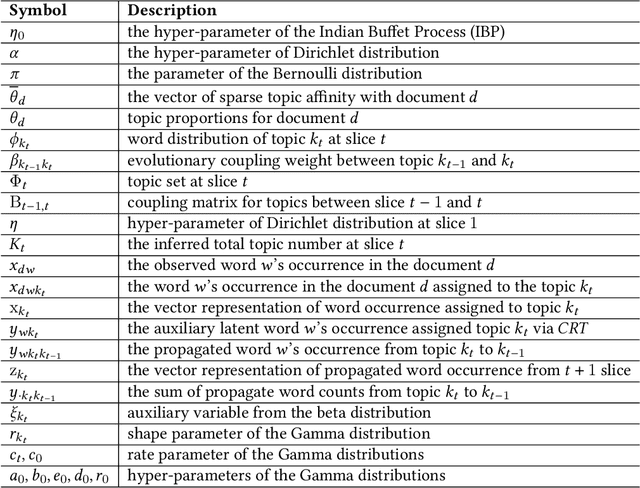


The abundant sequential documents such as online archival, social media and news feeds are streamingly updated, where each chunk of documents is incorporated with smoothly evolving yet dependent topics. Such digital texts have attracted extensive research on dynamic topic modeling to infer hidden evolving topics and their temporal dependencies. However, most of the existing approaches focus on single-topic-thread evolution and ignore the fact that a current topic may be coupled with multiple relevant prior topics. In addition, these approaches also incur the intractable inference problem when inferring latent parameters, resulting in a high computational cost and performance degradation. In this work, we assume that a current topic evolves from all prior topics with corresponding coupling weights, forming the multi-topic-thread evolution. Our method models the dependencies between evolving topics and thoroughly encodes their complex multi-couplings across time steps. To conquer the intractable inference challenge, a new solution with a set of novel data augmentation techniques is proposed, which successfully discomposes the multi-couplings between evolving topics. A fully conjugate model is thus obtained to guarantee the effectiveness and efficiency of the inference technique. A novel Gibbs sampler with a backward-forward filter algorithm efficiently learns latent timeevolving parameters in a closed-form. In addition, the latent Indian Buffet Process (IBP) compound distribution is exploited to automatically infer the overall topic number and customize the sparse topic proportions for each sequential document without bias. The proposed method is evaluated on both synthetic and real-world datasets against the competitive baselines, demonstrating its superiority over the baselines in terms of the low per-word perplexity, high coherent topics, and better document time prediction.
Zero-shot Node Classification with Decomposed Graph Prototype Network
Jun 15, 2021



Node classification is a central task in graph data analysis. Scarce or even no labeled data of emerging classes is a big challenge for existing methods. A natural question arises: can we classify the nodes from those classes that have never been seen? In this paper, we study this zero-shot node classification (ZNC) problem which has a two-stage nature: (1) acquiring high-quality class semantic descriptions (CSDs) for knowledge transfer, and (2) designing a well generalized graph-based learning model. For the first stage, we give a novel quantitative CSDs evaluation strategy based on estimating the real class relationships, so as to get the "best" CSDs in a completely automatic way. For the second stage, we propose a novel Decomposed Graph Prototype Network (DGPN) method, following the principles of locality and compositionality for zero-shot model generalization. Finally, we conduct extensive experiments to demonstrate the effectiveness of our solutions.
Expanding Semantic Knowledge for Zero-shot Graph Embedding
Mar 23, 2021
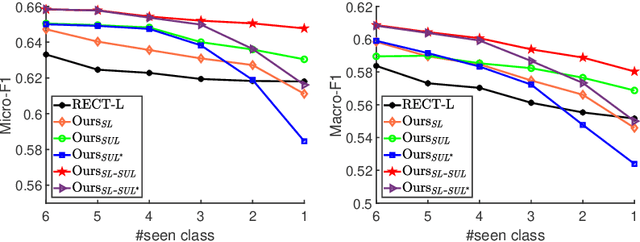
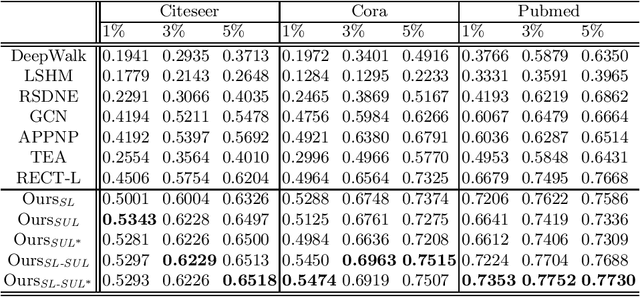
Zero-shot graph embedding is a major challenge for supervised graph learning. Although a recent method RECT has shown promising performance, its working mechanisms are not clear and still needs lots of training data. In this paper, we give deep insights into RECT, and address its fundamental limits. We show that its core part is a GNN prototypical model in which a class prototype is described by its mean feature vector. As such, RECT maps nodes from the raw-input feature space into an intermediate-level semantic space that connects the raw-input features to both seen and unseen classes. This mechanism makes RECT work well on both seen and unseen classes, which however also reduces the discrimination. To realize its full potentials, we propose two label expansion strategies. Specifically, besides expanding the labeled node set of seen classes, we can also expand that of unseen classes. Experiments on real-world datasets validate the superiority of our methods.