 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDA: Legal Judgment Predictions for Non-Professional Fact Descriptions via Partial-and-Imbalanced Domain Adaptation
Feb 12, 2023In this paper, we study the problem of legal domain adaptation problem from an imbalanced source domain to a partial target domain. The task aims to improve legal judgment predictions for non-professional fact descriptions. We formulate this task as a partial-and-imbalanced domain adaptation problem. Though deep domain adaptation has achieved cutting-edge performance in many unsupervised domain adaptation tasks. However, due to the negative transfer of samples in non-shared classes, it is hard for current domain adaptation model to solve the partial-and-imbalanced transfer problem. In this work, we explore large-scale non-shared but related classes data in the source domain with a hierarchy weighting adaptation to tackle this limitation. We propose to embed a novel pArtial Imbalanced Domain Adaptation technique (AIDA) in the deep learning model, which can jointly borrow sibling knowledge from non-shared classes to shared classes in the source domain and further transfer the shared classes knowledge from the source domain to the target domain. Experimental results show that our model outperforms the state-of-the-art algorithms.
Visual Spatio-Temporal Relation-Enhanced Network for Cross-Modal Text-Video Retrieval
Nov 20, 2021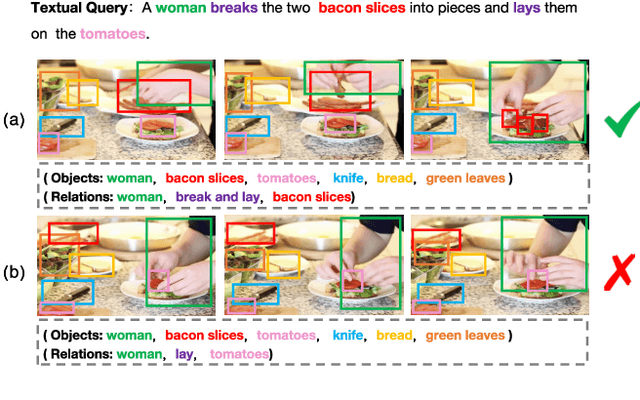
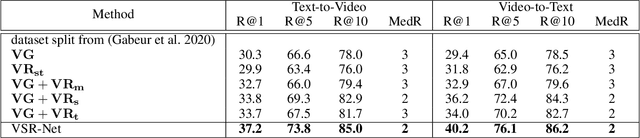
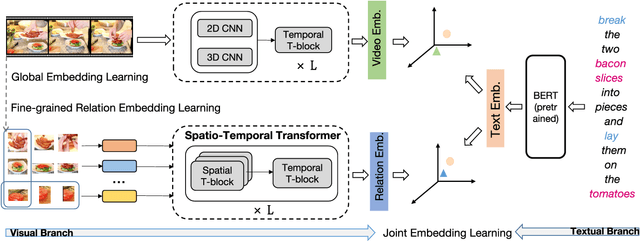
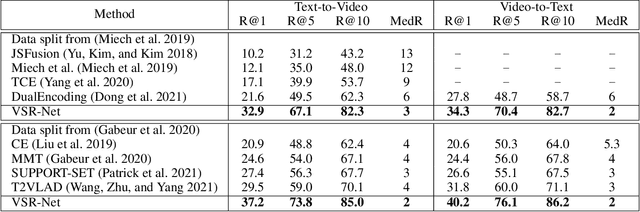
The task of cross-modal retrieval between texts and videos aims to understand the correspondence between vision and language. Existing studies follow a trend of measuring text-video similarity on the basis of textual and video embeddings. In common practice, video representation is constructed by feeding video frames into 2D/3D-CNN for global visual feature extraction or only learning simple semantic relations by using local-level fine-grained frame regions via graph convolutional network. However, these video representations do not fully exploit spatio-temporal relation among visual components in learning video representations, resulting in their inability to distinguish videos with the same visual components but with different relations. To solve this problem, we propose a Visual Spatio-Temporal Relation-Enhanced Network (VSR-Net), a novel cross-modal retrieval framework that considers the spatial-temporal visual relations among components to enhance global video representation in bridging text-video modalities. Specifically, visual spatio-temporal relations are encoded using a multi-layer spatio-temporal transformer to learn visual relational features. We align the global visual and fine-grained relational features with the text feature on two embedding spaces for cross-modal text-video retrieval. Extensive experimental are conducted on both MSR-VTT and MSVD datasets. The results demonstrate the effectiveness of our proposed model. We will release the code to facilitate future researches.
NI-UDA: Graph Adversarial Domain Adaptation from Non-shared-and-Imbalanced Big Data to Small Imbalanced Applications
Aug 12, 2021

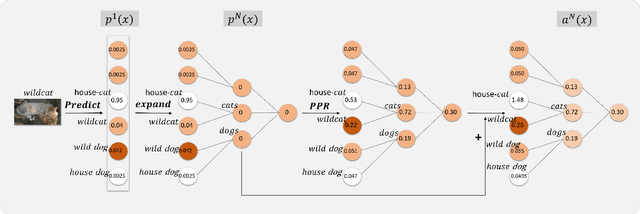

We propose a new general Graph Adversarial Domain Adaptation (GADA) based on semantic knowledge reasoning of class structure for solving the problem of unsupervised domain adaptation (UDA) from the big data with non-shared and imbalanced classes to specified small and imbalanced applications (NI-UDA), where non-shared classes mean the label space out of the target domain. Our goal is to leverage priori hierarchy knowledge to enhance domain adversarial aligned feature representation with graph reasoning. In this paper, to address two challenges in NI-UDA, we equip adversarial domain adaptation with Hierarchy Graph Reasoning (HGR) layer and the Source Classifier Filter (SCF). For sparse classes transfer challenge, our HGR layer can aggregate local feature to hierarchy graph nodes by node prediction and enhance domain adversarial aligned feature with hierarchy graph reasoning for sparse classes. Our HGR contributes to learn direct semantic patterns for sparse classes by hierarchy attention in self-attention, non-linear mapping and graph normalization. our SCF is proposed for the challenge of knowledge sharing from non-shared data without negative transfer effect by filtering low-confidence non-shared data in HGR layer. Experiments on two benchmark datasets show our GADA methods consistently improve the state-of-the-art adversarial UDA algorithms, e.g. GADA(HGR) can greatly improve f1 of the MDD by \textbf{7.19\%} and GVB-GD by \textbf{7.89\%} respectively on imbalanced source task in Meal300 dataset. The code is available at https://gadatransfer.wixsite.com/gada.