 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Sensitivity-Consistency Learning for Weakly Supervised Video Anomaly Detection
Mar 20, 2026Recent weakly supervised video anomaly detection methods have achieved significant advances by employing unified frameworks for joint optimization. However, this paradigm is limited by a fundamental sensitivity-stability trade-off, as the conflicting objectives for detecting transient and sustained anomalies lead to either fragmented predictions or over-smoothed responses. To address this limitation, we propose DeSC, a novel Decoupled Sensitivity-Consistency framework that trains two specialized streams using distinct optimization strategies. The temporal sensitivity stream adopts an aggressive optimization strategy to capture high-frequency abrupt changes, whereas the semantic consistency stream applies robust constraints to maintain long-term coherence and reduce noise. Their complementary strengths are fused through a collaborative inference mechanism that reduces individual biases and produces balanced predictions. Extensive experiments demonstrate that DeSC establishes new state-of-the-art performance by achieving 89.37% AUC on UCF-Crime (+1.29%) and 87.18% AP on XD-Violence (+2.22%). Code is available at https://github.com/imzht/DeSC.
GrOCE:Graph-Guided Online Concept Erasure for Text-to-Image Diffusion Models
Nov 17, 2025Concept erasure aims to remove harmful, inappropriate, or copyrighted content from text-to-image diffusion models while preserving non-target semantics. However, existing methods either rely on costly fine-tuning or apply coarse semantic separation, often degrading unrelated concepts and lacking adaptability to evolving concept sets. To alleviate this issue, we propose Graph-Guided Online Concept Erasure (GrOCE), a training-free framework that performs precise and adaptive concept removal through graph-based semantic reasoning. GrOCE models concepts and their interrelations as a dynamic semantic graph, enabling principled reasoning over dependencies and fine-grained isolation of undesired content. It comprises three components: (1) Dynamic Topological Graph Construction for incremental graph building, (2) Adaptive Cluster Identification for multi-hop traversal with similarity-decay scoring, and (3) Selective Edge Severing for targeted edge removal while preserving global semantics. Extensive experiments demonstrate that GrOCE achieves state-of-the-art performance on Concept Similarity (CS) and Fréchet Inception Distance (FID) metrics, offering efficient, accurate, and stable concept erasure without retraining.
Prescribed Performance Control of Deformable Object Manipulation in Spatial Latent Space
Oct 16, 2025Manipulating three-dimensional (3D) deformable objects presents significant challenges for robotic systems due to their infinite-dimensional state space and complex deformable dynamics. This paper proposes a novel model-free approach for shape control with constraints imposed on key points. Unlike existing methods that rely on feature dimensionality reduction, the proposed controller leverages the coordinates of key points as the feature vector, which are extracted from the deformable object's point cloud using deep learning methods. This approach not only reduces the dimensionality of the feature space but also retains the spatial information of the object. By extracting key points, the manipulation of deformable objects is simplified into a visual servoing problem, where the shape dynamics are described using a deformation Jacobian matrix. To enhance control accuracy, a prescribed performance control method is developed by integrating barrier Lyapunov functions (BLF) to enforce constraints on the key points. The stability of the closed-loop system is rigorously analyzed and verified using the Lyapunov method. Experimental results further demonstrate the effectiveness and robustness of the proposed method.
Efficient Cross-Modal Video Retrieval with Meta-Optimized Frames
Oct 16, 2022
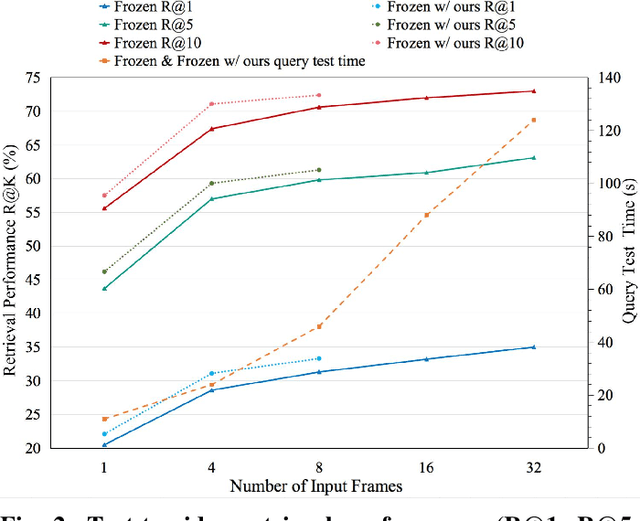
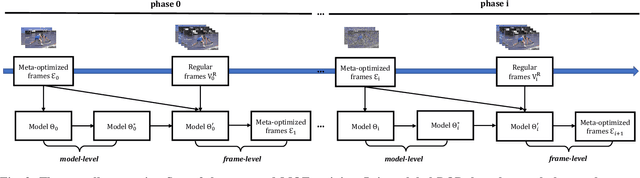
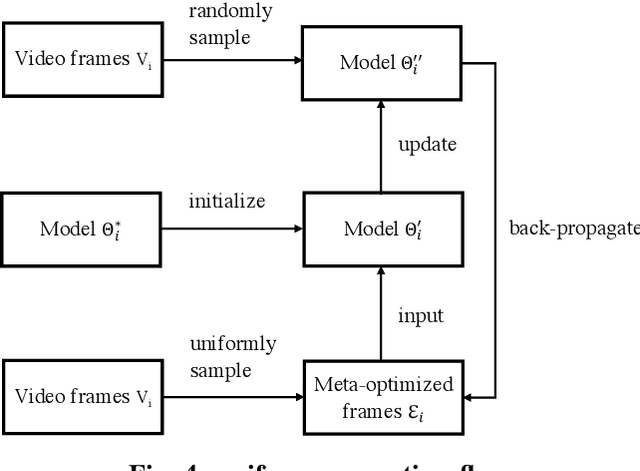
Cross-modal video retrieval aims to retrieve the semantically relevant videos given a text as a query, and is one of the fundamental tasks in Multimedia. Most of top-performing methods primarily leverage Visual Transformer (ViT) to extract video features [1, 2, 3], suffering from high computational complexity of ViT especially for encoding long videos. A common and simple solution is to uniformly sample a small number (say, 4 or 8) of frames from the video (instead of using the whole video) as input to ViT. The number of frames has a strong influence on the performance of ViT, e.g., using 8 frames performs better than using 4 frames yet needs more computational resources, resulting in a trade-off. To get free from this trade-off, this paper introduces an automatic video compression method based on a bilevel optimization program (BOP) consisting of both model-level (i.e., base-level) and frame-level (i.e., meta-level) optimizations. The model-level learns a cross-modal video retrieval model whose input is the "compressed frames" learned by frame-level optimization. In turn, the frame-level optimization is through gradient descent using the meta loss of video retrieval model computed on the whole video. We call this BOP method as well as the "compressed frames" as Meta-Optimized Frames (MOF). By incorporating MOF, the video retrieval model is able to utilize the information of whole videos (for training) while taking only a small number of input frames in actual implementation. The convergence of MOF is guaranteed by meta gradient descent algorithms. For evaluation, we conduct extensive experiments of cross-modal video retrieval on three large-scale benchmarks: MSR-VTT, MSVD, and DiDeMo. Our results show that MOF is a generic and efficient method to boost multiple baseline methods, and can achieve a new state-of-the-art performance.
Visual Spatio-Temporal Relation-Enhanced Network for Cross-Modal Text-Video Retrieval
Nov 20, 2021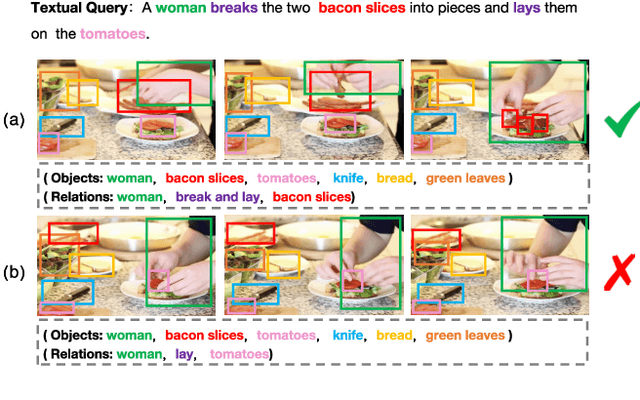
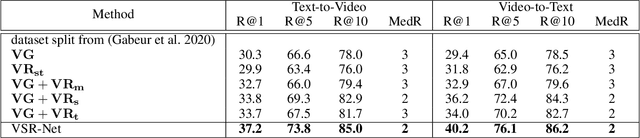
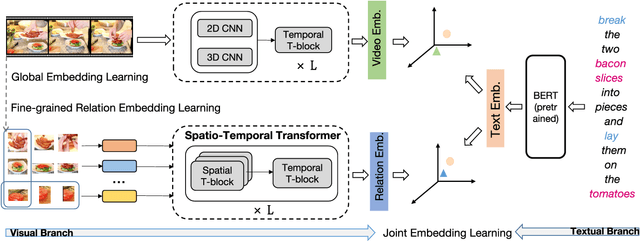
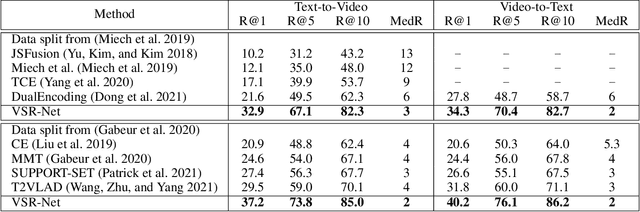
The task of cross-modal retrieval between texts and videos aims to understand the correspondence between vision and language. Existing studies follow a trend of measuring text-video similarity on the basis of textual and video embeddings. In common practice, video representation is constructed by feeding video frames into 2D/3D-CNN for global visual feature extraction or only learning simple semantic relations by using local-level fine-grained frame regions via graph convolutional network. However, these video representations do not fully exploit spatio-temporal relation among visual components in learning video representations, resulting in their inability to distinguish videos with the same visual components but with different relations. To solve this problem, we propose a Visual Spatio-Temporal Relation-Enhanced Network (VSR-Net), a novel cross-modal retrieval framework that considers the spatial-temporal visual relations among components to enhance global video representation in bridging text-video modalities. Specifically, visual spatio-temporal relations are encoded using a multi-layer spatio-temporal transformer to learn visual relational features. We align the global visual and fine-grained relational features with the text feature on two embedding spaces for cross-modal text-video retrieval. Extensive experimental are conducted on both MSR-VTT and MSVD datasets. The results demonstrate the effectiveness of our proposed model. We will release the code to facilitate future researches.