 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Spatio-Temporal Relation-Enhanced Network for Cross-Modal Text-Video Retrieval
Paper and Code
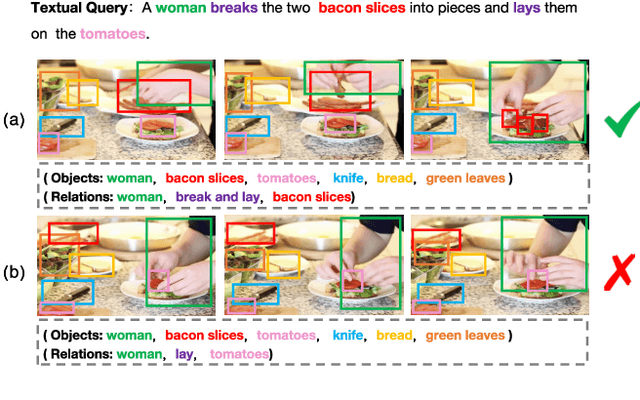
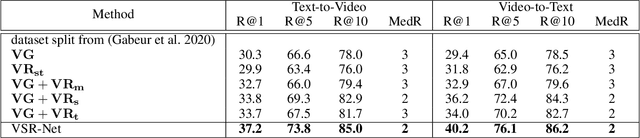
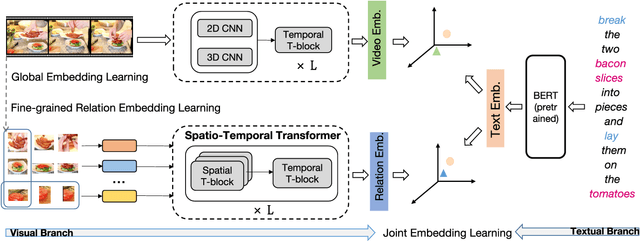
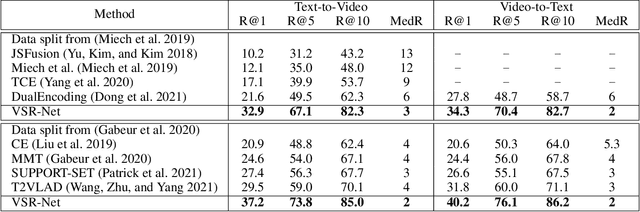
The task of cross-modal retrieval between texts and videos aims to understand the correspondence between vision and language. Existing studies follow a trend of measuring text-video similarity on the basis of textual and video embeddings. In common practice, video representation is constructed by feeding video frames into 2D/3D-CNN for global visual feature extraction or only learning simple semantic relations by using local-level fine-grained frame regions via graph convolutional network. However, these video representations do not fully exploit spatio-temporal relation among visual components in learning video representations, resulting in their inability to distinguish videos with the same visual components but with different relations. To solve this problem, we propose a Visual Spatio-Temporal Relation-Enhanced Network (VSR-Net), a novel cross-modal retrieval framework that considers the spatial-temporal visual relations among components to enhance global video representation in bridging text-video modalities. Specifically, visual spatio-temporal relations are encoded using a multi-layer spatio-temporal transformer to learn visual relational features. We align the global visual and fine-grained relational features with the text feature on two embedding spaces for cross-modal text-video retrieval. Extensive experimental are conducted on both MSR-VTT and MSVD datasets. The results demonstrate the effectiveness of our proposed model. We will release the code to facilitate future researches.