 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Modal Video Retrieval with Meta-Optimized Frames
Paper and Code

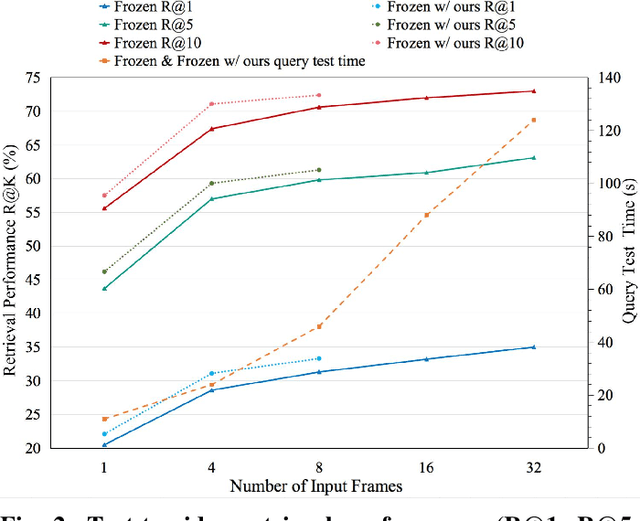
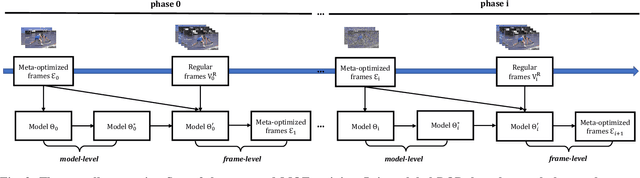
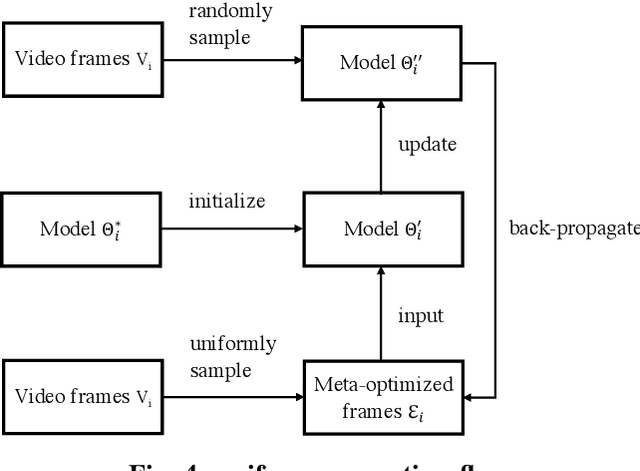
Cross-modal video retrieval aims to retrieve the semantically relevant videos given a text as a query, and is one of the fundamental tasks in Multimedia. Most of top-performing methods primarily leverage Visual Transformer (ViT) to extract video features [1, 2, 3], suffering from high computational complexity of ViT especially for encoding long videos. A common and simple solution is to uniformly sample a small number (say, 4 or 8) of frames from the video (instead of using the whole video) as input to ViT. The number of frames has a strong influence on the performance of ViT, e.g., using 8 frames performs better than using 4 frames yet needs more computational resources, resulting in a trade-off. To get free from this trade-off, this paper introduces an automatic video compression method based on a bilevel optimization program (BOP) consisting of both model-level (i.e., base-level) and frame-level (i.e., meta-level) optimizations. The model-level learns a cross-modal video retrieval model whose input is the "compressed frames" learned by frame-level optimization. In turn, the frame-level optimization is through gradient descent using the meta loss of video retrieval model computed on the whole video. We call this BOP method as well as the "compressed frames" as Meta-Optimized Frames (MOF). By incorporating MOF, the video retrieval model is able to utilize the information of whole videos (for training) while taking only a small number of input frames in actual implementation. The convergence of MOF is guaranteed by meta gradient descent algorithms. For evaluation, we conduct extensive experiments of cross-modal video retrieval on three large-scale benchmarks: MSR-VTT, MSVD, and DiDeMo. Our results show that MOF is a generic and efficient method to boost multiple baseline methods, and can achieve a new state-of-the-art performance.