 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrad2Reward: From Sparse Judgment to Dense Rewards for Improving Open-Ended LLM Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed significant breakthroughs in complex LLM reasoning within verifiable domains, such as mathematics and programming. Recent efforts have sought to extend this paradigm to open-ended tasks by employing LLMs-as-a-Judge to provide sequence-level rewards for policy optimization. However, these rewards are inherently sparse, failing to provide the fine-grained supervision necessary for generating complex, long-form trajectories. Furthermore, current work treats the Judge as a black-box oracle, discarding the rich intermediate feedback signals encoded in it. To address these limitations, we introduce Grad2Reward, a novel framework that extracts dense process rewards directly from the Judge's model inference process via a single backward pass. By leveraging gradient-based attribution, Grad2Reward enables precise token-level credit assignment, substantially enhancing training efficiency and reasoning quality. Additionally, Grad2Reward introduces a self-judging mechanism, allowing the policy to improve through its own evaluative signals without training specialized reward models or reliance on superior external Judges. The experiments demonstrate that policies optimized with Grad2Reward achieve outstanding performance across diverse open-ended tasks, affirming its effectiveness and broad generalizability.
Recurrent Coupled Topic Modeling over Sequential Documents
Jun 23, 2021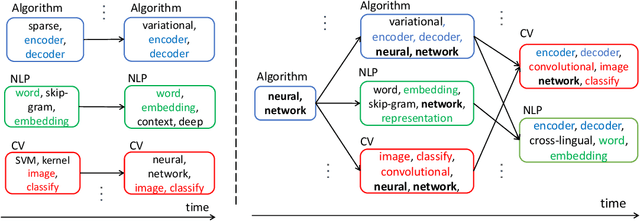
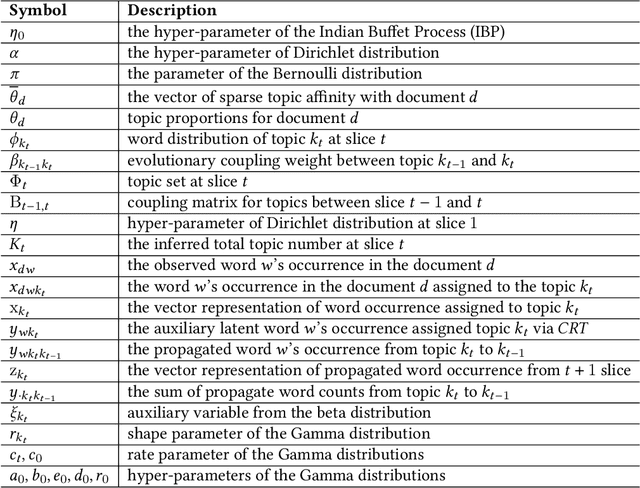


The abundant sequential documents such as online archival, social media and news feeds are streamingly updated, where each chunk of documents is incorporated with smoothly evolving yet dependent topics. Such digital texts have attracted extensive research on dynamic topic modeling to infer hidden evolving topics and their temporal dependencies. However, most of the existing approaches focus on single-topic-thread evolution and ignore the fact that a current topic may be coupled with multiple relevant prior topics. In addition, these approaches also incur the intractable inference problem when inferring latent parameters, resulting in a high computational cost and performance degradation. In this work, we assume that a current topic evolves from all prior topics with corresponding coupling weights, forming the multi-topic-thread evolution. Our method models the dependencies between evolving topics and thoroughly encodes their complex multi-couplings across time steps. To conquer the intractable inference challenge, a new solution with a set of novel data augmentation techniques is proposed, which successfully discomposes the multi-couplings between evolving topics. A fully conjugate model is thus obtained to guarantee the effectiveness and efficiency of the inference technique. A novel Gibbs sampler with a backward-forward filter algorithm efficiently learns latent timeevolving parameters in a closed-form. In addition, the latent Indian Buffet Process (IBP) compound distribution is exploited to automatically infer the overall topic number and customize the sparse topic proportions for each sequential document without bias. The proposed method is evaluated on both synthetic and real-world datasets against the competitive baselines, demonstrating its superiority over the baselines in terms of the low per-word perplexity, high coherent topics, and better document time prediction.