 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Approach to Multilingual E-Commerce Product Search: Case Study on Query-Category and Query-Item Relevance
Oct 24, 2025Multilingual e-commerce search suffers from severe data imbalance across languages, label noise, and limited supervision for low-resource languages--challenges that impede the cross-lingual generalization of relevance models despite the strong capabilities of large language models (LLMs). In this work, we present a practical, architecture-agnostic, data-centric framework to enhance performance on two core tasks: Query-Category (QC) relevance (matching queries to product categories) and Query-Item (QI) relevance (matching queries to product titles). Rather than altering the model, we redesign the training data through three complementary strategies: (1) translation-based augmentation to synthesize examples for languages absent in training, (2) semantic negative sampling to generate hard negatives and mitigate class imbalance, and (3) self-validation filtering to detect and remove likely mislabeled instances. Evaluated on the CIKM AnalytiCup 2025 dataset, our approach consistently yields substantial F1 score improvements over strong LLM baselines, achieving competitive results in the official competition. Our findings demonstrate that systematic data engineering can be as impactful as--and often more deployable than--complex model modifications, offering actionable guidance for building robust multilingual search systems in the real-world e-commerce settings.
USTC-KXDIGIT System Description for ASVspoof5 Challenge
Sep 03, 2024
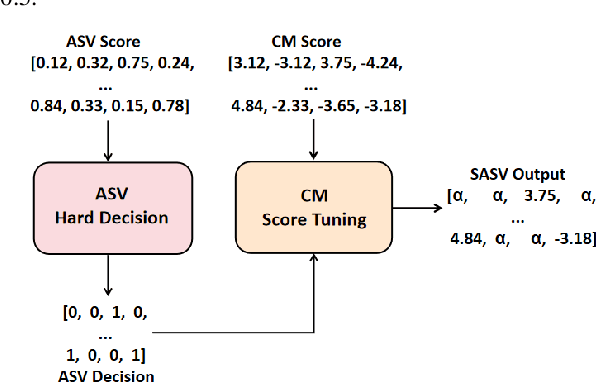
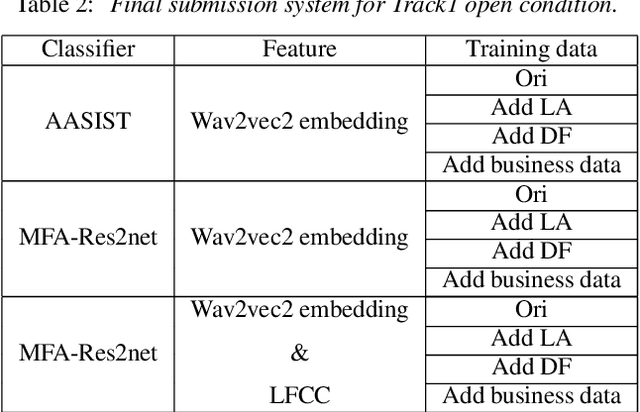
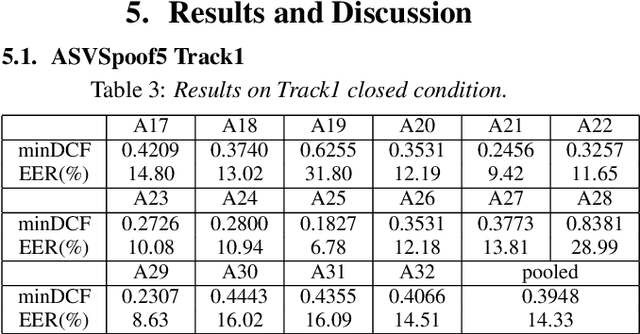
This paper describes the USTC-KXDIGIT system submitted to the ASVspoof5 Challenge for Track 1 (speech deepfake detection) and Track 2 (spoofing-robust automatic speaker verification, SASV). Track 1 showcases a diverse range of technical qualities from potential processing algorithms and includes both open and closed conditions. For these conditions, our system consists of a cascade of a frontend feature extractor and a back-end classifier. We focus on extensive embedding engineering and enhancing the generalization of the back-end classifier model. Specifically, the embedding engineering is based on hand-crafted features and speech representations from a self-supervised model, used for closed and open conditions, respectively. To detect spoof attacks under various adversarial conditions, we trained multiple systems on an augmented training set. Additionally, we used voice conversion technology to synthesize fake audio from genuine audio in the training set to enrich the synthesis algorithms. To leverage the complementary information learned by different model architectures, we employed activation ensemble and fused scores from different systems to obtain the final decision score for spoof detection. During the evaluation phase, the proposed methods achieved 0.3948 minDCF and 14.33% EER in the close condition, and 0.0750 minDCF and 2.59% EER in the open condition, demonstrating the robustness of our submitted systems under adversarial conditions. In Track 2, we continued using the CM system from Track 1 and fused it with a CNN-based ASV system. This approach achieved 0.2814 min-aDCF in the closed condition and 0.0756 min-aDCF in the open condition, showcasing superior performance in the SASV system.
Causal-Aware Graph Neural Architecture Search under Distribution Shifts
May 26, 2024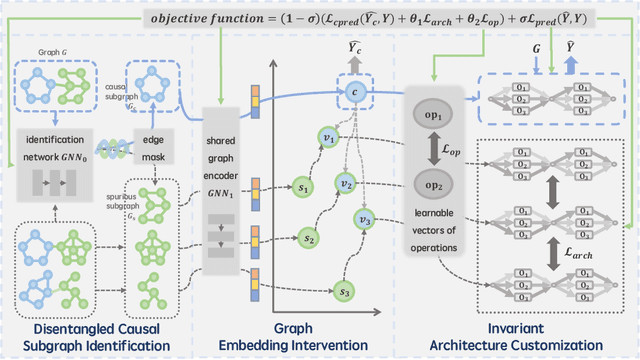
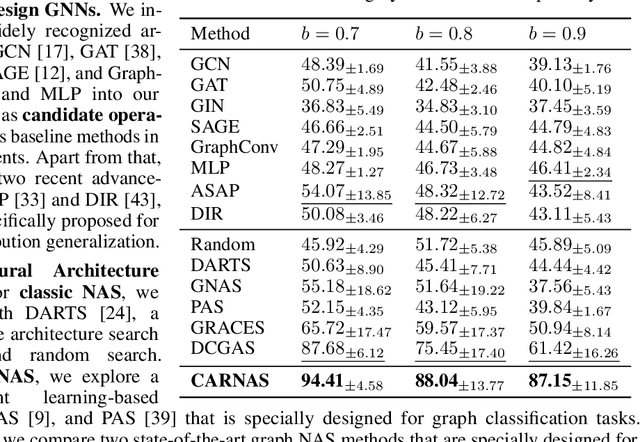
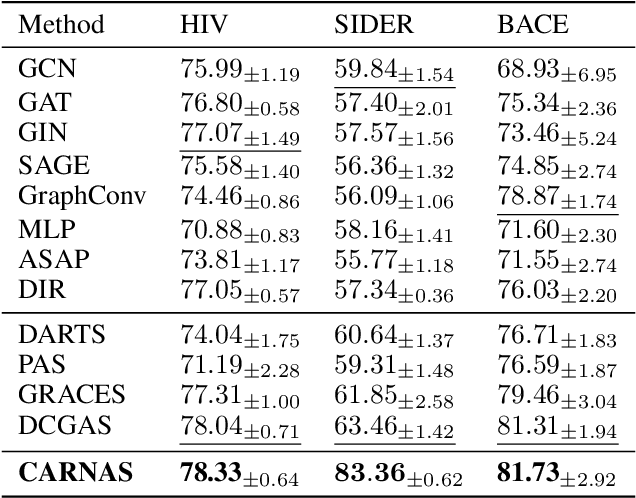
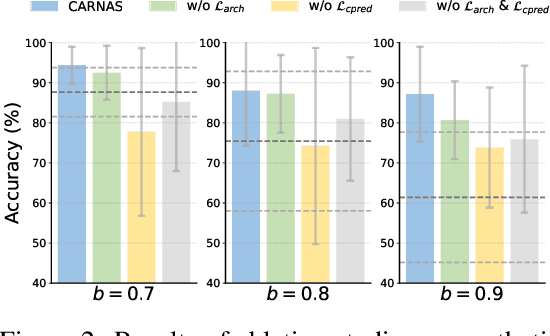
Graph NAS has emerged as a promising approach for autonomously designing GNN architectures by leveraging the correlations between graphs and architectures. Existing methods fail to generalize under distribution shifts that are ubiquitous in real-world graph scenarios, mainly because the graph-architecture correlations they exploit might be spurious and varying across distributions. We propose to handle the distribution shifts in the graph architecture search process by discovering and exploiting the causal relationship between graphs and architectures to search for the optimal architectures that can generalize under distribution shifts. The problem remains unexplored with following challenges: how to discover the causal graph-architecture relationship that has stable predictive abilities across distributions, and how to handle distribution shifts with the discovered causal graph-architecture relationship to search the generalized graph architectures. To address these challenges, we propose Causal-aware Graph Neural Architecture Search (CARNAS), which is able to capture the causal graph-architecture relationship during the architecture search process and discover the generalized graph architecture under distribution shifts. Specifically, we propose Disentangled Causal Subgraph Identification to capture the causal subgraphs that have stable prediction abilities across distributions. Then, we propose Graph Embedding Intervention to intervene on causal subgraphs within the latent space, ensuring that these subgraphs encapsulate essential features for prediction while excluding non-causal elements. Additionally, we propose Invariant Architecture Customization to reinforce the causal invariant nature of the causal subgraphs, which are utilized to tailor generalized graph architectures. Extensive experiments demonstrate that CARNAS achieves advanced out-of-distribution generalization ability.
LLM-Enhanced Causal Discovery in Temporal Domain from Interventional Data
Apr 23, 2024In the field of Artificial Intelligence for Information Technology Operations, causal discovery is pivotal for operation and maintenance of graph construction, facilitating downstream industrial tasks such as root cause analysis. Temporal causal discovery, as an emerging method, aims to identify temporal causal relationships between variables directly from observations by utilizing interventional data. However, existing methods mainly focus on synthetic datasets with heavy reliance on intervention targets and ignore the textual information hidden in real-world systems, failing to conduct causal discovery for real industrial scenarios. To tackle this problem, in this paper we propose to investigate temporal causal discovery in industrial scenarios, which faces two critical challenges: 1) how to discover causal relationships without the interventional targets that are costly to obtain in practice, and 2) how to discover causal relations via leveraging the textual information in systems which can be complex yet abundant in industrial contexts. To address these challenges, we propose the RealTCD framework, which is able to leverage domain knowledge to discover temporal causal relationships without interventional targets. Specifically, we first develop a score-based temporal causal discovery method capable of discovering causal relations for root cause analysis without relying on interventional targets through strategic masking and regularization. Furthermore, by employing Large Language Models (LLMs) to handle texts and integrate domain knowledge, we introduce LLM-guided meta-initialization to extract the meta-knowledge from textual information hidden in systems to boost the quality of discovery. We conduct extensive experiments on simulation and real-world datasets to show the superiority of our proposed RealTCD framework over existing baselines in discovering temporal causal structures.
The SpeakIn Speaker Verification System for Far-Field Speaker Verification Challenge 2022
Sep 23, 2022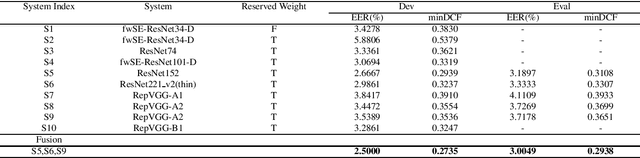
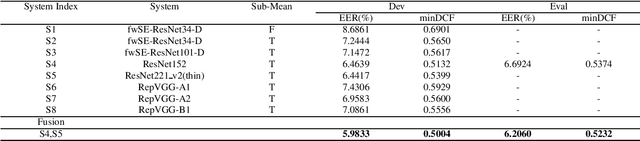
This paper describes speaker verification (SV) systems submitted by the SpeakIn team to the Task 1 and Task 2 of the Far-Field Speaker Verification Challenge 2022 (FFSVC2022). SV tasks of the challenge focus on the problem of fully supervised far-field speaker verification (Task 1) and semi-supervised far-field speaker verification (Task 2). In Task 1, we used the VoxCeleb and FFSVC2020 datasets as train datasets. And for Task 2, we only used the VoxCeleb dataset as train set. The ResNet-based and RepVGG-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax to classify the resulting embeddings. We innovatively propose a staged transfer learning method. In the pre-training stage we reserve the speaker weights, and there are no positive samples to train them in this stage. Then we fine-tune these weights with both positive and negative samples in the second stage. Compared with the traditional transfer learning strategy, this strategy can better improve the model performance. The Sub-Mean and AS-Norm backend methods were used to solve the problem of domain mismatch. In the fusion stage, three models were fused in Task1 and two models were fused in Task2. On the FFSVC2022 leaderboard, the EER of our submission is 3.0049% and the corresponding minDCF is 0.2938 in Task1. In Task2, EER and minDCF are 6.2060% and 0.5232 respectively. Our approach leads to excellent performance and ranks 1st in both challenge tasks.
Intelligent wayfinding vehicle design based on visual recognition
Sep 21, 2022Intelligent drug delivery trolley is an advanced intelligent drug delivery equipment. Compared with traditional manual drug delivery, it has higher drug delivery efficiency and lower error rate. In this project, an intelligent drug delivery car is designed and manufactured, which can recognize the road route and the room number of the target ward through visual recognition technology. The trolley selects the corresponding route according to the identified room number, accurately transports the drugs to the target ward, and can return to the pharmacy after the drugs are delivered. The intelligent drug delivery car uses DC power supply, and the motor drive module controls two DC motors, which overcomes the problem of excessive deviation of turning angle. The trolley line inspection function uses closed-loop control to improve the accuracy of line inspection and the controllability of trolley speed. The identification of ward number is completed by the camera module with microcontroller, and has the functions of adaptive adjustment of ambient brightness, distortion correction, automatic calibration and so on. The communication between two cooperative drug delivery vehicles is realized by Bluetooth module, which achieves efficient and accurate communication and interaction. Experiments show that the intelligent drug delivery car can accurately identify the room number and plan the route to deliver drugs to the far, middle and near wards, and has the characteristics of fast speed and accurate judgment. In addition, two drug delivery trolleys can cooperate to deliver drugs to the same ward, with high efficiency and high cooperation.
Zero-shot Node Classification with Decomposed Graph Prototype Network
Jun 15, 2021



Node classification is a central task in graph data analysis. Scarce or even no labeled data of emerging classes is a big challenge for existing methods. A natural question arises: can we classify the nodes from those classes that have never been seen? In this paper, we study this zero-shot node classification (ZNC) problem which has a two-stage nature: (1) acquiring high-quality class semantic descriptions (CSDs) for knowledge transfer, and (2) designing a well generalized graph-based learning model. For the first stage, we give a novel quantitative CSDs evaluation strategy based on estimating the real class relationships, so as to get the "best" CSDs in a completely automatic way. For the second stage, we propose a novel Decomposed Graph Prototype Network (DGPN) method, following the principles of locality and compositionality for zero-shot model generalization. Finally, we conduct extensive experiments to demonstrate the effectiveness of our solutions.
PL-VINS: Real-Time Monocular Visual-Inertial SLAM with Point and Line Features
Oct 11, 2020
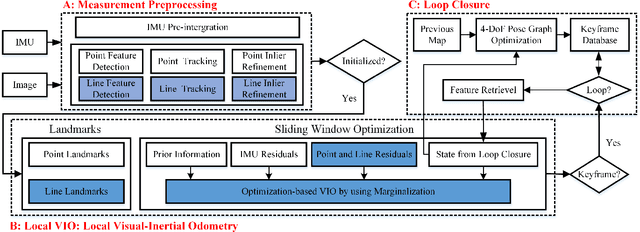

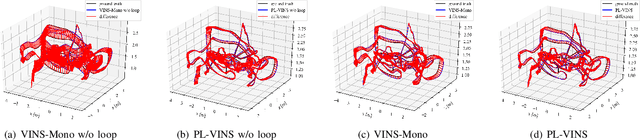
Leveraging line features to improve localization accuracy of point-based visual-inertial SLAM (VINS) is gaining interest as they provide additional constraints on scene structure. However, real-time performance when incorporating line features in VINS has not been addressed. This paper presents PL-VINS, a real-time optimization-based monocular VINS method with point and line features, developed based on the state-of-the-art point-based VINS-Mono \cite{vins}. We observe that current works use the LSD \cite{lsd} algorithm to extract line features; however, LSD is designed for scene shape representation instead of the pose estimation problem, which becomes the bottleneck for the real-time performance due to its high computational cost. In this paper, a modified LSD algorithm is presented by studying a hidden parameter tuning and length rejection strategy. The modified LSD can run at least three times as fast as LSD. Further, by representing space lines with the Pl\"{u}cker coordinates, the residual error in line estimation is modeled in terms of the point-to-line distance, which is then minimized by iteratively updating the minimum four-parameter orthonormal representation of the Pl\"{u}cker coordinates. Experiments in a public benchmark dataset show that the localization error of our method is 12-16\% less than that of VINS-Mono at the same pose update frequency. %For the benefit of the community, The source code of our method is available at: https://github.com/cnqiangfu/PL-VINS.