 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRzenEmbed: Towards Comprehensive Multimodal Retrieval
Oct 31, 2025The rapid advancement of Multimodal Large Language Models (MLLMs) has extended CLIP-based frameworks to produce powerful, universal embeddings for retrieval tasks. However, existing methods primarily focus on natural images, offering limited support for other crucial visual modalities such as videos and visual documents. To bridge this gap, we introduce RzenEmbed, a unified framework to learn embeddings across a diverse set of modalities, including text, images, videos, and visual documents. We employ a novel two-stage training strategy to learn discriminative representations. The first stage focuses on foundational text and multimodal retrieval. In the second stage, we introduce an improved InfoNCE loss, incorporating two key enhancements. Firstly, a hardness-weighted mechanism guides the model to prioritize challenging samples by assigning them higher weights within each batch. Secondly, we implement an approach to mitigate the impact of false negatives and alleviate data noise. This strategy not only enhances the model's discriminative power but also improves its instruction-following capabilities. We further boost performance with learnable temperature parameter and model souping. RzenEmbed sets a new state-of-the-art on the MMEB benchmark. It not only achieves the best overall score but also outperforms all prior work on the challenging video and visual document retrieval tasks. Our models are available in https://huggingface.co/qihoo360/RzenEmbed.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
UNISOUND System for VoxCeleb Speaker Recognition Challenge 2023
Aug 24, 2023


This report describes the UNISOUND submission for Track1 and Track2 of VoxCeleb Speaker Recognition Challenge 2023 (VoxSRC 2023). We submit the same system on Track 1 and Track 2, which is trained with only VoxCeleb2-dev. Large-scale ResNet and RepVGG architectures are developed for the challenge. We propose a consistency-aware score calibration method, which leverages the stability of audio voiceprints in similarity score by a Consistency Measure Factor (CMF). CMF brings a huge performance boost in this challenge. Our final system is a fusion of six models and achieves the first place in Track 1 and second place in Track 2 of VoxSRC 2023. The minDCF of our submission is 0.0855 and the EER is 1.5880%.
The SpeakIn Speaker Verification System for Far-Field Speaker Verification Challenge 2022
Sep 23, 2022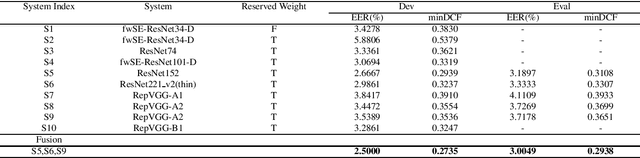
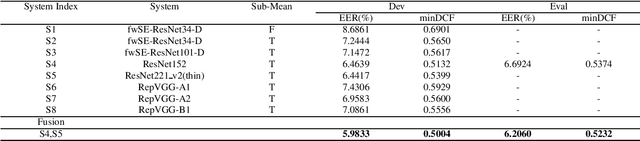
This paper describes speaker verification (SV) systems submitted by the SpeakIn team to the Task 1 and Task 2 of the Far-Field Speaker Verification Challenge 2022 (FFSVC2022). SV tasks of the challenge focus on the problem of fully supervised far-field speaker verification (Task 1) and semi-supervised far-field speaker verification (Task 2). In Task 1, we used the VoxCeleb and FFSVC2020 datasets as train datasets. And for Task 2, we only used the VoxCeleb dataset as train set. The ResNet-based and RepVGG-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax to classify the resulting embeddings. We innovatively propose a staged transfer learning method. In the pre-training stage we reserve the speaker weights, and there are no positive samples to train them in this stage. Then we fine-tune these weights with both positive and negative samples in the second stage. Compared with the traditional transfer learning strategy, this strategy can better improve the model performance. The Sub-Mean and AS-Norm backend methods were used to solve the problem of domain mismatch. In the fusion stage, three models were fused in Task1 and two models were fused in Task2. On the FFSVC2022 leaderboard, the EER of our submission is 3.0049% and the corresponding minDCF is 0.2938 in Task1. In Task2, EER and minDCF are 6.2060% and 0.5232 respectively. Our approach leads to excellent performance and ranks 1st in both challenge tasks.
The SpeakIn System Description for CNSRC2022
Sep 22, 2022


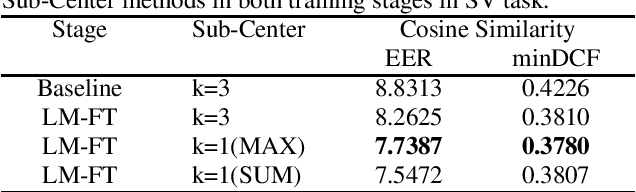
This report describes our speaker verification systems for the tasks of the CN-Celeb Speaker Recognition Challenge 2022 (CNSRC 2022). This challenge includes two tasks, namely speaker verification(SV) and speaker retrieval(SR). The SV task involves two tracks: fixed track and open track. In the fixed track, we only used CN-Celeb.T as the training set. For the open track of the SV task and SR task, we added our open-source audio data. The ResNet-based, RepVGG-based, and TDNN-based architectures were developed for this challenge. Global statistic pooling structure and MQMHA pooling structure were used to aggregate the frame-level features across time to obtain utterance-level representation. We adopted AM-Softmax and AAM-Softmax combined with the Sub-Center method to classify the resulting embeddings. We also used the Large-Margin Fine-Tuning strategy to further improve the model performance. In the backend, Sub-Mean and AS-Norm were used. In the SV task fixed track, our system was a fusion of five models, and two models were fused in the SV task open track. And we used a single system in the SR task. Our approach leads to superior performance and comes the 1st place in the open track of the SV task, the 2nd place in the fixed track of the SV task, and the 3rd place in the SR task.