 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-KGGen: A Skill-Driven Knowledge Extractor for High-Quality Knowledge Hypergraph Generation
Feb 23, 2026Knowledge hypergraphs surpass traditional binary knowledge graphs by encapsulating complex $n$-ary atomic facts, providing a more comprehensive paradigm for semantic representation. However, constructing high-quality hypergraphs remains challenging due to the \textit{scenario gap}: generic extractors struggle to generalize across diverse domains with specific jargon, while existing methods often fail to balance structural skeletons with fine-grained details. To bridge this gap, we propose \textbf{Hyper-KGGen}, a skill-driven framework that reformulates extraction as a dynamic skill-evolving process. First, Hyper-KGGen employs a \textit{coarse-to-fine} mechanism to systematically decompose documents, ensuring full-dimensional coverage from binary links to complex hyperedges. Crucially, it incorporates an \textit{adaptive skill acquisition} module that actively distills domain expertise into a Global Skill Library. This is achieved via a stability-based feedback loop, where extraction stability serves as a relative reward signal to induce high-quality skills from unstable traces and missed predictions. Additionally, we present \textbf{HyperDocRED}, a rigorously annotated benchmark for document-level knowledge hypergraph extraction. Experiments demonstrate that Hyper-KGGen significantly outperforms strong baselines, validating that evolved skills provide substantially richer guidance than static few-shot examples in multi-scenario settings.
Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
Nov 17, 2025Retrieval-Augmented Generation (RAG) enhances the response quality and domain-specific performance of large language models (LLMs) by incorporating external knowledge to combat hallucinations. In recent research, graph structures have been integrated into RAG to enhance the capture of semantic relations between entities. However, it primarily focuses on low-order pairwise entity relations, limiting the high-order associations among multiple entities. Hypergraph-enhanced approaches address this limitation by modeling multi-entity interactions via hyperedges, but they are typically constrained to inter-chunk entity-level representations, overlooking the global thematic organization and alignment across chunks. Drawing inspiration from the top-down cognitive process of human reasoning, we propose a theme-aligned dual-hypergraph RAG framework (Cog-RAG) that uses a theme hypergraph to capture inter-chunk thematic structure and an entity hypergraph to model high-order semantic relations. Furthermore, we design a cognitive-inspired two-stage retrieval strategy that first activates query-relevant thematic content from the theme hypergraph, and then guides fine-grained recall and diffusion in the entity hypergraph, achieving semantic alignment and consistent generation from global themes to local details. Our extensive experiments demonstrate that Cog-RAG significantly outperforms existing state-of-the-art baseline approaches.
* Accepted by AAAI 2026 main conference
Hypergraph Foundation Model
Mar 03, 2025



Hypergraph neural networks (HGNNs) effectively model complex high-order relationships in domains like protein interactions and social networks by connecting multiple vertices through hyperedges, enhancing modeling capabilities, and reducing information loss. Developing foundation models for hypergraphs is challenging due to their distinct data, which includes both vertex features and intricate structural information. We present Hyper-FM, a Hypergraph Foundation Model for multi-domain knowledge extraction, featuring Hierarchical High-Order Neighbor Guided Vertex Knowledge Embedding for vertex feature representation and Hierarchical Multi-Hypergraph Guided Structural Knowledge Extraction for structural information. Additionally, we curate 10 text-attributed hypergraph datasets to advance research between HGNNs and LLMs. Experiments on these datasets show that Hyper-FM outperforms baseline methods by approximately 13.3\%, validating our approach. Furthermore, we propose the first scaling law for hypergraph foundation models, demonstrating that increasing domain diversity significantly enhances performance, unlike merely augmenting vertex and hyperedge counts. This underscores the critical role of domain diversity in scaling hypergraph models.
FFA Sora, video generation as fundus fluorescein angiography simulator
Dec 23, 2024



Fundus fluorescein angiography (FFA) is critical for diagnosing retinal vascular diseases, but beginners often struggle with image interpretation. This study develops FFA Sora, a text-to-video model that converts FFA reports into dynamic videos via a Wavelet-Flow Variational Autoencoder (WF-VAE) and a diffusion transformer (DiT). Trained on an anonymized dataset, FFA Sora accurately simulates disease features from the input text, as confirmed by objective metrics: Frechet Video Distance (FVD) = 329.78, Learned Perceptual Image Patch Similarity (LPIPS) = 0.48, and Visual-question-answering Score (VQAScore) = 0.61. Specific evaluations showed acceptable alignment between the generated videos and textual prompts, with BERTScore of 0.35. Additionally, the model demonstrated strong privacy-preserving performance in retrieval evaluations, achieving an average Recall@K of 0.073. Human assessments indicated satisfactory visual quality, with an average score of 1.570(scale: 1 = best, 5 = worst). This model addresses privacy concerns associated with sharing large-scale FFA data and enhances medical education.
Beyond Graphs: Can Large Language Models Comprehend Hypergraphs?
Oct 14, 2024



Existing benchmarks like NLGraph and GraphQA evaluate LLMs on graphs by focusing mainly on pairwise relationships, overlooking the high-order correlations found in real-world data. Hypergraphs, which can model complex beyond-pairwise relationships, offer a more robust framework but are still underexplored in the context of LLMs. To address this gap, we introduce LLM4Hypergraph, the first comprehensive benchmark comprising 21,500 problems across eight low-order, five high-order, and two isomorphism tasks, utilizing both synthetic and real-world hypergraphs from citation networks and protein structures. We evaluate six prominent LLMs, including GPT-4o, demonstrating our benchmark's effectiveness in identifying model strengths and weaknesses. Our specialized prompting framework incorporates seven hypergraph languages and introduces two novel techniques, Hyper-BAG and Hyper-COT, which enhance high-order reasoning and achieve an average 4% (up to 9%) performance improvement on structure classification tasks. This work establishes a foundational testbed for integrating hypergraph computational capabilities into LLMs, advancing their comprehension.
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
Aug 09, 2024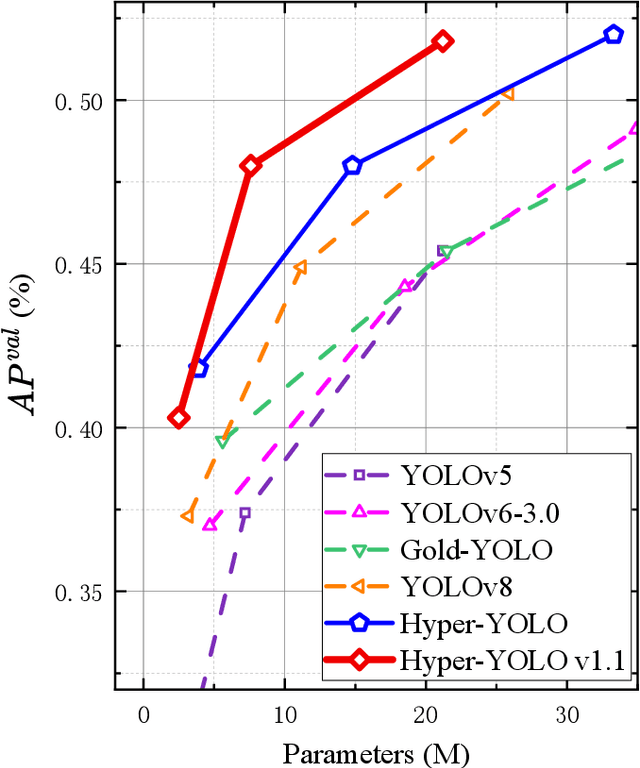
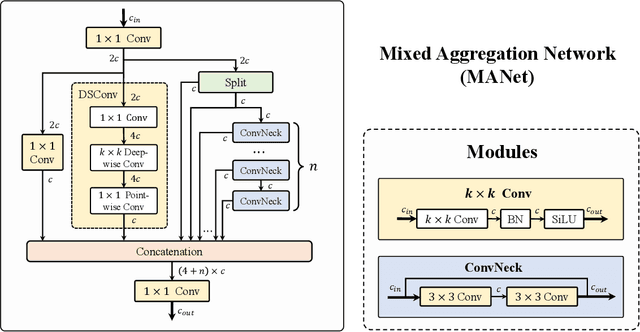
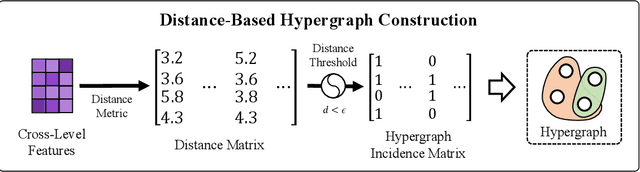
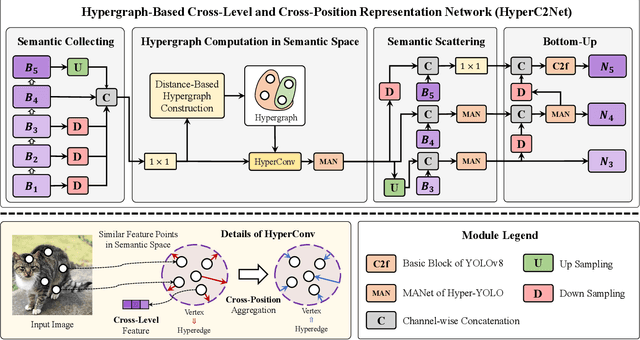
We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-of-the-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, Hyper-YOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12\% $\text{AP}^{val}$ and 9\% $\text{AP}^{val}$ improvements. The source codes are at ttps://github.com/iMoonLab/Hyper-YOLO.
LightHGNN: Distilling Hypergraph Neural Networks into MLPs for $100\times$ Faster Inference
Feb 18, 2024



Hypergraph Neural Networks (HGNNs) have recently attracted much attention and exhibited satisfactory performance due to their superiority in high-order correlation modeling. However, it is noticed that the high-order modeling capability of hypergraph also brings increased computation complexity, which hinders its practical industrial deployment. In practice, we find that one key barrier to the efficient deployment of HGNNs is the high-order structural dependencies during inference. In this paper, we propose to bridge the gap between the HGNNs and inference-efficient Multi-Layer Perceptron (MLPs) to eliminate the hypergraph dependency of HGNNs and thus reduce computational complexity as well as improve inference speed. Specifically, we introduce LightHGNN and LightHGNN$^+$ for fast inference with low complexity. LightHGNN directly distills the knowledge from teacher HGNNs to student MLPs via soft labels, and LightHGNN$^+$ further explicitly injects reliable high-order correlations into the student MLPs to achieve topology-aware distillation and resistance to over-smoothing. Experiments on eight hypergraph datasets demonstrate that even without hypergraph dependency, the proposed LightHGNNs can still achieve competitive or even better performance than HGNNs and outperform vanilla MLPs by $16.3$ on average. Extensive experiments on three graph datasets further show the average best performance of our LightHGNNs compared with all other methods. Experiments on synthetic hypergraphs with 5.5w vertices indicate LightHGNNs can run $100\times$ faster than HGNNs, showcasing their ability for latency-sensitive deployments.
Hypergraph Isomorphism Computation
Jul 26, 2023



The isomorphism problem is a fundamental problem in network analysis, which involves capturing both low-order and high-order structural information. In terms of extracting low-order structural information, graph isomorphism algorithms analyze the structural equivalence to reduce the solver space dimension, which demonstrates its power in many applications, such as protein design, chemical pathways, and community detection. For the more commonly occurring high-order relationships in real-life scenarios, the problem of hypergraph isomorphism, which effectively captures these high-order structural relationships, cannot be straightforwardly addressed using graph isomorphism methods. Besides, the existing hypergraph kernel methods may suffer from high memory consumption or inaccurate sub-structure identification, thus yielding sub-optimal performance. In this paper, to address the abovementioned problems, we first propose the hypergraph Weisfiler-Lehman test algorithm for the hypergraph isomorphism test problem by generalizing the Weisfiler-Lehman test algorithm from graphs to hypergraphs. Secondly, based on the presented algorithm, we propose a general hypergraph Weisfieler-Lehman kernel framework and implement two instances, which are Hypergraph Weisfeiler-Lehamn Subtree Kernel and Hypergraph Weisfeiler-Lehamn Hyperedge Kernel. In order to fulfill our research objectives, a comprehensive set of experiments was meticulously designed, including seven graph classification datasets and 12 hypergraph classification datasets. Results on hypergraph classification datasets show significant improvements compared to other typical kernel-based methods, which demonstrates the effectiveness of the proposed methods. In our evaluation, we found that our proposed methods outperform the second-best method in terms of runtime, running over 80 times faster when handling complex hypergraph structures.
Nested Elimination: A Simple Algorithm for Best-Item Identification from Choice-Based Feedback
Jul 13, 2023



We study the problem of best-item identification from choice-based feedback. In this problem, a company sequentially and adaptively shows display sets to a population of customers and collects their choices. The objective is to identify the most preferred item with the least number of samples and at a high confidence level. We propose an elimination-based algorithm, namely Nested Elimination (NE), which is inspired by the nested structure implied by the information-theoretic lower bound. NE is simple in structure, easy to implement, and has a strong theoretical guarantee for sample complexity. Specifically, NE utilizes an innovative elimination criterion and circumvents the need to solve any complex combinatorial optimization problem. We provide an instance-specific and non-asymptotic bound on the expected sample complexity of NE. We also show NE achieves high-order worst-case asymptotic optimality. Finally, numerical experiments from both synthetic and real data corroborate our theoretical findings.
Intelligent wayfinding vehicle design based on visual recognition
Sep 21, 2022Intelligent drug delivery trolley is an advanced intelligent drug delivery equipment. Compared with traditional manual drug delivery, it has higher drug delivery efficiency and lower error rate. In this project, an intelligent drug delivery car is designed and manufactured, which can recognize the road route and the room number of the target ward through visual recognition technology. The trolley selects the corresponding route according to the identified room number, accurately transports the drugs to the target ward, and can return to the pharmacy after the drugs are delivered. The intelligent drug delivery car uses DC power supply, and the motor drive module controls two DC motors, which overcomes the problem of excessive deviation of turning angle. The trolley line inspection function uses closed-loop control to improve the accuracy of line inspection and the controllability of trolley speed. The identification of ward number is completed by the camera module with microcontroller, and has the functions of adaptive adjustment of ambient brightness, distortion correction, automatic calibration and so on. The communication between two cooperative drug delivery vehicles is realized by Bluetooth module, which achieves efficient and accurate communication and interaction. Experiments show that the intelligent drug delivery car can accurately identify the room number and plan the route to deliver drugs to the far, middle and near wards, and has the characteristics of fast speed and accurate judgment. In addition, two drug delivery trolleys can cooperate to deliver drugs to the same ward, with high efficiency and high cooperation.