 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025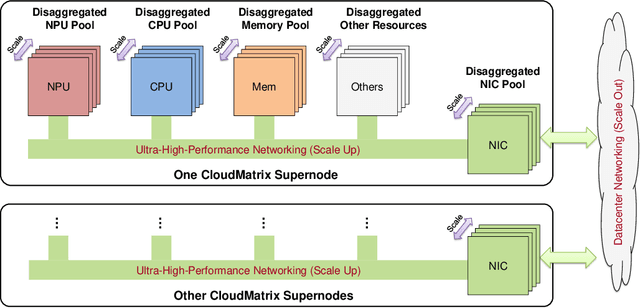
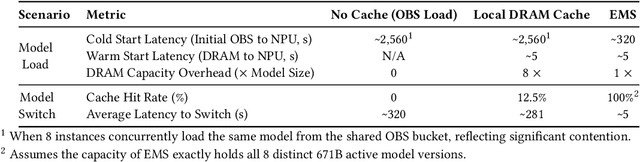
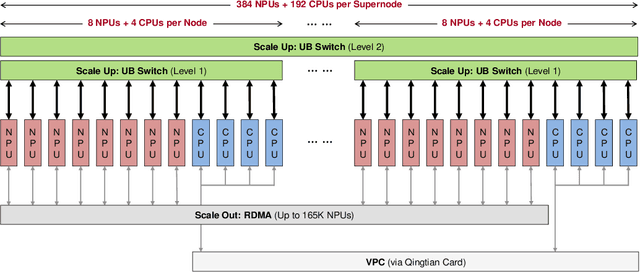
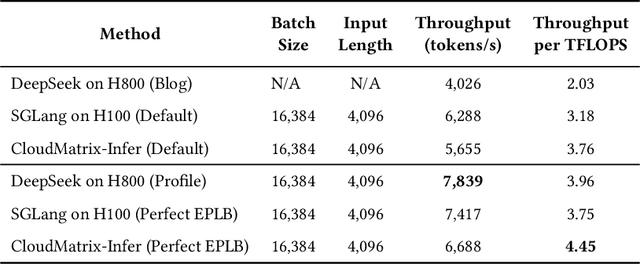
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Hyper-YOLO: When Visual Object Detection Meets Hypergraph Computation
Aug 09, 2024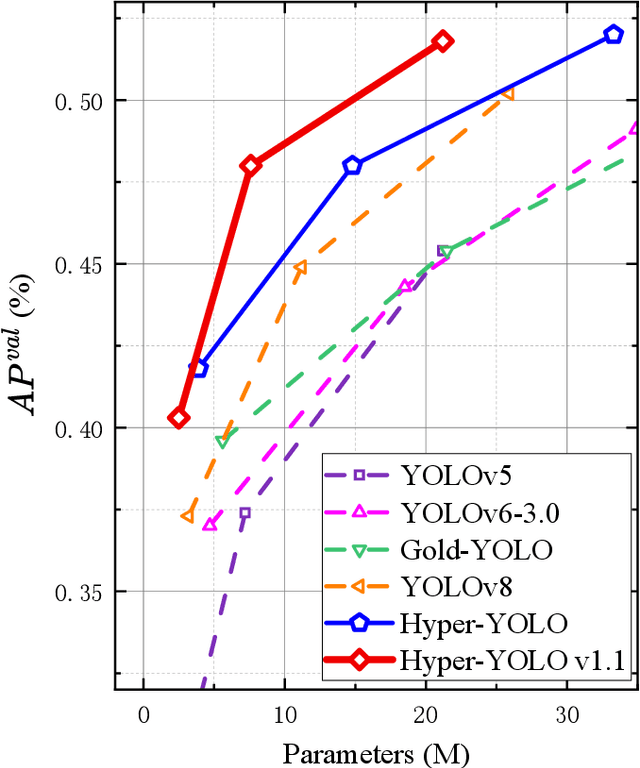
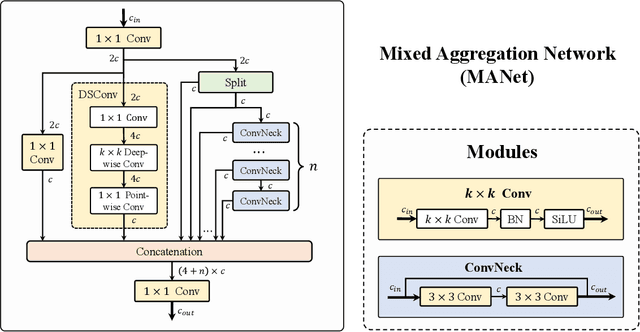
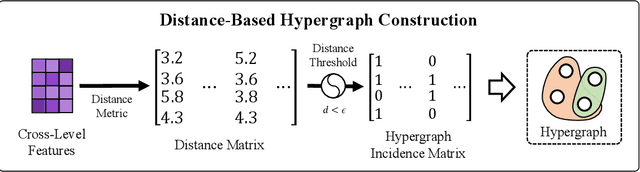
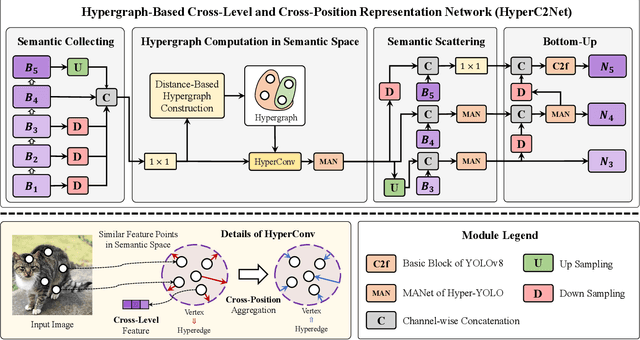
We introduce Hyper-YOLO, a new object detection method that integrates hypergraph computations to capture the complex high-order correlations among visual features. Traditional YOLO models, while powerful, have limitations in their neck designs that restrict the integration of cross-level features and the exploitation of high-order feature interrelationships. To address these challenges, we propose the Hypergraph Computation Empowered Semantic Collecting and Scattering (HGC-SCS) framework, which transposes visual feature maps into a semantic space and constructs a hypergraph for high-order message propagation. This enables the model to acquire both semantic and structural information, advancing beyond conventional feature-focused learning. Hyper-YOLO incorporates the proposed Mixed Aggregation Network (MANet) in its backbone for enhanced feature extraction and introduces the Hypergraph-Based Cross-Level and Cross-Position Representation Network (HyperC2Net) in its neck. HyperC2Net operates across five scales and breaks free from traditional grid structures, allowing for sophisticated high-order interactions across levels and positions. This synergy of components positions Hyper-YOLO as a state-of-the-art architecture in various scale models, as evidenced by its superior performance on the COCO dataset. Specifically, Hyper-YOLO-N significantly outperforms the advanced YOLOv8-N and YOLOv9-T with 12\% $\text{AP}^{val}$ and 9\% $\text{AP}^{val}$ improvements. The source codes are at ttps://github.com/iMoonLab/Hyper-YOLO.
Sharp Bounds for Sequential Federated Learning on Heterogeneous Data
May 02, 2024There are two paradigms in Federated Learning (FL): parallel FL (PFL), where models are trained in a parallel manner across clients; and sequential FL (SFL), where models are trained in a sequential manner across clients. In contrast to that of PFL, the convergence theory of SFL on heterogeneous data is still lacking. To resolve the theoretical dilemma of SFL, we establish sharp convergence guarantees for SFL on heterogeneous data with both upper and lower bounds. Specifically, we derive the upper bounds for strongly convex, general convex and non-convex objective functions, and construct the matching lower bounds for the strongly convex and general convex objective functions. Then, we compare the upper bounds of SFL with those of PFL, showing that SFL outperforms PFL (at least, when the level of heterogeneity is relatively high). Experimental results on quadratic functions and real data sets validate the counterintuitive comparison result.
Hypergraph-based Multi-View Action Recognition using Event Cameras
Mar 28, 2024Action recognition from video data forms a cornerstone with wide-ranging applications. Single-view action recognition faces limitations due to its reliance on a single viewpoint. In contrast, multi-view approaches capture complementary information from various viewpoints for improved accuracy. Recently, event cameras have emerged as innovative bio-inspired sensors, leading to advancements in event-based action recognition. However, existing works predominantly focus on single-view scenarios, leaving a gap in multi-view event data exploitation, particularly in challenges like information deficit and semantic misalignment. To bridge this gap, we introduce HyperMV, a multi-view event-based action recognition framework. HyperMV converts discrete event data into frame-like representations and extracts view-related features using a shared convolutional network. By treating segments as vertices and constructing hyperedges using rule-based and KNN-based strategies, a multi-view hypergraph neural network that captures relationships across viewpoint and temporal features is established. The vertex attention hypergraph propagation is also introduced for enhanced feature fusion. To prompt research in this area, we present the largest multi-view event-based action dataset $\text{THU}^{\text{MV-EACT}}\text{-50}$, comprising 50 actions from 6 viewpoints, which surpasses existing datasets by over tenfold. Experimental results show that HyperMV significantly outperforms baselines in both cross-subject and cross-view scenarios, and also exceeds the state-of-the-arts in frame-based multi-view action recognition.
Convergence Analysis of Sequential Federated Learning on Heterogeneous Data
Nov 06, 2023There are two categories of methods in Federated Learning (FL) for joint training across multiple clients: i) parallel FL (PFL), where clients train models in a parallel manner; and ii) sequential FL (SFL), where clients train models in a sequential manner. In contrast to that of PFL, the convergence theory of SFL on heterogeneous data is still lacking. In this paper, we establish the convergence guarantees of SFL for strongly/general/non-convex objectives on heterogeneous data. The convergence guarantees of SFL are better than that of PFL on heterogeneous data with both full and partial client participation. Experimental results validate the counterintuitive analysis result that SFL outperforms PFL on extremely heterogeneous data in cross-device settings.
Convergence Analysis of Split Learning on Non-IID Data
Feb 03, 2023Split Learning (SL) is one promising variant of Federated Learning (FL), where the AI model is split and trained at the clients and the server collaboratively. By offloading the computation-intensive portions to the server, SL enables efficient model training on resource-constrained clients. Despite its booming applications, SL still lacks rigorous convergence analysis on non-IID data, which is critical for hyperparameter selection. In this paper, we first prove that SL exhibits an $\mathcal{O}(1/\sqrt{R})$ convergence rate for non-convex objectives on non-IID data, where $R$ is the number of total training rounds. The derived convergence results can facilitate understanding the effect of some crucial factors in SL (e.g., data heterogeneity and synchronization interval). Furthermore, comparing with the convergence result of FL, we show that the guarantee of SL is worse than FL in terms of training rounds on non-IID data. The experimental results verify our theory. More findings on the comparison between FL and SL in cross-device settings are also reported.
DeepCloth: Neural Garment Representation for Shape and Style Editing
Nov 30, 2020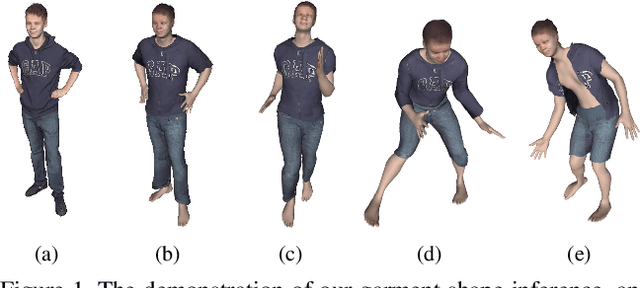
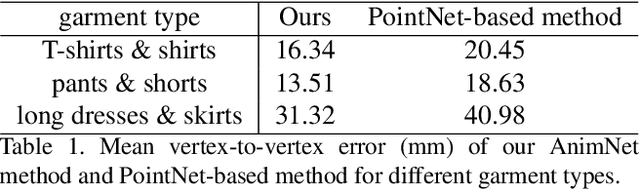
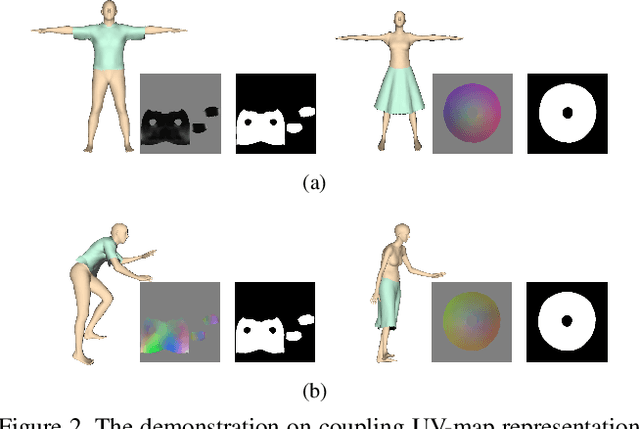
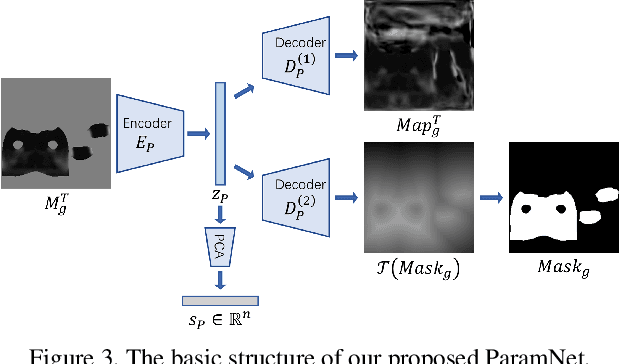
Garment representation, animation and editing is a challenging topic in the area of computer vision and graphics. Existing methods cannot perform smooth and reasonable garment transition under different shape styles and topologies. In this work, we introduce a novel method, termed as DeepCloth, to establish a unified garment representation framework enabling free and smooth garment style transition. Our key idea is to represent garment geometry by a "UV-position map with mask", which potentially allows the description of various garments with different shapes and topologies. Furthermore, we learn a continuous feature space mapped from the above UV space, enabling garment shape editing and transition by controlling the garment features. Finally, we demonstrate applications of garment animation, reconstruction and editing based on our neural garment representation and encoding method. To conclude, with the proposed DeepCloth, we move a step forward on establishing a more flexible and general 3D garment digitization framework. Experiments demonstrate that our method can achieve the state-of-the-art garment modeling results compared with the previous methods.
Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit
Aug 26, 2020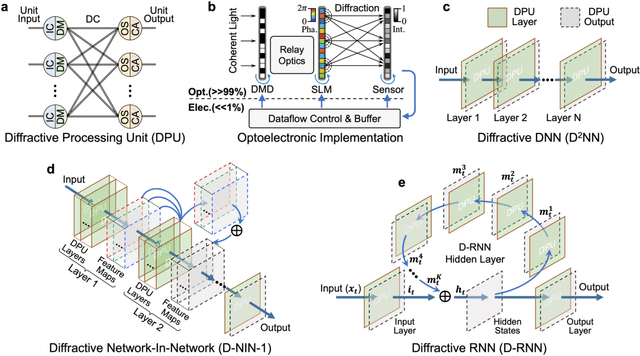
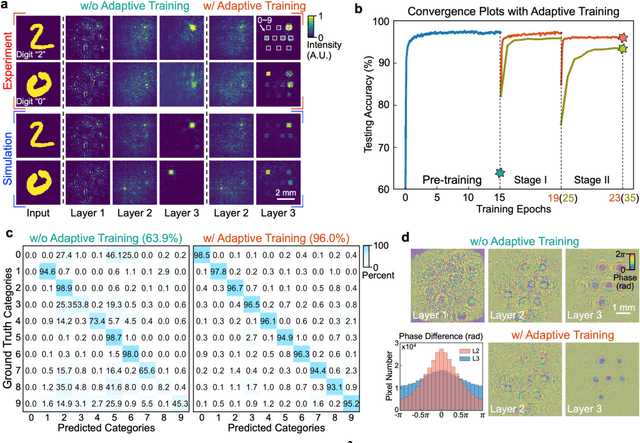
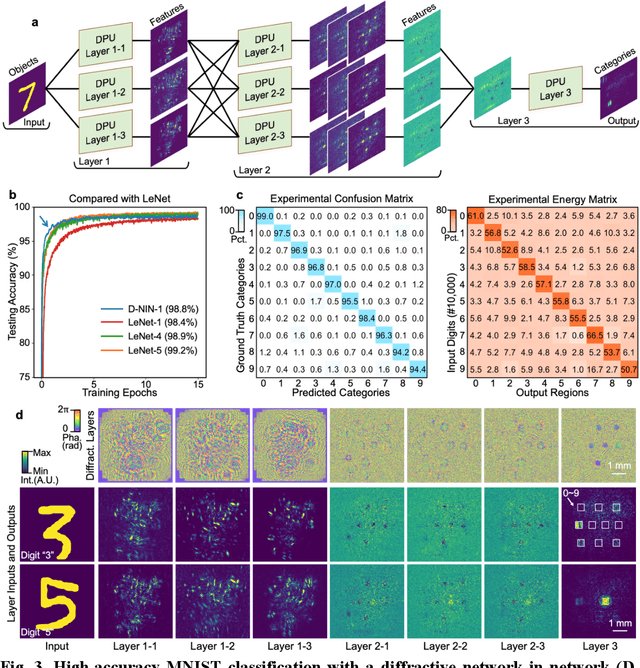
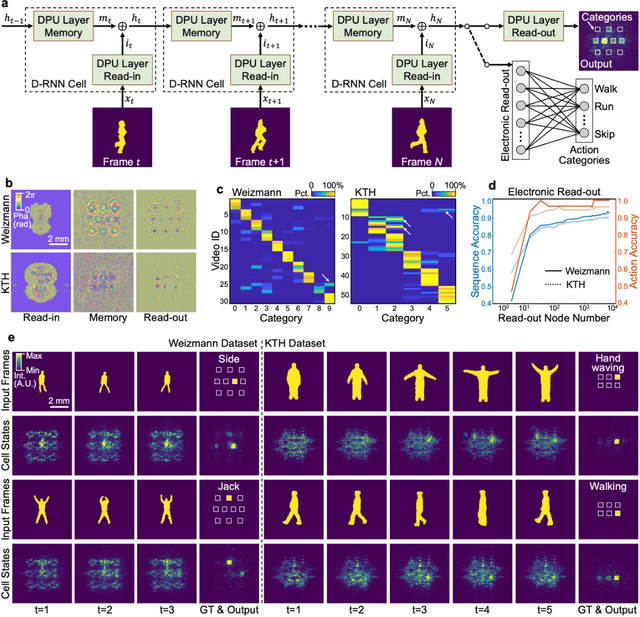
Application-specific optical processors have been considered disruptive technologies for modern computing that can fundamentally accelerate the development of artificial intelligence (AI) by offering substantially improved computing performance. Recent advancements in optical neural network architectures for neural information processing have been applied to perform various machine learning tasks. However, the existing architectures have limited complexity and performance; and each of them requires its own dedicated design that cannot be reconfigured to switch between different neural network models for different applications after deployment. Here, we propose an optoelectronic reconfigurable computing paradigm by constructing a diffractive processing unit (DPU) that can efficiently support different neural networks and achieve a high model complexity with millions of neurons. It allocates almost all of its computational operations optically and achieves extremely high speed of data modulation and large-scale network parameter updating by dynamically programming optical modulators and photodetectors. We demonstrated the reconfiguration of the DPU to implement various diffractive feedforward and recurrent neural networks and developed a novel adaptive training approach to circumvent the system imperfections. We applied the trained networks for high-speed classifying of handwritten digit images and human action videos over benchmark datasets, and the experimental results revealed a comparable classification accuracy to the electronic computing approaches. Furthermore, our prototype system built with off-the-shelf optoelectronic components surpasses the performance of state-of-the-art graphics processing units (GPUs) by several times on computing speed and more than an order of magnitude on system energy efficiency.
Attention-based Multi-modal Fusion Network for Semantic Scene Completion
Apr 16, 2020
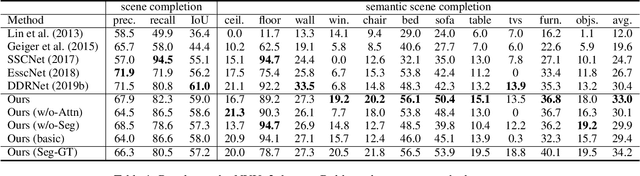
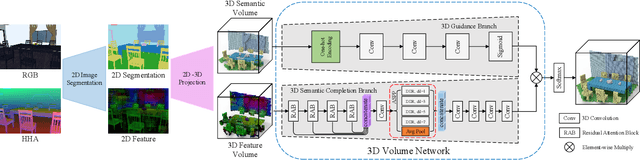
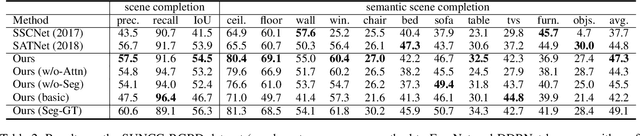
This paper presents an end-to-end 3D convolutional network named attention-based multi-modal fusion network (AMFNet) for the semantic scene completion (SSC) task of inferring the occupancy and semantic labels of a volumetric 3D scene from single-view RGB-D images. Compared with previous methods which use only the semantic features extracted from RGB-D images, the proposed AMFNet learns to perform effective 3D scene completion and semantic segmentation simultaneously via leveraging the experience of inferring 2D semantic segmentation from RGB-D images as well as the reliable depth cues in spatial dimension. It is achieved by employing a multi-modal fusion architecture boosted from 2D semantic segmentation and a 3D semantic completion network empowered by residual attention blocks. We validate our method on both the synthetic SUNCG-RGBD dataset and the real NYUv2 dataset and the results show that our method respectively achieves the gains of 2.5% and 2.6% on the synthetic SUNCG-RGBD dataset and the real NYUv2 dataset against the state-of-the-art method.