 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit
Aug 26, 2020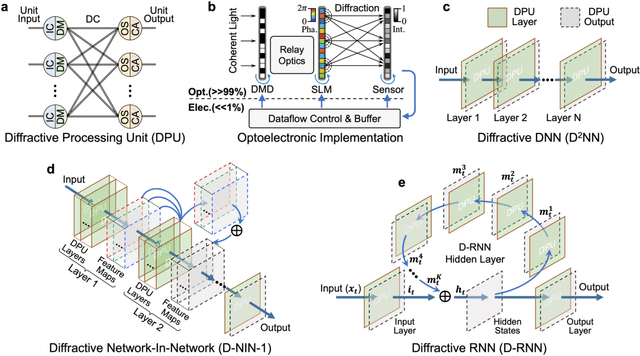
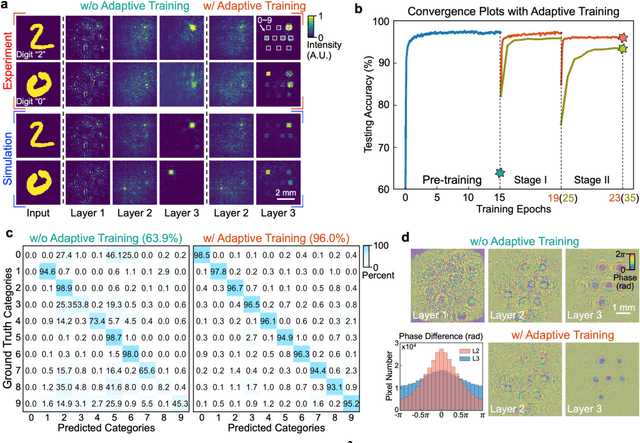
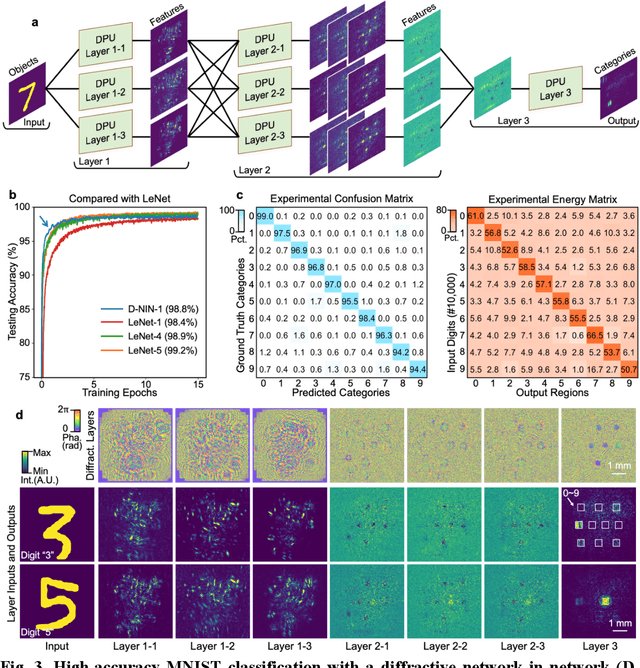
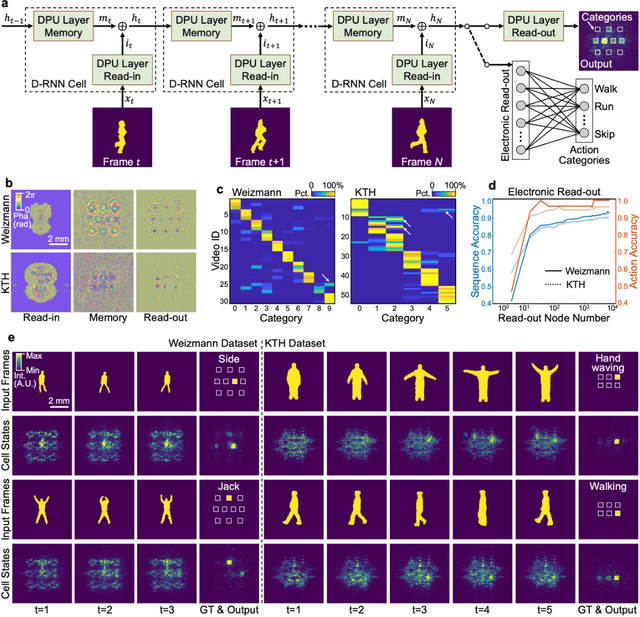
Application-specific optical processors have been considered disruptive technologies for modern computing that can fundamentally accelerate the development of artificial intelligence (AI) by offering substantially improved computing performance. Recent advancements in optical neural network architectures for neural information processing have been applied to perform various machine learning tasks. However, the existing architectures have limited complexity and performance; and each of them requires its own dedicated design that cannot be reconfigured to switch between different neural network models for different applications after deployment. Here, we propose an optoelectronic reconfigurable computing paradigm by constructing a diffractive processing unit (DPU) that can efficiently support different neural networks and achieve a high model complexity with millions of neurons. It allocates almost all of its computational operations optically and achieves extremely high speed of data modulation and large-scale network parameter updating by dynamically programming optical modulators and photodetectors. We demonstrated the reconfiguration of the DPU to implement various diffractive feedforward and recurrent neural networks and developed a novel adaptive training approach to circumvent the system imperfections. We applied the trained networks for high-speed classifying of handwritten digit images and human action videos over benchmark datasets, and the experimental results revealed a comparable classification accuracy to the electronic computing approaches. Furthermore, our prototype system built with off-the-shelf optoelectronic components surpasses the performance of state-of-the-art graphics processing units (GPUs) by several times on computing speed and more than an order of magnitude on system energy efficiency.
Semi-Supervised First-Person Activity Recognition in Body-Worn Video
Apr 19, 2019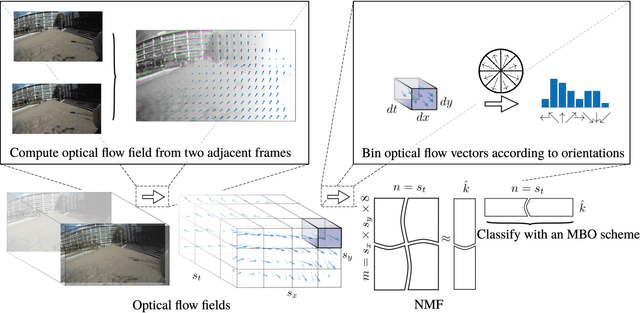
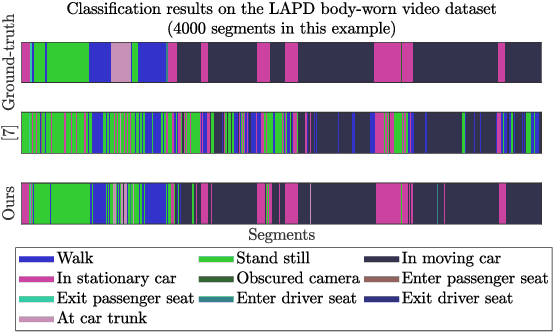
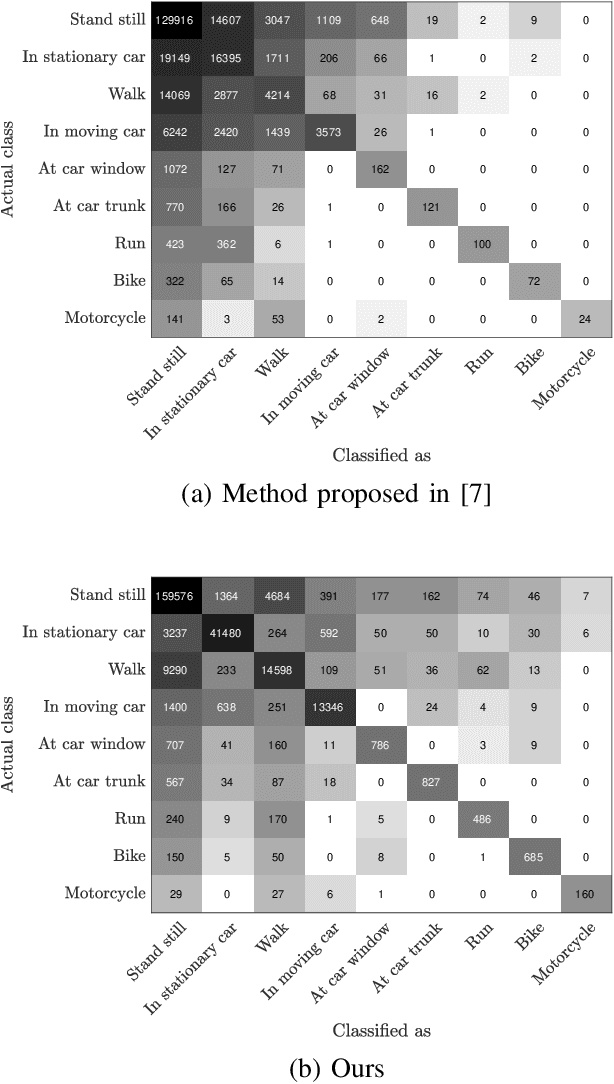
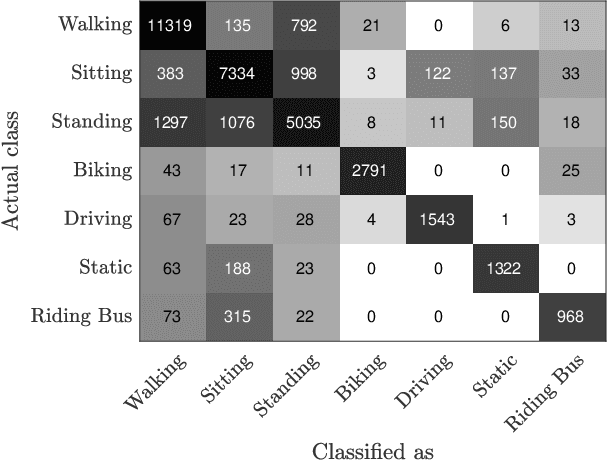
Body-worn cameras are now commonly used for logging daily life, sports, and law enforcement activities, creating a large volume of archived footage. This paper studies the problem of classifying frames of footage according to the activity of the camera-wearer with an emphasis on application to real-world police body-worn video. Real-world datasets pose a different set of challenges from existing egocentric vision datasets: the amount of footage of different activities is unbalanced, the data contains personally identifiable information, and in practice it is difficult to provide substantial training footage for a supervised approach. We address these challenges by extracting features based exclusively on motion information then segmenting the video footage using a semi-supervised classification algorithm. On publicly available datasets, our method achieves results comparable to, if not better than, supervised and/or deep learning methods using a fraction of the training data. It also shows promising results on real-world police body-worn video.
Sequential Gating Ensemble Network for Noise Robust Multi-Scale Face Restoration
Dec 19, 2018



Face restoration from low resolution and noise is important for applications of face analysis recognition. However, most existing face restoration models omit the multiple scale issues in face restoration problem, which is still not well-solved in research area. In this paper, we propose a Sequential Gating Ensemble Network (SGEN) for multi-scale noise robust face restoration issue. To endow the network with multi-scale representation ability, we first employ the principle of ensemble learning for SGEN network architecture designing. The SGEN aggregates multi-level base-encoders and base-decoders into the network, which enables the network to contain multiple scales of receptive field. Instead of combining these base-en/decoders directly with non-sequential operations, the SGEN takes base-en/decoders from different levels as sequential data. Specifically, it is visualized that SGEN learns to sequentially extract high level information from base-encoders in bottom-up manner and restore low level information from base-decoders in top-down manner. Besides, we propose to realize bottom-up and top-down information combination and selection with Sequential Gating Unit (SGU). The SGU sequentially takes information from two different levels as inputs and decides the output based on one active input. Experiment results on benchmark dataset demonstrate that our SGEN is more effective at multi-scale human face restoration with more image details and less noise than state-of-the-art image restoration models. Further utilizing adversarial training scheme, SGEN also produces more visually preferred results than other models under subjective evaluation.
DeepIR: A Deep Semantics Driven Framework for Image Retargeting
Nov 19, 2018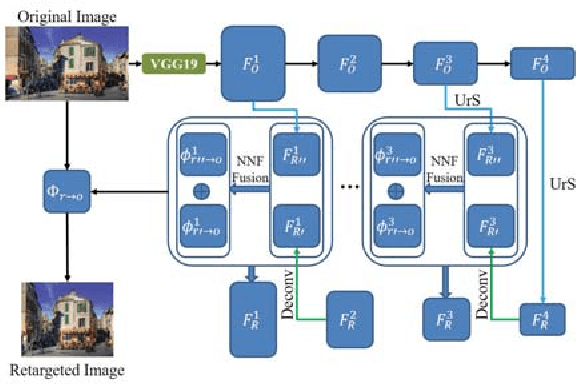
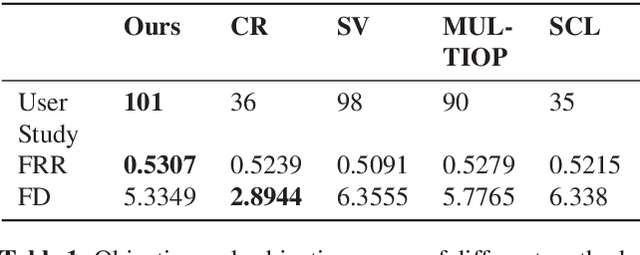
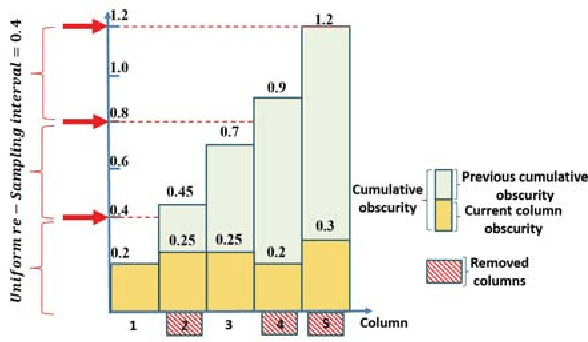

We present \emph{Deep Image Retargeting} (\emph{DeepIR}), a coarse-to-fine framework for content-aware image retargeting. Our framework first constructs the semantic structure of input image with a deep convolutional neural network. Then a uniform re-sampling that suits for semantic structure preserving is devised to resize feature maps to target aspect ratio at each feature layer. The final retargeting result is generated by coarse-to-fine nearest neighbor field search and step-by-step nearest neighbor field fusion. We empirically demonstrate the effectiveness of our model with both qualitative and quantitative results on widely used RetargetMe dataset.
Multi-Scale Face Restoration with Sequential Gating Ensemble Network
May 06, 2018

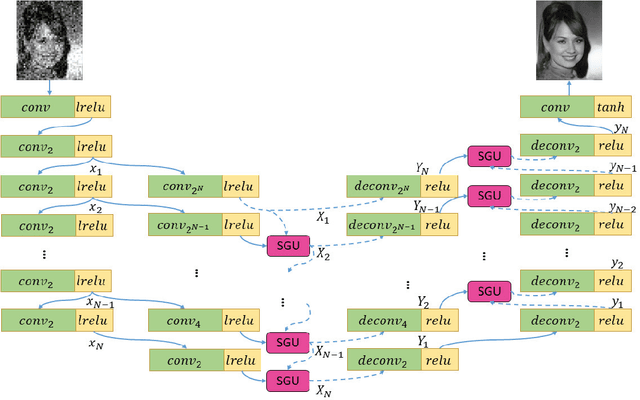
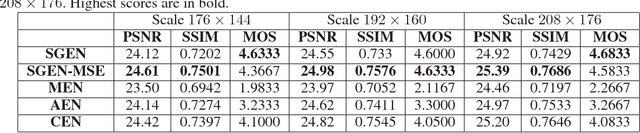
Restoring face images from distortions is important in face recognition applications and is challenged by multiple scale issues, which is still not well-solved in research area. In this paper, we present a Sequential Gating Ensemble Network (SGEN) for multi-scale face restoration issue. We first employ the principle of ensemble learning into SGEN architecture design to reinforce predictive performance of the network. The SGEN aggregates multi-level base-encoders and base-decoders into the network, which enables the network to contain multiple scales of receptive field. Instead of combining these base-en/decoders directly with non-sequential operations, the SGEN takes base-en/decoders from different levels as sequential data. Specifically, the SGEN learns to sequentially extract high level information from base-encoders in bottom-up manner and restore low level information from base-decoders in top-down manner. Besides, we propose to realize bottom-up and top-down information combination and selection with Sequential Gating Unit (SGU). The SGU sequentially takes two inputs from different levels and decides the output based on one active input. Experiment results demonstrate that our SGEN is more effective at multi-scale human face restoration with more image details and less noise than state-of-the-art image restoration models. By using adversarial training, SGEN also produces more visually preferred results than other models through subjective evaluation.