 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining deep physical neural networks with local physical information bottleneck
Feb 10, 2026Deep learning has revolutionized modern society but faces growing energy and latency constraints. Deep physical neural networks (PNNs) are interconnected computing systems that directly exploit analog dynamics for energy-efficient, ultrafast AI execution. Realizing this potential, however, requires universal training methods tailored to physical intricacies. Here, we present the Physical Information Bottleneck (PIB), a general and efficient framework that integrates information theory and local learning, enabling deep PNNs to learn under arbitrary physical dynamics. By allocating matrix-based information bottlenecks to each unit, we demonstrate supervised, unsupervised, and reinforcement learning across electronic memristive chips and optical computing platforms. PIB also adapts to severe hardware faults and allows for parallel training via geographically distributed resources. Bypassing auxiliary digital models and contrastive measurements, PIB recasts PNN training as an intrinsic, scalable information-theoretic process compatible with diverse physical substrates.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024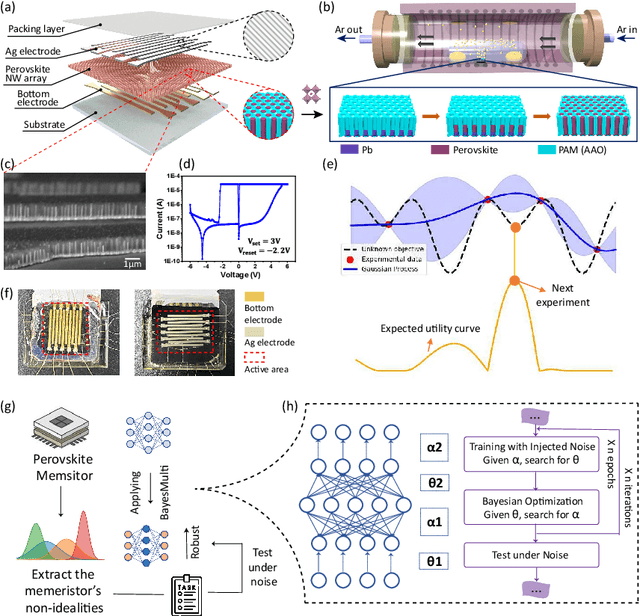

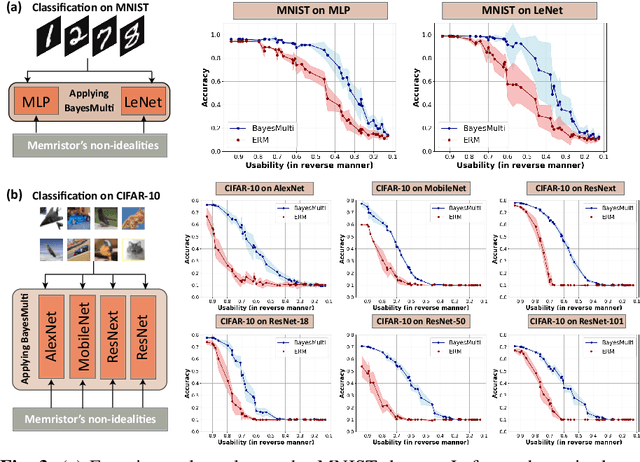
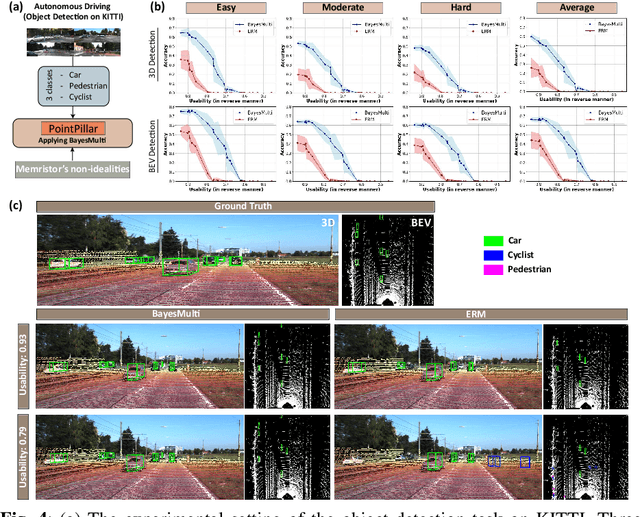
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.
Distributed Representations Enable Robust Multi-Timescale Computation in Neuromorphic Hardware
May 02, 2024



Programming recurrent spiking neural networks (RSNNs) to robustly perform multi-timescale computation remains a difficult challenge. To address this, we show how the distributed approach offered by vector symbolic architectures (VSAs), which uses high-dimensional random vectors as the smallest units of representation, can be leveraged to embed robust multi-timescale dynamics into attractor-based RSNNs. We embed finite state machines into the RSNN dynamics by superimposing a symmetric autoassociative weight matrix and asymmetric transition terms. The transition terms are formed by the VSA binding of an input and heteroassociative outer-products between states. Our approach is validated through simulations with highly non-ideal weights; an experimental closed-loop memristive hardware setup; and on Loihi 2, where it scales seamlessly to large state machines. This work demonstrates the effectiveness of VSA representations for embedding robust computation with recurrent dynamics into neuromorphic hardware, without requiring parameter fine-tuning or significant platform-specific optimisation. This advances VSAs as a high-level representation-invariant abstract language for cognitive algorithms in neuromorphic hardware.
Scaling Limits of Memristor-Based Routers for Asynchronous Neuromorphic Systems
Jul 16, 2023Multi-core neuromorphic systems typically use on-chip routers to transmit spikes among cores. These routers require significant memory resources and consume a large part of the overall system's energy budget. A promising alternative approach to using standard CMOS and SRAM-based routers is to exploit the features of memristive crossbar arrays and use them as programmable switch-matrices that route spikes. However, the scaling of these crossbar arrays presents physical challenges, such as `IR drop' on the metal lines due to the parasitic resistance, and leakage current accumulation on multiple active `off' memristors. While reliability challenges of this type have been extensively studied in synchronous systems for compute-in-memory matrix-vector multiplication (MVM) accelerators and storage class memory, little effort has been devoted so far to characterizing the scaling limits of memristor-based crossbar routers. In this paper, we study the challenges of memristive crossbar arrays, when used as routing channels to transmit spikes in asynchronous Spiking Neural Network (SNN) hardware. We validate our analytical findings with experimental results obtained from a 4K-ReRAM chip which demonstrate its functionality as a routing crossbar. We determine the functionality bounds on the routing due to the IR drop and leak problem, based both on experimental measurements, modeling and circuit simulations in a 22nm FDSOI technology. This work highlights the constraint of this approach and provides useful guidelines for engineering memristor properties in memristive crossbar routers for building multi-core asynchronous neuromorphic systems.
Edge AI without Compromise: Efficient, Versatile and Accurate Neurocomputing in Resistive Random-Access Memory
Aug 17, 2021
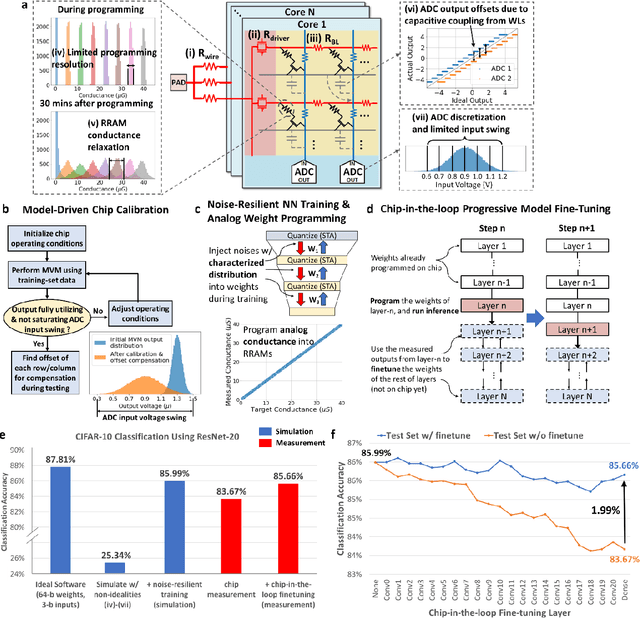
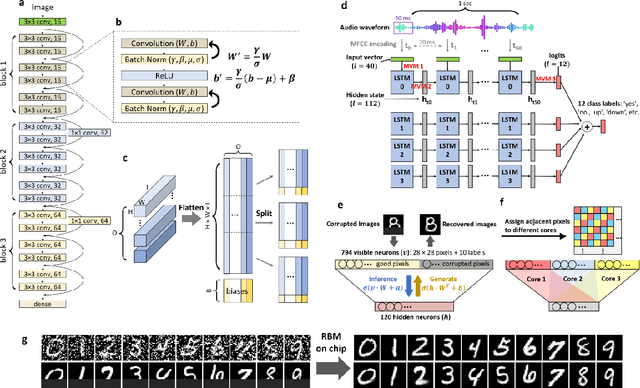
Realizing today's cloud-level artificial intelligence functionalities directly on devices distributed at the edge of the internet calls for edge hardware capable of processing multiple modalities of sensory data (e.g. video, audio) at unprecedented energy-efficiency. AI hardware architectures today cannot meet the demand due to a fundamental "memory wall": data movement between separate compute and memory units consumes large energy and incurs long latency. Resistive random-access memory (RRAM) based compute-in-memory (CIM) architectures promise to bring orders of magnitude energy-efficiency improvement by performing computation directly within memory. However, conventional approaches to CIM hardware design limit its functional flexibility necessary for processing diverse AI workloads, and must overcome hardware imperfections that degrade inference accuracy. Such trade-offs between efficiency, versatility and accuracy cannot be addressed by isolated improvements on any single level of the design. By co-optimizing across all hierarchies of the design from algorithms and architecture to circuits and devices, we present NeuRRAM - the first multimodal edge AI chip using RRAM CIM to simultaneously deliver a high degree of versatility for diverse model architectures, record energy-efficiency $5\times$ - $8\times$ better than prior art across various computational bit-precisions, and inference accuracy comparable to software models with 4-bit weights on all measured standard AI benchmarks including accuracy of 99.0% on MNIST and 85.7% on CIFAR-10 image classification, 84.7% accuracy on Google speech command recognition, and a 70% reduction in image reconstruction error on a Bayesian image recovery task. This work paves a way towards building highly efficient and reconfigurable edge AI hardware platforms for the more demanding and heterogeneous AI applications of the future.
Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit
Aug 26, 2020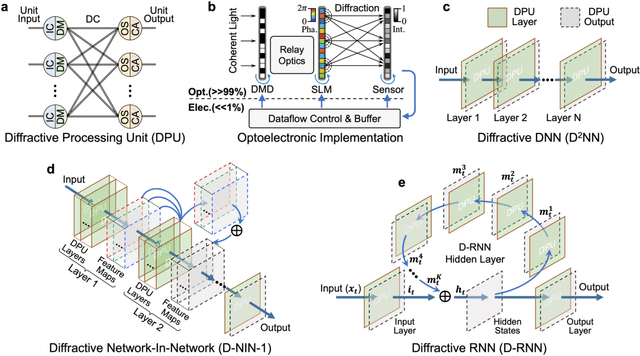
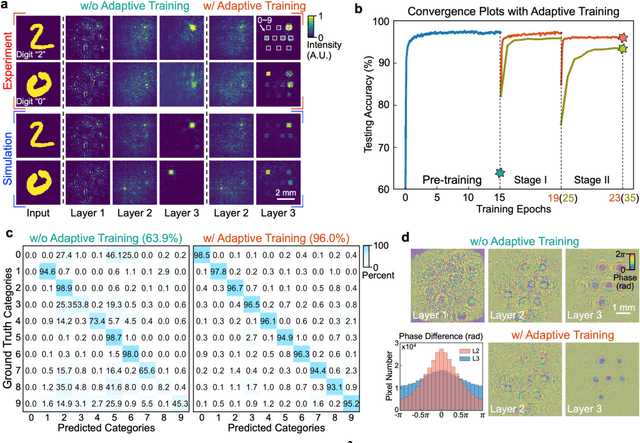
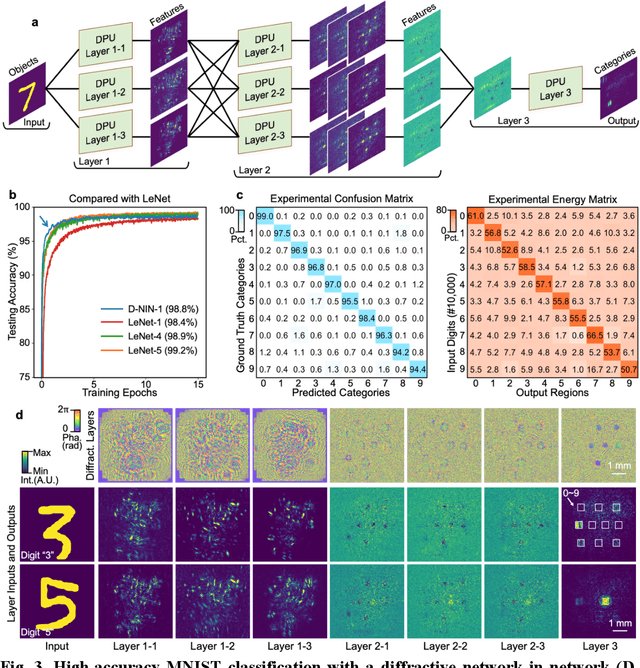
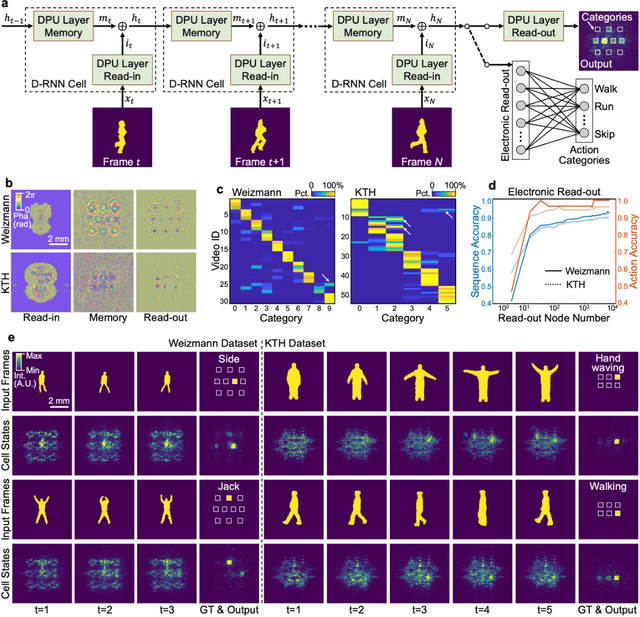
Application-specific optical processors have been considered disruptive technologies for modern computing that can fundamentally accelerate the development of artificial intelligence (AI) by offering substantially improved computing performance. Recent advancements in optical neural network architectures for neural information processing have been applied to perform various machine learning tasks. However, the existing architectures have limited complexity and performance; and each of them requires its own dedicated design that cannot be reconfigured to switch between different neural network models for different applications after deployment. Here, we propose an optoelectronic reconfigurable computing paradigm by constructing a diffractive processing unit (DPU) that can efficiently support different neural networks and achieve a high model complexity with millions of neurons. It allocates almost all of its computational operations optically and achieves extremely high speed of data modulation and large-scale network parameter updating by dynamically programming optical modulators and photodetectors. We demonstrated the reconfiguration of the DPU to implement various diffractive feedforward and recurrent neural networks and developed a novel adaptive training approach to circumvent the system imperfections. We applied the trained networks for high-speed classifying of handwritten digit images and human action videos over benchmark datasets, and the experimental results revealed a comparable classification accuracy to the electronic computing approaches. Furthermore, our prototype system built with off-the-shelf optoelectronic components surpasses the performance of state-of-the-art graphics processing units (GPUs) by several times on computing speed and more than an order of magnitude on system energy efficiency.